
Random Forest vs. Entscheidungsbaum: Unterschied zwischen Random Forest und Entscheidungsbaum
Veröffentlicht: 2020-12-30Jüngste Fortschritte haben das Wachstum mehrerer Algorithmen geebnet. Diese neuen und flammenden Algorithmen haben die Daten in Brand gesetzt. Sie helfen dabei, mit Daten umzugehen und mit ihnen effektiv Entscheidungen zu treffen. Denn die Welt hat es mit einem Internetrausch zu tun. Fast alles steht im Internet. Um mit solchen Daten umgehen zu können, brauchen wir strenge Algorithmen, um Entscheidungen und Interpretationen zu treffen. Angesichts einer breiten Liste von Algorithmen ist es jetzt eine schwere Aufgabe, den am besten geeigneten auszuwählen.
Entscheidungsfindungsalgorithmen werden von den meisten Organisationen häufig verwendet. Sie müssen jede zweite Stunde triviale und große Entscheidungen treffen. Von der Analyse, welches Material ausgewählt werden soll, um hohe Bruttoflächen zu erhalten, erfolgt eine Entscheidung im Backend. Die jüngsten Python- und ML-Fortschritte haben die Messlatte für den Umgang mit Daten verschoben. Daten liegen also in riesigen Massen vor. Der Schwellenwert hängt von der Organisation ab. Es gibt zwei wichtige Entscheidungsalgorithmen, die weit verbreitet sind. Decision Tree und Random Forest – Klingt vertraut, oder?
Bäume und Wälder!
Lassen Sie uns dies anhand eines einfachen Beispiels untersuchen.
Angenommen, Sie müssen ein Paket Rs kaufen. 10 süße Kekse. Jetzt müssen Sie sich für eine von mehreren Keksmarken entscheiden.
Sie wählen einen Entscheidungsbaumalgorithmus. Jetzt wird es die Rs überprüfen. 10 Päckchen, das ist süß. Es werden wahrscheinlich die meistverkauften Kekse ausgewählt. Sie werden sich entscheiden, für Rs zu gehen. 10 Schokoladenkekse. Du bist glücklich!

Aber Ihr Freund hat den Random-Forest-Algorithmus verwendet. Jetzt hat er mehrere Entscheidungen getroffen. Weiterhin Wahl der Mehrheitsentscheidung. Er wählt zwischen verschiedenen Erdbeer-, Vanille-, Heidelbeer- und Orangenaromen. Er prüft, ob ein bestimmter Rs. 10 Päckchen dienten 3 Einheiten mehr als das Original. Es wurde in Vanilleschokolade serviert. Er hat diesen Vanille-Schoko-Keks gekauft. Er ist am glücklichsten, während Sie Ihre Entscheidung bereuen müssen.
Nehmen Sie am Online-Kurs für maschinelles Lernen von den besten Universitäten der Welt teil – Master, Executive Post Graduate Programs und Advanced Certificate Program in ML & AI, um Ihre Karriere zu beschleunigen.
Inhaltsverzeichnis
Was ist der Unterschied zwischen Entscheidungsbaum und Random Forest?
1. Entscheidungsbaum
Quelle
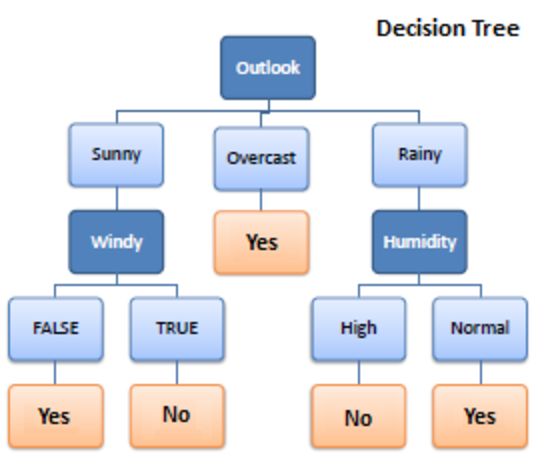
Entscheidungsbaum ist ein überwachter Lernalgorithmus, der beim maschinellen Lernen verwendet wird. Es arbeitete sowohl mit Klassifikations- als auch mit Regressionsalgorithmen. Wie der Name schon sagt, ist es wie ein Baum mit Knoten. Die Verzweigungen hängen von der Anzahl der Kriterien ab. Es teilt Daten in Zweige wie diese auf, bis es eine Schwelleneinheit erreicht. Ein Entscheidungsbaum hat Wurzelknoten, untergeordnete Knoten und Blattknoten.
Rekursion wird zum Durchlaufen der Knoten verwendet. Sie brauchen keinen anderen Algorithmus. Es verarbeitet Daten genau und funktioniert am besten für ein lineares Muster. Es verarbeitet große Datenmengen einfach und nimmt weniger Zeit in Anspruch.
Wie funktioniert es?
1. Teilen
Daten werden, wenn sie dem Entscheidungsbaum bereitgestellt werden, einer Aufteilung in verschiedene Kategorien unter Verzweigungen unterzogen.
Muss gelesen werden: Naive Bayes-Klassifikator: Vor- und Nachteile, Anwendungen und Typen erklärt
2. Beschneiden
Das Beschneiden ist außerdem das Zerkleinern dieser Äste. Es funktioniert als Klassifizierung, um die Daten besser zu subventionieren. Genauso wie wir das Beschneiden überschüssiger Teile sagen, funktioniert es genauso. Der Blattknoten ist erreicht und das Beschneiden endet. Es ist ein sehr wichtiger Teil von Entscheidungsbäumen.
3. Auswahl der Bäume
Jetzt müssen Sie den besten Baum auswählen, der reibungslos mit Ihren Daten arbeiten kann.
Hier sind die Faktoren, die berücksichtigt werden müssen:
4. Entropie
Um die Homogenität von Bäumen zu überprüfen, muss auf die Entropie geschlossen werden. Wenn die Entropie null ist, ist sie homogen; sonst nicht.
5. Erkenntnisgewinn
Sobald die Entropie verringert wird, wird die Information gewonnen. Diese Informationen helfen, die Zweige weiter aufzuteilen.
- Sie müssen die Entropie berechnen.
- Teilen Sie die Daten nach verschiedenen Kriterien auf
- Wählen Sie die besten Informationen.
Die Baumtiefe ist ein wichtiger Aspekt. Die Tiefe informiert uns über die Anzahl der Entscheidungen, die man treffen muss, bevor man zu einer Schlussfolgerung kommt. Bäume mit geringer Tiefe funktionieren besser mit Entscheidungsbaumalgorithmen.
Vor- und Nachteile des Entscheidungsbaums
Vorteile
- Leicht
- Transparenter Prozess
- Behandeln Sie sowohl numerische als auch kategoriale Daten
- Je größer die Daten, desto besser das Ergebnis
- Geschwindigkeit
Nachteile
- Kann überanpassen
- Beschneidungsprozess groß
- Optimierung nicht garantiert
- Komplexe Berechnungen
- Durchbiegung hoch
Checkout: Modelle für maschinelles Lernen erklärt

2. Zufälliger Wald
Quelle
Es wird auch für überwachtes Lernen verwendet, ist aber sehr leistungsfähig. Es ist sehr weit verbreitet. Der grundlegende Unterschied besteht darin, dass es sich nicht auf eine einzelne Entscheidung stützt. Es stellt randomisierte Entscheidungen auf der Grundlage mehrerer Entscheidungen zusammen und trifft die endgültige Entscheidung auf der Grundlage der Mehrheit.
Es wird nicht nach der besten Vorhersage gesucht. Stattdessen macht es mehrere zufällige Vorhersagen. Somit wird mehr Diversität angebracht und die Vorhersage wird viel glatter.
Sie können schlussfolgern, dass Random Forest eine Sammlung mehrerer Entscheidungsbäume ist!
Bagging ist der Prozess, zufällige Gesamtstrukturen aufzubauen, während Entscheidungen parallel funktionieren.
1. Absacken
- Nehmen Sie einen Trainingsdatensatz
- Erstellen Sie einen Entscheidungsbaum
- Wiederholen Sie den Vorgang für einen bestimmten Zeitraum
- Nehmen Sie jetzt die Hauptabstimmung vor. Derjenige, der gewinnt, ist Ihre Entscheidung.
2. Bootstrapping
Bootstrapping ist die zufällige Auswahl von Stichproben aus Trainingsdaten. Dies ist ein Zufallsverfahren.
Schritt für Schritt
- Zufällige Auswahlbedingungen
- Berechnen Sie den Wurzelknoten
- Teilt
- Wiederholen
- Du bekommst einen Wald
Lesen Sie: Naive Bayes erklärt
Vor- und Nachteile von Random Forest
Vorteile
- Leistungsstark und hochpräzise
- Keine Notwendigkeit zu normalisieren
- Kann mehrere Funktionen gleichzeitig verarbeiten
- Führen Sie Bäume parallel aus
Nachteile
- Sie sind manchmal auf bestimmte Merkmale voreingenommen
- Schleppend
- Kann nicht für lineare Methoden verwendet werden
- Schlimmer für hochdimensionale Daten
Fazit
Entscheidungsbäume sind im Vergleich zum Random Forest sehr einfach. Ein Entscheidungsbaum kombiniert einige Entscheidungen, während ein Random Forest mehrere Entscheidungsbäume kombiniert. Daher ist es ein langer Prozess, aber langsam.
Dagegen ist ein Entscheidungsbaum schnell und funktioniert problemlos mit großen Datensätzen, insbesondere mit linearen. Das Random-Forest-Modell erfordert strenges Training. Wenn Sie versuchen, ein Projekt aufzustellen, benötigen Sie möglicherweise mehr als ein Modell. Daher eine große Anzahl von zufälligen Wäldern, mehr Zeit.
Es hängt von Ihren Anforderungen ab. Wenn Sie weniger Zeit haben, an einem Modell zu arbeiten, müssen Sie sich für einen Entscheidungsbaum entscheiden. Stabilität und verlässliche Vorhersagen liegen jedoch im Körbchen zufälliger Wälder.
Wenn Sie die Leidenschaft haben und mehr über künstliche Intelligenz erfahren möchten, können Sie das PG-Diplom von IIIT-B & upGrad in Machine Learning und Deep Learning absolvieren, das mehr als 400 Stunden Lernen, praktische Sitzungen, Arbeitsunterstützung und vieles mehr bietet.
Wie unterscheidet sich Random Forest von einem normalen Entscheidungsbaum?
Beim maschinellen Lernen ist ein Entscheidungsbaum eine Technik des überwachten Lernens. Es kann sowohl mit Klassifikations- als auch mit Regressionstechniken arbeiten. Es ähnelt einem Baum mit Knoten, wie der Name schon sagt. Die Anzahl der Kriterien bestimmt die Branchen. Es teilt Daten in diese Zweige auf, bis es eine Schwelleneinheit erreicht. In einem Entscheidungsbaum gibt es Wurzelknoten, Kindknoten und Blattknoten. Random Forest wird auch für überwachtes Lernen verwendet, obwohl es viel Kraft hat. Es ist sehr beliebt. Der Hauptunterschied besteht darin, dass es sich nicht auf eine einzelne Entscheidung stützt. Es stellt randomisierte Entscheidungen auf der Grundlage vieler Entscheidungen zusammen und erstellt dann eine endgültige Entscheidung in Abhängigkeit von der Mehrheit.
Was sind die Hauptvorteile der Verwendung einer zufälligen Gesamtstruktur gegenüber einem einzelnen Entscheidungsbaum?
In einer idealen Welt möchten wir sowohl voreingenommene als auch varianzbedingte Fehler reduzieren. Dieses Problem wird von Random Forests gut angegangen. Ein Random Forest ist nichts anderes als eine Reihe von Entscheidungsbäumen, deren Ergebnisse zu einem einzigen Endergebnis kombiniert werden. Sie sind so leistungsfähig, weil sie eine Überanpassung reduzieren können, ohne den Fehler aufgrund von Voreingenommenheit massiv zu erhöhen. Random Forests hingegen sind ein leistungsfähiges Modellierungswerkzeug, das weitaus widerstandsfähiger ist als ein einzelner Entscheidungsbaum. Sie kombinieren zahlreiche Entscheidungsbäume, um Overfitting und verzerrungsbedingte Ungenauigkeiten zu reduzieren und somit brauchbare Ergebnisse zu liefern.
Was ist eine Einschränkung von Entscheidungsbäumen?
Einer der Nachteile von Entscheidungsbäumen ist, dass sie im Vergleich zu anderen Entscheidungsprädiktoren sehr instabil sind. Eine geringfügige Änderung der Daten kann zu einer erheblichen Änderung der Struktur des Entscheidungsbaums führen, was zu einem Ergebnis führt, das von dem abweicht, was Verbraucher bei einem typischen Ereignis erwarten würden. Wenn der Hauptzweck darin besteht, das Ergebnis einer kontinuierlichen Variablen vorherzusagen, sind Entscheidungsbäume außerdem weniger hilfreich, um Vorhersagen zu treffen.