
Forêt aléatoire vs arbre de décision : Différence entre forêt aléatoire et arbre de décision
Publié: 2020-12-30Les progrès récents ont ouvert la voie à la croissance de plusieurs algorithmes. Ces algorithmes nouveaux et flamboyants ont mis le feu aux données. Ils aident à gérer les données et à prendre des décisions avec eux efficacement. Puisque le monde a affaire à une frénésie Internet. Presque tout est sur Internet. Pour gérer ces données, nous avons besoin d'algorithmes rigoureux pour prendre des décisions et des interprétations. Maintenant, en présence d'une large liste d'algorithmes, c'est une lourde tâche de choisir le mieux adapté.
Les algorithmes décisionnels sont largement utilisés par la plupart des organisations. Ils doivent prendre des décisions triviales et importantes toutes les deux heures. De l'analyse du matériau à choisir pour obtenir des surfaces brutes élevées, une décision se passe dans le backend. Les récentes avancées de Python et ML ont repoussé la barre de la gestion des données. Ainsi, les données sont présentes en masses énormes. Le seuil dépend de l'organisation. Il existe 2 principaux algorithmes de décision largement utilisés. Arbre de décision et forêt aléatoire - Cela vous semble familier, non ?
Arbres et forêts !
Explorons cela avec un exemple simple.
Supposons que vous deviez acheter un paquet de Rs. 10 biscuits sucrés. Maintenant, vous devez choisir une parmi plusieurs marques de biscuits.
Vous choisissez un algorithme d'arbre de décision. Maintenant, il vérifiera les Rs. 10 paquet, qui est doux. Il choisira sans doute les biscuits les plus vendus. Vous déciderez d'aller pour Rs. 10 biscuits au chocolat. Tu es heureux!

Mais votre ami a utilisé l'algorithme Random forest. Maintenant, il a pris plusieurs décisions. De plus, choisir la décision majoritaire. Il choisit parmi diverses saveurs de fraise, de vanille, de myrtille et d'orange. Il vérifie qu'un Rs particulier. 10 paquets ont servi 3 unités de plus que l'original. Il était servi dans du chocolat à la vanille. Il a acheté ce biscuit chocolat vanille. Il est le plus heureux, tandis que vous regrettez votre décision.
Rejoignez le cours en ligne d'apprentissage automatique des meilleures universités du monde - Masters, programmes de troisième cycle pour cadres et programme de certificat avancé en ML et IA pour accélérer votre carrière.
Table des matières
Quelle est la différence entre l'arbre de décision et la forêt aléatoire ?
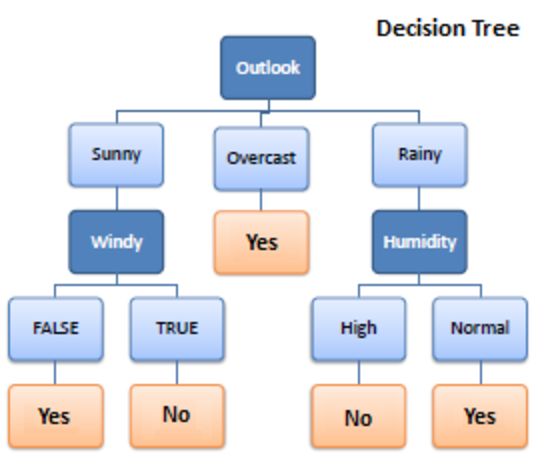
1. Arbre de décision
La source
Decision Tree est un algorithme d'apprentissage supervisé utilisé dans l'apprentissage automatique. Il fonctionnait à la fois dans des algorithmes de classification et de régression. Comme son nom l'indique, c'est comme un arbre avec des nœuds. Les branches dépendent du nombre de critères. Il divise les données en branches comme celles-ci jusqu'à ce qu'il atteigne une unité de seuil. Un arbre de décision a des nœuds racines, des nœuds enfants et des nœuds feuilles.
La récursivité est utilisée pour parcourir les nœuds. Vous n'avez besoin d'aucun autre algorithme. Il gère les données avec précision et fonctionne mieux pour un motif linéaire. Il gère facilement les données volumineuses et prend moins de temps.
Comment ça marche?
1. Fractionnement
Les données, lorsqu'elles sont fournies à l'arbre de décision, sont divisées en différentes catégories sous des branches.
Doit lire: Naive Bayes Classifier: Avantages et inconvénients, applications et types expliqués
2. Taille
L'élagage est également le déchiquetage de ces branches. Cela fonctionne comme une classification pour mieux subventionner les données. Par exemple, de la même manière que nous disons l'élagage des parties en excès, cela fonctionne de la même manière. Le nœud feuille est atteint et l'élagage se termine. C'est une partie très importante des arbres de décision.
3. Sélection des arbres
Maintenant, vous devez choisir le meilleur arbre qui peut fonctionner sans problème avec vos données.
Voici les facteurs qui doivent être pris en considération :
4. Entropie
Pour vérifier l'homogénéité des arbres, il faut déduire l'entropie. Si l'entropie est nulle, c'est homogène ; sinon non.
5. Acquisition de connaissances
Une fois l'entropie diminuée, l'information est acquise. Cette information aide à diviser davantage les branches.
- Il faut calculer l'entropie.
- Fractionner les données sur la base de différents critères
- Choisissez les meilleures informations.
La profondeur des arbres est un aspect important. La profondeur nous informe du nombre de décisions à prendre avant de parvenir à une conclusion. Les arbres peu profonds fonctionnent mieux avec les algorithmes d'arbre de décision.
Avantages et inconvénients de l'arbre de décision
Avantages
- Facile
- Processus transparent
- Traiter les données numériques et catégorielles
- Plus les données sont grandes, meilleur est le résultat
- Vitesse
Désavantages
- Peut surfaire
- Processus d'élagage grand
- Optimisation sans garantie
- Calculs complexes
- Déviation élevée
Paiement : Explication des modèles d'apprentissage automatique

2. Forêt aléatoire
La source
Il est également utilisé pour l'apprentissage supervisé mais est très puissant. Il est très largement utilisé. La différence fondamentale étant qu'elle ne repose pas sur une décision unique. Il assemble des décisions aléatoires basées sur plusieurs décisions et rend la décision finale basée sur la majorité.
Il ne recherche pas la meilleure prédiction. Au lieu de cela, il fait plusieurs prédictions aléatoires. Ainsi, plus de diversité est attachée et la prédiction devient beaucoup plus fluide.
Vous pouvez en déduire que la forêt aléatoire est une collection d'arbres de décision multiples !
Le bagging est le processus d'établissement de forêts aléatoires pendant que les décisions fonctionnent en parallèle.
1. Ensachage
- Prenez un ensemble de données de formation
- Faire un arbre de décision
- Répétez le processus pendant une période définie
- Maintenant, prenez le vote majeur. Celui qui gagne est votre décision à prendre.
2. Amorçage
Le bootstrapping consiste à choisir au hasard des échantillons à partir de données d'apprentissage. Il s'agit d'une procédure aléatoire.
Pas à pas
- Conditions de choix aléatoires
- Calculer le nœud racine
- Diviser
- Répéter
- Vous obtenez une forêt
Lire : Bayes naïf expliqué
Avantages et inconvénients de la forêt aléatoire
Avantages
- Puissant et très précis
- Pas besoin de normaliser
- Peut gérer plusieurs fonctionnalités à la fois
- Exécutez les arbres de manière parallèle
Désavantages
- Ils sont parfois biaisés par certaines fonctionnalités
- Lent
- Ne peut pas être utilisé pour les méthodes linéaires
- Pire pour les données de grande dimension
Conclusion
Les arbres de décision sont très simples par rapport à la forêt aléatoire. Un arbre de décision combine certaines décisions, tandis qu'une forêt aléatoire combine plusieurs arbres de décision. C'est donc un processus long, mais lent.
Alors qu'un arbre de décision est rapide et fonctionne facilement sur de grands ensembles de données, en particulier les linéaires. Le modèle de forêt aléatoire nécessite une formation rigoureuse. Lorsque vous essayez de mettre en place un projet, vous pourriez avoir besoin de plus d'un modèle. Ainsi, un grand nombre de forêts aléatoires, plus le temps.
Cela dépend de vos besoins. Si vous avez moins de temps pour travailler sur un modèle, vous êtes obligé de choisir un arbre de décision. Cependant, la stabilité et les prévisions fiables sont dans le panier des forêts aléatoires.
Si vous avez la passion et que vous souhaitez en savoir plus sur l'intelligence artificielle, vous pouvez suivre le diplôme PG d'IIIT-B & upGrad en apprentissage automatique et en apprentissage en profondeur qui offre plus de 400 heures d'apprentissage, des sessions pratiques, une assistance au travail et bien plus encore.
En quoi la forêt aléatoire est-elle différente d'un arbre de décision normal ?
En apprentissage automatique, un arbre de décision est une technique d'apprentissage supervisé. Il est capable de travailler avec des techniques de classification et de régression. Il ressemble à un arbre avec des nœuds, comme son nom l'indique. Le nombre de critères détermine les branches. Il divise les données dans ces branches jusqu'à ce qu'elles atteignent une unité de seuil. Il existe des nœuds racines, des nœuds enfants et des nœuds feuilles dans un arbre de décision. La forêt aléatoire est également utilisée pour l'apprentissage supervisé, bien qu'elle ait beaucoup de puissance. C'est assez populaire. La principale distinction est qu'elle ne repose pas sur une seule décision. Il assemble des décisions aléatoires basées sur de nombreuses décisions, puis crée une décision finale en fonction de la majorité.
Quels sont les principaux avantages de l'utilisation d'une forêt aléatoire par rapport à un arbre de décision unique ?
Dans un monde idéal, nous aimerions réduire les erreurs liées aux biais et à la variance. Ce problème est bien résolu par les forêts aléatoires. Une forêt aléatoire n'est rien de plus qu'une série d'arbres de décision dont les résultats sont combinés en un seul résultat final. Ils sont si puissants en raison de leur capacité à réduire le surajustement sans augmenter massivement les erreurs dues aux biais. Les forêts aléatoires, en revanche, sont un outil de modélisation puissant qui est beaucoup plus résilient qu'un arbre de décision unique. Ils combinent de nombreux arbres de décision pour réduire le surajustement et l'inexactitude liée aux biais, et produisent ainsi des résultats utilisables.
Qu'est-ce qu'une limitation des arbres de décision ?
L'un des inconvénients des arbres de décision est qu'ils sont très instables par rapport aux autres prédicteurs de choix. Une légère modification des données peut entraîner une modification significative de la structure de l'arbre de décision, entraînant un résultat différent de ce à quoi les consommateurs s'attendraient lors d'un événement typique. De plus, lorsque l'objectif principal est de prévoir le résultat d'une variable continue, les arbres de décision sont moins utiles pour faire des prédictions.