
ランダムフォレストとディシジョンツリー:ランダムフォレストとディシジョンツリーの違い
公開: 2020-12-30最近の進歩により、複数のアルゴリズムの成長が促進されました。 これらの新しくて燃えるようなアルゴリズムは、データに火をつけました。 これらは、データを処理し、効果的に意思決定を行うのに役立ちます。 世界はインターネットを扱っているので。 ほとんどすべてがインターネット上にあります。 このようなデータを処理するには、決定と解釈を行うための厳密なアルゴリズムが必要です。 現在、アルゴリズムの幅広いリストが存在する中で、最適なものを選択することは大変な作業です。
意思決定アルゴリズムは、ほとんどの組織で広く使用されています。 彼らは1時間おきに些細で大きな決断をしなければなりません。 総売上高の高い領域を取得するために選択する材料の分析から、バックエンドで決定が行われています。 最近のPythonとMLの進歩により、データ処理の基準が押し上げられました。 したがって、データは大量に存在します。 しきい値は組織によって異なります。 広く使用されている2つの主要な決定アルゴリズムがあります。 デシジョンツリーとランダムフォレスト-おなじみですね。
木々や森!
簡単な例でこれを調べてみましょう。
Rsのパケットを購入する必要があるとします。 10個の甘いビスケット。 今、あなたはいくつかのビスケットのブランドの中から1つを決める必要があります。
デシジョンツリーアルゴリズムを選択します。 今、それはRsをチェックします。 甘い10パケット。 それはおそらく最も売れたビスケットを選ぶでしょう。 あなたはルピーのために行くことにします。 チョコレートビスケット10個。 あなたは幸せです!

しかし、あなたの友人はランダムフォレストアルゴリズムを使用しました。 現在、彼はいくつかの決定を下しました。 さらに、多数決を選択します。 彼はさまざまなイチゴ、バニラ、ブルーベリー、オレンジのフレーバーから選択します。 彼は特定のRsをチェックします。 10パケットは、元のパケットより3ユニット多く提供されました。 バニラチョコレートでお召し上がりいただけます。 彼はそのバニラチョコビスケットを買いました。 あなたがあなたの決定を後悔することを余儀なくされている間、彼は最も幸せです。
世界のトップ大学である機械学習オンラインコースに参加して、修士号、エグゼクティブ大学院プログラム、ML&AIの高度な証明書プログラムに参加して、キャリアを早めましょう。
目次
デシジョンツリーとランダムフォレストの違いは何ですか?
1.ディシジョンツリー
ソース
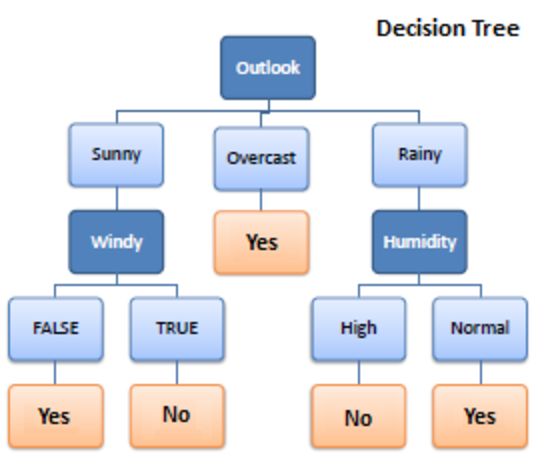
デシジョンツリーは、機械学習で使用される教師あり学習アルゴリズムです。 分類アルゴリズムと回帰アルゴリズムの両方で動作しました。 名前が示すように、それはノードを持つ木のようなものです。 ブランチは、基準の数によって異なります。 しきい値の単位に達するまで、データをこのようなブランチに分割します。 デシジョンツリーには、ルートノード、子ノード、およびリーフノードがあります。
再帰は、ノードをトラバースするために使用されます。 他のアルゴリズムは必要ありません。 データを正確に処理し、線形パターンに最適です。 大きなデータを簡単に処理し、時間もかかりません。
それはどのように機能しますか?
1.分割
データは、意思決定ツリーに提供されると、ブランチの下でさまざまなカテゴリに分割されます。
必読:単純ベイズ分類器:長所と短所、アプリケーションとタイプの説明
2.剪定
剪定はさらにそれらの枝を細断することです。 これは、より良い方法でデータを助成するための分類として機能します。 同様に、余分な部品の剪定と同じように、同じように機能します。 リーフノードに到達し、剪定が終了します。 これは、決定木の非常に重要な部分です。
3.木の選択
ここで、データをスムーズに処理できる最適なツリーを選択する必要があります。
考慮する必要のある要因は次のとおりです。
4.エントロピー
木の均質性を確認するには、エントロピーを推測する必要があります。 エントロピーがゼロの場合、それは均一です。 そうでなければ。
5.知識の獲得
エントロピーが減少すると、情報が取得されます。 この情報は、ブランチをさらに分割するのに役立ちます。
- エントロピーを計算する必要があります。
- さまざまな基準に基づいてデータを分割する
- 最良の情報を選択してください。
木の深さは重要な側面です。 深さは、結論を出す前に行う必要のある決定の数を知らせてくれます。 浅い深さのツリーは、決定木アルゴリズムを使用するとパフォーマンスが向上します。

デシジョンツリーの長所と短所
利点
- 簡単
- 透過的なプロセス
- 数値データとカテゴリデータの両方を処理する
- データが大きいほど、結果は良くなります
- スピード
短所
- 過剰適合する可能性があります
- 大規模な剪定プロセス
- 最適化は保証されていません
- 複雑な計算
- たわみが高い
チェックアウト:機械学習モデルの説明
2.ランダムフォレスト
ソース
教師あり学習にも使用されますが、非常に強力です。 非常に広く使用されています。 基本的な違いは、それが単一の決定に依存しないことです。 いくつかの決定に基づいてランダム化された決定を組み立て、過半数に基づいて最終決定を下します。
最良の予測は検索されません。 代わりに、複数のランダムな予測を行います。 したがって、より多くの多様性が付加され、予測がはるかにスムーズになります。
ランダムフォレストは、複数の決定木のコレクションであると推測できます。
バギングは、意思決定が並行して機能する間にランダムフォレストを確立するプロセスです。
1.バギング
- トレーニングデータセットを取得する
- デシジョンツリーを作成する
- このプロセスを一定期間繰り返します
- 今、主要な投票を取ります。 勝つのはあなたの決断です。
2.ブートストラップ
ブートストラップは、トレーニングデータからサンプルをランダムに選択します。 これはランダムな手順です。
STEP by STEP
- ランダム選択条件
- ルートノードを計算します
- スプリット
- 繰り返す
- あなたは森を手に入れます
読む:ナイーブベイズの説明
ランダムフォレストの長所と短所
利点
- パワフルで高精度
- 正規化する必要はありません
- 一度に複数の機能を処理できます
- 並行してツリーを実行する
短所
- 彼らは時々特定の機能に偏っています
- スロー
- 線形メソッドには使用できません
- 高次元データにはさらに悪い
結論
ランダムフォレストと比較して、決定木は非常に簡単です。 決定木はいくつかの決定木を組み合わせますが、ランダムフォレストはいくつかの決定木を組み合わせます。 したがって、それは長いプロセスですが、遅いです。
一方、決定木は高速で、大規模なデータセット、特に線形データセットで簡単に動作します。 ランダムフォレストモデルには、厳密なトレーニングが必要です。 プロジェクトを立ち上げようとしているときは、複数のモデルが必要になる場合があります。 したがって、多数のランダムフォレスト、より多くの時間。
それはあなたの要件に依存します。 モデルで作業する時間が少ない場合は、決定木を選択する必要があります。 ただし、安定性と信頼性の高い予測は、ランダムフォレストのバスケットに含まれています。
情熱があり、人工知能についてもっと知りたい場合は、機械学習とディープラーニングでIIIT-BとupGradのPGディプロマを受講できます。これは、400時間以上の学習、実践的なセッション、仕事の支援などを提供します。
ランダムフォレストは通常の決定木とどう違うのですか?
機械学習では、決定木は教師あり学習手法です。 分類手法と回帰手法の両方で機能します。 名前が示すように、ノードのあるツリーに似ています。 基準の量によってブランチが決まります。 しきい値単位に達するまで、データをこれらのブランチに分割します。 デシジョンツリーには、ルートノード、子ノード、およびリーフノードがあります。 ランダムフォレストは、強力ですが、教師あり学習にも使用されます。 とても人気があります。 主な違いは、単一の決定に依存しないことです。 多くの決定に基づいてランダム化された決定を組み立て、多数派に応じて最終決定を作成します。
ランダムフォレストを使用することと単一の決定木を使用することの主な利点は何ですか?
理想的な世界では、バイアス関連のエラーと分散関連のエラーの両方を減らしたいと考えています。 この問題は、ランダムフォレストによって適切に対処されています。 ランダムフォレストは、一連の決定木にすぎず、その結果が1つの最終結果に結合されます。 それらは、バイアスによるエラーを大幅に増加させることなく過剰適合を減らす能力があるため、非常に強力です。 一方、ランダムフォレストは、単一の決定木よりもはるかに回復力のある強力なモデリングツールです。 それらは、多数の決定木を組み合わせて、過剰適合およびバイアス関連の不正確さを減らし、したがって、使用可能な結果を生成します。
デシジョンツリーの制限は何ですか?
デシジョンツリーの欠点の1つは、他の選択予測子と比較した場合に非常に不安定になることです。 データをわずかに変更すると、意思決定ツリーの構造が大幅に変更され、通常のイベントで消費者が期待するものとは異なる結果になる可能性があります。 さらに、主な目的が連続変数の結果を予測することである場合、決定木は予測を行うのにあまり役立ちません。