
Foresta casuale vs albero decisionale: differenza tra foresta casuale e albero decisionale
Pubblicato: 2020-12-30I recenti progressi hanno spianato la crescita di più algoritmi. Questi nuovi e strepitosi algoritmi hanno dato fuoco ai dati. Aiutano a gestire i dati e prendere decisioni con loro in modo efficace. Dal momento che il mondo ha a che fare con una baldoria su Internet. Quasi tutto è su Internet. Per gestire tali dati, abbiamo bisogno di algoritmi rigorosi per prendere decisioni e interpretazioni. Ora, in presenza di un ampio elenco di algoritmi, è un compito arduo scegliere il più adatto.
Gli algoritmi decisionali sono ampiamente utilizzati dalla maggior parte delle organizzazioni. Devono prendere decisioni banali e grandi ogni due ore. Dall'analisi del materiale da scegliere per ottenere aree lorde elevate, sta prendendo una decisione nel back-end. I recenti progressi di Python e ML hanno spinto la barra per la gestione dei dati. Pertanto, i dati sono presenti in grandi quantità. La soglia dipende dall'organizzazione. Esistono 2 principali algoritmi decisionali ampiamente utilizzati. Decision Tree e Random Forest- Suona familiare, giusto?
Alberi e foreste!
Esploriamo questo con un semplice esempio.
Supponiamo di dover acquistare un pacchetto di Rs. 10 biscotti dolci. Ora devi scegliere una tra le diverse marche di biscotti.
Scegli un algoritmo dell'albero decisionale. Ora controllerà le Rs. Confezione da 10, che è dolce. Sceglierà probabilmente i biscotti più venduti. Deciderai di andare per Rs. 10 biscotti al cioccolato. Tu sei felice!

Ma il tuo amico ha usato l'algoritmo della foresta casuale. Ora ha preso diverse decisioni. Inoltre, scegliendo la decisione a maggioranza. Sceglie tra vari gusti di fragola, vaniglia, mirtillo e arancia. Egli controlla che una particolare Rs. 10 pacchetti hanno servito 3 unità in più rispetto a quello originale. Era servito nel cioccolato alla vaniglia. Ha comprato quel biscotto al cioccolato alla vaniglia. È il più felice, mentre tu rimpiangi la tua decisione.
Partecipa al corso online di Machine Learning dalle migliori università del mondo: master, programmi post-laurea per dirigenti e programma di certificazione avanzato in ML e AI per accelerare la tua carriera.
Sommario
Qual è la differenza tra l'albero decisionale e la foresta casuale?
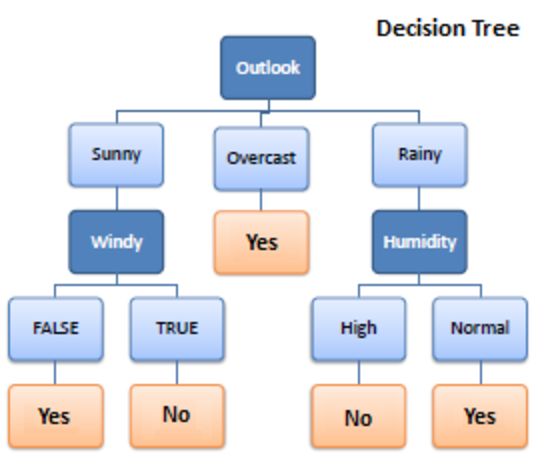
1. Albero decisionale
Fonte
Decision Tree è un algoritmo di apprendimento supervisionato utilizzato nell'apprendimento automatico. Funzionava sia in algoritmi di classificazione che di regressione. Come suggerisce il nome, è come un albero con i nodi. I rami dipendono dal numero di criteri. Divide i dati in rami come questi fino a raggiungere un'unità di soglia. Un albero decisionale ha nodi radice, nodi figli e nodi foglia.
La ricorsione viene utilizzata per attraversare i nodi. Non hai bisogno di nessun altro algoritmo. Gestisce i dati in modo accurato e funziona al meglio per uno schema lineare. Gestisce facilmente dati di grandi dimensioni e richiede meno tempo.
Come funziona?
1. Scissione
I dati, quando forniti all'albero decisionale, subiscono una suddivisione in varie categorie sotto rami.
Da leggere: Classificatore Naive Bayes: Spiegazione di vantaggi e svantaggi, applicazioni e tipi
2. Potatura
La potatura è inoltre la triturazione di quei rami. Funziona come una classificazione per sovvenzionare i dati in un modo migliore. Ad esempio, allo stesso modo in cui diciamo la potatura delle parti in eccesso, funziona allo stesso modo. Il nodo fogliare è raggiunto e la potatura termina. È una parte molto importante degli alberi decisionali.
3. Selezione degli alberi
Ora devi scegliere il miglior albero che può lavorare con i tuoi dati senza intoppi.
Ecco i fattori che devono essere considerati:
4. Entropia
Per verificare l'omogeneità degli alberi, è necessario dedurre l'entropia. Se l'entropia è zero, è omogenea; altrimenti no.
5. Guadagno di conoscenza
Una volta che l'entropia è diminuita, l'informazione viene acquisita. Queste informazioni aiutano a dividere ulteriormente i rami.
- Devi calcolare l'entropia.
- Suddividere i dati in base a criteri diversi
- Scegli le informazioni migliori.
La profondità dell'albero è un aspetto importante. La profondità ci informa del numero di decisioni da prendere prima di giungere a una conclusione. Gli alberi a bassa profondità funzionano meglio con gli algoritmi dell'albero decisionale.
Vantaggi e svantaggi dell'albero decisionale
Vantaggi
- Facile
- Processo trasparente
- Gestire dati sia numerici che categoriali
- Più grandi sono i dati, migliore è il risultato
- Velocità
Svantaggi
- Potrebbe essere troppo adatto
- Processo di potatura ampio
- Ottimizzazione non garantita
- Calcoli complessi
- Deflessione alta
Checkout: Spiegazione dei modelli di machine learning

2. Foresta casuale
Fonte
Viene utilizzato anche per l'apprendimento supervisionato, ma è molto potente. È molto usato. La differenza fondamentale è che non si basa su una decisione singolare. Raccoglie decisioni casuali basate su più decisioni e prende la decisione finale in base alla maggioranza.
Non cerca la migliore previsione. Invece, fa più previsioni casuali. Pertanto, viene associata una maggiore diversità e la previsione diventa molto più agevole.
Puoi dedurre che la foresta casuale sia una raccolta di più alberi decisionali!
Il bagging è il processo di creazione di foreste casuali mentre le decisioni funzionano in parallelo.
1. Insaccamento
- Prendi un set di dati di allenamento
- Crea un albero decisionale
- Ripetere il processo per un determinato periodo
- Ora prendi il voto maggiore. Quello che vince è la tua decisione da prendere.
2. Avvio automatico
Il bootstrapping consiste nella scelta casuale di campioni dai dati di addestramento. Questa è una procedura casuale.
Passo dopo passo
- Condizioni di scelta casuale
- Calcola il nodo radice
- Diviso
- Ripetere
- Ottieni una foresta
Leggi: Spiegazione di Naive Bayes
Vantaggi e svantaggi della foresta casuale
Vantaggi
- Potente e altamente preciso
- Non c'è bisogno di normalizzare
- Può gestire più funzioni contemporaneamente
- Esegui gli alberi in modo parallelo
Svantaggi
- A volte sono prevenuti per determinate caratteristiche
- Lento
- Non può essere utilizzato per metodi lineari
- Peggio per dati ad alta dimensione
Conclusione
Gli alberi decisionali sono molto facili rispetto alla foresta casuale. Un albero decisionale combina alcune decisioni, mentre una foresta casuale combina diversi alberi decisionali. Quindi, è un processo lungo, ma lento.
Considerando che un albero decisionale è veloce e opera facilmente su insiemi di dati di grandi dimensioni, in particolare quello lineare. Il modello di foresta casuale necessita di una formazione rigorosa. Quando stai cercando di creare un progetto, potresti aver bisogno di più di un modello. Quindi, un gran numero di foreste casuali, più tempo.
Dipende dalle tue esigenze. Se hai meno tempo per lavorare su un modello, sei obbligato a scegliere un albero decisionale. Tuttavia, stabilità e previsioni affidabili sono nel paniere delle foreste casuali.
Se hai la passione e vuoi saperne di più sull'intelligenza artificiale, puoi prendere il diploma PG di IIIT-B e upGrad in Machine Learning e Deep Learning che offre oltre 400 ore di apprendimento, sessioni pratiche, assistenza sul lavoro e molto altro.
In che modo la foresta casuale è diversa da un normale albero decisionale?
Nell'apprendimento automatico, un albero decisionale è una tecnica di apprendimento supervisionato. È in grado di lavorare sia con tecniche di classificazione che di regressione. Assomiglia a un albero con nodi, come suggerisce il nome. La quantità di criteri determina i rami. Divide i dati in questi rami fino a raggiungere un'unità di soglia. Ci sono nodi radice, nodi figlio e nodi foglia in un albero decisionale. La foresta casuale viene utilizzata anche per l'apprendimento supervisionato, sebbene abbia molto potere. È abbastanza popolare. La principale distinzione è che non si basa su un'unica decisione. Raccoglie decisioni casuali basate su molte decisioni e quindi crea una decisione finale a seconda della maggioranza.
Quali sono i principali vantaggi dell'utilizzo di una foresta casuale rispetto a un singolo albero decisionale?
In un mondo ideale, vorremmo ridurre sia gli errori legati alla distorsione che quelli legati alla varianza. Questo problema è ben affrontato da foreste casuali. Una foresta casuale non è altro che una serie di alberi decisionali con le loro scoperte combinate in un unico risultato finale. Sono così potenti grazie alla loro capacità di ridurre l'overfitting senza aumentare enormemente l'errore dovuto alla distorsione. Le foreste casuali, d'altra parte, sono un potente strumento di modellazione che è molto più resiliente di un singolo albero decisionale. Combinano numerosi alberi decisionali per ridurre l'overfitting e l'imprecisione correlata ai bias, e quindi producono risultati utilizzabili.
Qual è una limitazione degli alberi decisionali?
Uno degli svantaggi degli alberi decisionali è che sono molto instabili rispetto ad altri predittori di scelta. Una leggera modifica dei dati potrebbe causare un cambiamento significativo nella struttura dell'albero decisionale, determinando un risultato diverso da quello che i consumatori si aspetterebbero in un evento tipico. Inoltre, quando lo scopo principale è prevedere il risultato di una variabile continua, gli alberi decisionali sono meno utili per fare previsioni.