
随机森林与决策树:随机森林与决策树的区别
已发表: 2020-12-30最近的进步为多种算法的发展铺平了道路。 这些新的和惊人的算法已经让数据着火了。 它们有助于有效地处理数据并做出决策。 由于世界正在处理互联网热潮。 几乎所有东西都在互联网上。 为了处理这些数据,我们需要严格的算法来做出决策和解释。 现在,在存在大量算法的情况下,选择最适合的算法是一项艰巨的任务。
大多数组织都广泛使用决策算法。 他们必须每隔一小时就做出一些琐碎和重大的决定。 通过分析选择哪种材料来获得高总面积,后端正在做出决定。 最近 python 和 ML 的进步推动了处理数据的标准。 因此,数据大量存在。 阈值取决于组织。 有两种广泛使用的主要决策算法。 决策树和随机森林 - 听起来很熟悉,对吧?
树木和森林!
让我们用一个简单的例子来探讨一下。
假设您必须购买一包卢比。 10块甜饼干。 现在,您必须从几个饼干品牌中选择一个。
你选择一个决策树算法。 现在,它将检查卢比。 10包,很甜。 它可能会选择最畅销的饼干。 您将决定购买卢比。 10块巧克力饼干。 你很快乐!

但是你的朋友使用了随机森林算法。 现在,他已经做出了几个决定。 此外,选择多数决定。 他选择了各种草莓、香草、蓝莓和橙子口味。 他检查了一个特定的卢比。 10 包比原来的多送达 3 个单位。 它是在香草巧克力中供应的。 他买了那个香草巧克力饼干。 他是最快乐的,而你却为你的决定感到后悔。
加入来自世界顶级大学的机器学习在线课程——硕士、高管研究生课程和 ML 和 AI 高级证书课程,以加快您的职业生涯。
目录
决策树和随机森林有什么区别?
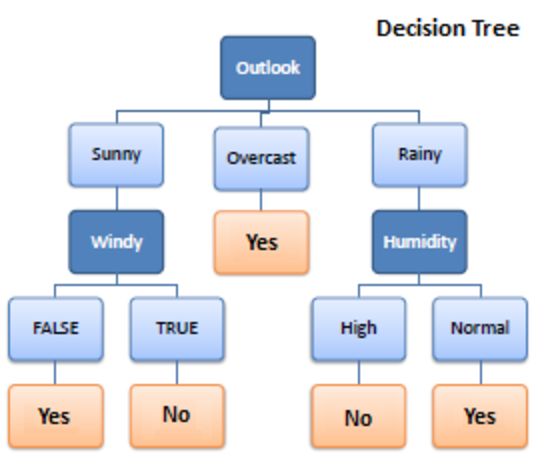
1. 决策树
资源
决策树是一种用于机器学习的监督学习算法。 它在分类和回归算法中运行。 顾名思义,它就像一棵有节点的树。 分支取决于标准的数量。 它将数据拆分成这样的分支,直到达到阈值单位。 决策树有根节点、子节点和叶节点。
递归用于遍历节点。 您不需要其他算法。 它可以准确地处理数据,并且最适合线性模式。 它可以轻松处理大数据并且花费更少的时间。
它是如何工作的?
1.拆分
数据在提供给决策树时,会在分支下分成不同的类别。
必读:朴素贝叶斯分类器:优点和缺点,应用程序和类型解释
2. 修剪
修剪是进一步切碎这些树枝。 它作为一种分类来以更好的方式补贴数据。 就像我们说修剪多余部分的方式一样,它的工作原理是一样的。 到达叶节点,修剪结束。 它是决策树中非常重要的一部分。
3. 树木的选择
现在,您必须选择可以顺利处理数据的最佳树。
以下是需要考虑的因素:
4.熵
为了检查树的同质性,需要推断熵。 如果熵为零,则它是同质的; 否则不是。
5. 知识增益
一旦熵减少,就获得了信息。 此信息有助于进一步拆分分支。
- 您需要计算熵。
- 根据不同的标准拆分数据
- 选择最佳信息。
树的深度是一个重要方面。 深度告诉我们在得出结论之前需要做出多少决定。 浅深度树在决策树算法中表现更好。

决策树的优缺点
优点
- 简单
- 透明的过程
- 处理数字和分类数据
- 数据越大,结果越好
- 速度
缺点
- 可能过拟合
- 修剪过程大
- 优化无保证
- 复杂的计算
- 偏转高
结帐:机器学习模型解释
2. 随机森林
资源
它也用于监督学习,但非常强大。 它的使用非常广泛。 基本区别在于它不依赖于单一的决定。 它根据几个决定组合随机决定,并根据多数做出最终决定。
它不搜索最佳预测。 相反,它会做出多个随机预测。 因此,附加了更多的多样性,并且预测变得更加平滑。
您可以推断随机森林是多个决策树的集合!
Bagging 是在决策并行工作时建立随机森林的过程。
1. 装袋
- 取一些训练数据集
- 制作决策树
- 重复该过程一段时间
- 现在进行主要投票。 获胜的是您的决定。
2. 自举
自举是从训练数据中随机选择样本。 这是一个随机程序。
一步步
- 随机选择条件
- 计算根节点
- 分裂
- 重复
- 你得到一片森林
阅读:朴素贝叶斯解释
随机森林的优缺点
优点
- 功能强大且高度准确
- 无需标准化
- 可以同时处理多个功能
- 以并行方式运行树
缺点
- 他们有时偏向于某些特征
- 慢
- 不能用于线性方法
- 对高维数据更糟
结论
与随机森林相比,决策树非常容易。 决策树组合了一些决策,而随机森林组合了几个决策树。 因此,这是一个漫长而缓慢的过程。
然而,决策树在大型数据集(尤其是线性数据集)上运行速度快且易于操作。 随机森林模型需要严格的训练。 当您尝试建立一个项目时,您可能需要多个模型。 因此,大量的随机森林,更多的时间。
这取决于您的要求。 如果您在模型上工作的时间较少,那么您一定会选择决策树。 然而,稳定性和可靠的预测在随机森林的篮子中。
如果您有热情并想了解更多关于人工智能的信息,您可以参加IIIT-B 和 upGrad 的机器学习和深度学习 PG 文凭,该文凭提供 400 多个小时的学习、实践课程、工作帮助等等。
随机森林与普通决策树有何不同?
在机器学习中,决策树是一种监督学习技术。 它能够使用分类和回归技术。 顾名思义,它类似于带有节点的树。 标准的数量决定了分支。 它将数据分成这些分支,直到达到阈值单元。 决策树中有根节点、子节点和叶节点。 随机森林也用于监督学习,虽然它有很大的威力。 它很受欢迎。 主要区别在于它不依赖于单个决定。 它根据许多决策组合随机决策,然后根据多数创建最终决策。
与单一决策树相比,使用随机森林的主要优势是什么?
在理想的世界中,我们希望减少与偏差相关和与方差相关的错误。 随机森林很好地解决了这个问题。 随机森林只不过是一系列决策树,它们的发现组合成一个最终结果。 它们之所以如此强大,是因为它们能够减少过度拟合,而不会因偏差而大量增加错误。 另一方面,随机森林是一种强大的建模工具,比单个决策树更具弹性。 它们结合了许多决策树来减少过度拟合和与偏差相关的不准确性,从而产生可用的结果。
决策树的局限性是什么?
决策树的缺点之一是,与其他选择预测器相比,它们非常不稳定。 数据的微小变化可能会导致决策树结构发生重大变化,从而导致结果与消费者在典型事件中的预期不同。 此外,当主要目的是预测连续变量的结果时,决策树对预测的帮助较小。