
Random Forest Vs Decision Tree: diferencia entre Random Forest y Decision Tree
Publicado: 2020-12-30Los avances recientes han allanado el crecimiento de múltiples algoritmos. Estos algoritmos nuevos y resplandecientes han incendiado los datos. Ayudan a manejar datos y a tomar decisiones con ellos de manera efectiva. Dado que el mundo está lidiando con una juerga de Internet. Casi todo está en Internet. Para manejar tales datos, necesitamos algoritmos rigurosos para tomar decisiones e interpretaciones. Ahora, en presencia de una amplia lista de algoritmos, es una tarea difícil elegir el más adecuado.
Los algoritmos de toma de decisiones son ampliamente utilizados por la mayoría de las organizaciones. Tienen que tomar decisiones triviales y grandes cada dos horas. Desde el análisis de qué material elegir para obtener áreas brutas altas, se toma una decisión en el backend. Los avances recientes de python y ML han empujado la barra para el manejo de datos. Por lo tanto, los datos están presentes en grandes cantidades. El umbral depende de la organización. Hay 2 algoritmos de decisión principales ampliamente utilizados. Decision Tree y Random Forest: suena familiar, ¿verdad?
¡Árboles y bosques!
Exploremos esto con un ejemplo sencillo.
Suponga que tiene que comprar un paquete de Rs. 10 galletas dulces. Ahora, tienes que elegir una entre varias marcas de galletas.
Usted elige un algoritmo de árbol de decisión. Ahora, comprobará las Rs. 10 paquetes, que es dulce. Elegirá probablemente las galletas más vendidas. Decidirás ir por Rs. 10 galletas de chocolate. ¡Usted es feliz!

Pero tu amigo usó el algoritmo del bosque aleatorio. Ahora, ha tomado varias decisiones. Además, la elección de la decisión de la mayoría. Elige entre varios sabores de fresa, vainilla, arándano y naranja. Comprueba que un Rs particular. El paquete de 10 sirvió 3 unidades más que el original. Fue servido en chocolate de vainilla. Compró esa galleta de chocolate con vainilla. Él es el más feliz, mientras que tú te arrepientes de tu decisión.
Únase al curso en línea de aprendizaje automático de las mejores universidades del mundo: maestrías, programas ejecutivos de posgrado y programa de certificado avanzado en ML e IA para acelerar su carrera.
Tabla de contenido
¿Cuál es la diferencia entre el árbol de decisión y el bosque aleatorio?
1. Árbol de decisión
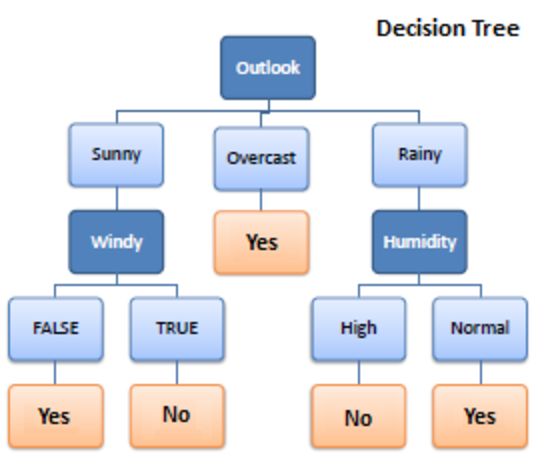
Fuente
Decision Tree es un algoritmo de aprendizaje supervisado utilizado en el aprendizaje automático. Operó en algoritmos de clasificación y regresión. Como sugiere su nombre, es como un árbol con nodos. Las ramas dependen del número de criterios. Divide los datos en ramas como estas hasta que alcanza una unidad de umbral. Un árbol de decisión tiene nodos raíz, nodos secundarios y nodos hoja.
La recursividad se utiliza para atravesar los nodos. No necesitas ningún otro algoritmo. Maneja los datos con precisión y funciona mejor para un patrón lineal. Maneja grandes cantidades de datos fácilmente y toma menos tiempo.
¿Como funciona?
1. Dividir
Los datos, cuando se proporcionan al árbol de decisiones, se dividen en varias categorías en las ramas.
Debe leer: Clasificador Naive Bayes: ventajas y desventajas, aplicaciones y tipos explicados
2. Poda
La poda es, además, la trituración de esas ramas. Funciona como una clasificación para subvencionar mejor los datos. Como, de la misma manera que decimos poda de partes sobrantes, funciona igual. Se alcanza el nudo de la hoja y finaliza la poda. Es una parte muy importante de los árboles de decisión.
3. Selección de árboles
Ahora, debe elegir el mejor árbol que pueda funcionar con sus datos sin problemas.
Estos son los factores que deben tenerse en cuenta:
4. Entropía
Para verificar la homogeneidad de los árboles, se debe inferir la entropía. Si la entropía es cero, es homogénea; de lo contrario no
5. Adquisición de conocimientos
Una vez que se disminuye la entropía, se gana la información. Esta información ayuda a dividir aún más las ramas.
- Necesitas calcular la entropía.
- Dividir los datos sobre la base de diferentes criterios.
- Elige la mejor información.
La profundidad del árbol es un aspecto importante. La profundidad nos informa del número de decisiones que hay que tomar antes de llegar a una conclusión. Los árboles de poca profundidad funcionan mejor con algoritmos de árboles de decisión.
Ventajas y desventajas del árbol de decisión
ventajas
- Fácil
- Proceso transparente
- Manejar datos numéricos y categóricos
- Cuanto mayor sea la información, mejor será el resultado
- Velocidad
Desventajas
- Puede sobreajustarse
- Proceso de poda grande
- Optimización no garantizada
- Cálculos complejos
- Deflexión alta
Pago: Explicación de los modelos de aprendizaje automático

2. Bosque aleatorio
Fuente
También se utiliza para el aprendizaje supervisado, pero es muy potente. Es muy utilizado. La diferencia básica es que no se basa en una decisión singular. Reúne decisiones aleatorias basadas en varias decisiones y toma la decisión final basada en la mayoría.
No busca la mejor predicción. En cambio, hace múltiples predicciones aleatorias. Por lo tanto, se adjunta más diversidad y la predicción se vuelve mucho más suave.
¡Puede inferir que el bosque aleatorio es una colección de árboles de decisiones múltiples!
El embolsado es el proceso de establecer bosques aleatorios mientras las decisiones funcionan en paralelo.
1. Embolsado
- Tome un conjunto de datos de entrenamiento
- Hacer un árbol de decisiones
- Repita el proceso por un período definido
- Ahora toma el voto mayoritario. El que gana es tu decisión de tomar.
2. Arranque
Bootstrapping es elegir aleatoriamente muestras de datos de entrenamiento. Este es un procedimiento aleatorio.
Paso a paso
- Condiciones de elección aleatoria
- Calcular el nodo raíz
- Separar
- Repetir
- obtienes un bosque
Leer: Explicación de Naive Bayes
Ventajas y desventajas del bosque aleatorio
ventajas
- Potente y muy preciso
- No hay necesidad de normalizar
- Puede manejar varias características a la vez
- Ejecutar árboles en formas paralelas
Desventajas
- Están sesgados a ciertas características a veces
- Lento
- No se puede utilizar para métodos lineales.
- Peor para datos de alta dimensión
Conclusión
Los árboles de decisión son muy fáciles en comparación con el bosque aleatorio. Un árbol de decisión combina algunas decisiones, mientras que un bosque aleatorio combina varios árboles de decisión. Por lo tanto, es un proceso largo, pero lento.
Considerando que, un árbol de decisión es rápido y opera fácilmente en grandes conjuntos de datos, especialmente el lineal. El modelo de bosque aleatorio necesita un entrenamiento riguroso. Cuando intentas poner en marcha un proyecto, es posible que necesites más de un modelo. Por lo tanto, una gran cantidad de bosques aleatorios, más el tiempo.
Depende de sus requisitos. Si tiene menos tiempo para trabajar en un modelo, está obligado a elegir un árbol de decisión. Sin embargo, la estabilidad y las predicciones fiables están en la cesta de los bosques aleatorios.
Si tiene pasión y quiere aprender más sobre inteligencia artificial, puede tomar el Diploma PG de IIIT-B y upGrad en Aprendizaje automático y Aprendizaje profundo que ofrece más de 400 horas de aprendizaje, sesiones prácticas, asistencia laboral y mucho más.
¿En qué se diferencia el bosque aleatorio de un árbol de decisión normal?
En el aprendizaje automático, un árbol de decisión es una técnica de aprendizaje supervisado. Es capaz de trabajar tanto con técnicas de clasificación como de regresión. Se asemeja a un árbol con nodos, como su nombre lo indica. La cantidad de criterios determina las ramas. Divide los datos en estas ramas hasta que alcanza una unidad de umbral. Hay nodos raíz, nodos secundarios y nodos hoja en un árbol de decisión. Random forest también se usa para el aprendizaje supervisado, aunque tiene mucho poder. Es bastante popular. La distinción principal es que no se basa en una sola decisión. Reúne decisiones aleatorias basadas en muchas decisiones y luego crea una decisión final dependiendo de la mayoría.
¿Cuáles son las principales ventajas de utilizar un bosque aleatorio frente a un único árbol de decisión?
En un mundo ideal, nos gustaría reducir tanto los errores relacionados con el sesgo como los relacionados con la varianza. Este problema está bien abordado por los bosques aleatorios. Un bosque aleatorio no es más que una serie de árboles de decisión con sus hallazgos combinados en un único resultado final. Son tan poderosos debido a su capacidad para reducir el sobreajuste sin aumentar masivamente el error debido al sesgo. Los bosques aleatorios, por otro lado, son una poderosa herramienta de modelado que es mucho más resistente que un solo árbol de decisión. Combinan numerosos árboles de decisión para reducir el sobreajuste y la inexactitud relacionada con el sesgo y, por lo tanto, producen resultados utilizables.
¿Qué es una limitación de los árboles de decisión?
Uno de los inconvenientes de los árboles de decisión es que son muy inestables en comparación con otros predictores de elección. Un ligero cambio en los datos puede provocar un cambio significativo en la estructura del árbol de decisiones, lo que da como resultado un resultado que difiere de lo que los consumidores esperarían en un evento típico. Además, cuando el propósito principal es pronosticar el resultado de una variable continua, los árboles de decisión son menos útiles para hacer predicciones.