
隨機森林與決策樹:隨機森林與決策樹的區別
已發表: 2020-12-30最近的進步為多種算法的發展鋪平了道路。 這些新的和驚人的算法已經讓數據著火了。 它們有助於有效地處理數據並做出決策。 由於世界正在處理互聯網熱潮。 幾乎所有東西都在互聯網上。 為了處理這些數據,我們需要嚴格的算法來做出決策和解釋。 現在,在存在大量算法的情況下,選擇最適合的算法是一項艱鉅的任務。
大多數組織都廣泛使用決策算法。 他們必須每隔一小時就做出一些瑣碎和重大的決定。 通過分析選擇哪種材料來獲得高總面積,後端正在做出決定。 最近 python 和 ML 的進步推動了處理數據的標準。 因此,數據大量存在。 閾值取決於組織。 有兩種廣泛使用的主要決策算法。 決策樹和隨機森林 - 聽起來很熟悉,對吧?
樹木和森林!
讓我們用一個簡單的例子來探討一下。
假設您必須購買一包盧比。 10塊甜餅乾。 現在,您必須從幾個餅乾品牌中選擇一個。
你選擇一個決策樹算法。 現在,它將檢查盧比。 10包,很甜。 它可能會選擇最暢銷的餅乾。 您將決定購買盧比。 10塊巧克力餅乾。 你很快樂!

但是你的朋友使用了隨機森林算法。 現在,他已經做出了幾個決定。 此外,選擇多數決定。 他選擇了各種草莓、香草、藍莓和橙子口味。 他檢查了一個特定的盧比。 10 包比原來的多送達 3 個單位。 它是在香草巧克力中供應的。 他買了那個香草巧克力餅乾。 他是最快樂的,而你卻為你的決定感到後悔。
加入來自世界頂級大學的機器學習在線課程——碩士、高管研究生課程和 ML 和 AI 高級證書課程,以加快您的職業生涯。
目錄
決策樹和隨機森林有什麼區別?
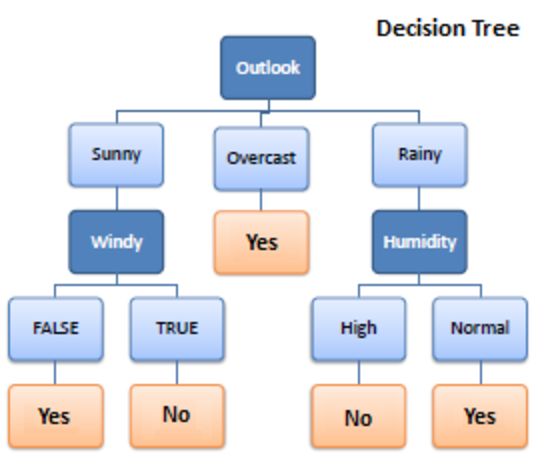
1. 決策樹
資源
決策樹是一種用於機器學習的監督學習算法。 它在分類和回歸算法中運行。 顧名思義,它就像一棵有節點的樹。 分支取決於標準的數量。 它將數據拆分成這樣的分支,直到達到閾值單位。 決策樹有根節點、子節點和葉節點。
遞歸用於遍歷節點。 您不需要其他算法。 它可以準確地處理數據,並且最適合線性模式。 它可以輕鬆處理大數據並且花費更少的時間。
它是如何工作的?
1.拆分
數據在提供給決策樹時,會在分支下分成不同的類別。
必讀:樸素貝葉斯分類器:優點和缺點,應用程序和類型解釋
2. 修剪
修剪是進一步切碎這些樹枝。 它作為一種分類來以更好的方式補貼數據。 就像我們說修剪多餘部分的方式一樣,它的工作原理是一樣的。 到達葉節點,修剪結束。 它是決策樹中非常重要的一部分。
3. 樹木的選擇
現在,您必須選擇可以順利處理數據的最佳樹。
以下是需要考慮的因素:
4.熵
為了檢查樹的同質性,需要推斷熵。 如果熵為零,則它是同質的; 否則不是。
5. 知識增益
一旦熵減少,就獲得了信息。 此信息有助於進一步拆分分支。
- 您需要計算熵。
- 根據不同的標準拆分數據
- 選擇最佳信息。
樹的深度是一個重要方面。 深度告訴我們在得出結論之前需要做出多少決定。 淺深度樹在決策樹算法中表現更好。

決策樹的優缺點
優點
- 簡單
- 透明的過程
- 處理數字和分類數據
- 數據越大,結果越好
- 速度
缺點
- 可能過擬合
- 修剪過程大
- 優化無保證
- 複雜的計算
- 偏轉高
結帳:機器學習模型解釋
2. 隨機森林
資源
它也用於監督學習,但非常強大。 它的使用非常廣泛。 基本區別在於它不依賴於單一的決定。 它根據幾個決定組合隨機決定,並根據多數做出最終決定。
它不搜索最佳預測。 相反,它會做出多個隨機預測。 因此,附加了更多的多樣性,並且預測變得更加平滑。
您可以推斷隨機森林是多個決策樹的集合!
Bagging 是在決策並行工作時建立隨機森林的過程。
1. 裝袋
- 取一些訓練數據集
- 製作決策樹
- 重複該過程一段時間
- 現在進行主要投票。 獲勝的是您的決定。
2. 自舉
自舉是從訓練數據中隨機選擇樣本。 這是一個隨機程序。
一步步
- 隨機選擇條件
- 計算根節點
- 分裂
- 重複
- 你得到一片森林
閱讀:樸素貝葉斯解釋
隨機森林的優缺點
優點
- 功能強大且高度準確
- 無需標準化
- 可以同時處理多個功能
- 以並行方式運行樹
缺點
- 他們有時偏向於某些特徵
- 慢
- 不能用於線性方法
- 對高維數據更糟
結論
與隨機森林相比,決策樹非常容易。 決策樹組合了一些決策,而隨機森林組合了幾個決策樹。 因此,這是一個漫長而緩慢的過程。
然而,決策樹在大型數據集(尤其是線性數據集)上運行速度快且易於操作。 隨機森林模型需要嚴格的訓練。 當您嘗試建立一個項目時,您可能需要多個模型。 因此,大量的隨機森林,更多的時間。
這取決於您的要求。 如果您在模型上工作的時間較少,那麼您一定會選擇決策樹。 然而,穩定性和可靠的預測在隨機森林的籃子中。
如果您有熱情並想了解更多關於人工智能的信息,您可以參加IIIT-B 和 upGrad 的機器學習和深度學習 PG 文憑,該文憑提供 400 多個小時的學習、實踐課程、工作幫助等等。
隨機森林與普通決策樹有何不同?
在機器學習中,決策樹是一種監督學習技術。 它能夠使用分類和回歸技術。 顧名思義,它類似於帶有節點的樹。 標準的數量決定了分支。 它將數據分成這些分支,直到達到閾值單元。 決策樹中有根節點、子節點和葉節點。 隨機森林也用於監督學習,雖然它有很大的威力。 它很受歡迎。 主要區別在於它不依賴於單個決定。 它根據許多決策組合隨機決策,然後根據多數創建最終決策。
與單一決策樹相比,使用隨機森林的主要優勢是什麼?
在理想的世界中,我們希望減少與偏差相關和與方差相關的錯誤。 隨機森林很好地解決了這個問題。 隨機森林只不過是一系列決策樹,它們的發現組合成一個最終結果。 它們之所以如此強大,是因為它們能夠減少過度擬合,而不會因偏差而大量增加錯誤。 另一方面,隨機森林是一種強大的建模工具,比單個決策樹更具彈性。 它們結合了許多決策樹來減少過度擬合和與偏差相關的不准確性,從而產生可用的結果。
決策樹的局限性是什麼?
決策樹的缺點之一是,與其他選擇預測器相比,它們非常不穩定。 數據的微小變化可能會導致決策樹結構發生重大變化,從而導致結果與消費者在典型事件中的預期不同。 此外,當主要目的是預測連續變量的結果時,決策樹對預測的幫助較小。