
Obtendo o máximo de modelos pré-treinados
Publicados: 2022-03-11A maioria dos novos modelos de aprendizado profundo lançados, especialmente em PNL, são muito, muito grandes: eles têm parâmetros que variam de centenas de milhões a dezenas de bilhões.
Dada uma arquitetura suficientemente boa, quanto maior o modelo, mais capacidade de aprendizado ele tem. Assim, esses novos modelos têm enorme capacidade de aprendizado e são treinados em conjuntos de dados muito grandes.
Por causa disso, eles aprendem toda a distribuição dos conjuntos de dados nos quais são treinados. Pode-se dizer que eles codificam o conhecimento compactado desses conjuntos de dados. Isso permite que esses modelos sejam usados para aplicações muito interessantes – a mais comum é o aprendizado de transferência. O aprendizado de transferência é o ajuste fino de modelos pré-treinados em conjuntos de dados/tarefas personalizados, o que requer muito menos dados, e os modelos convergem muito rapidamente em comparação com o treinamento do zero.
Como os modelos pré-treinados são os algoritmos do futuro
Embora os modelos pré-treinados também sejam usados em visão computacional, este artigo se concentrará em seu uso de ponta no domínio do processamento de linguagem natural (PLN). A arquitetura do transformador é a arquitetura mais comum e mais poderosa que está sendo usada nesses modelos.
Embora o BERT tenha iniciado a revolução do aprendizado de transferência de PNL, exploraremos os modelos GPT-2 e T5. Esses modelos são pré-treinados - ajustá-los em aplicativos específicos resultará em métricas de avaliação muito melhores, mas nós os usaremos fora da caixa, ou seja, sem ajuste fino.
Modelos de PNL pré-treinados: GPT-2 da OpenAI
O GPT-2 criou bastante controvérsia quando foi lançado em 2019. Como era muito bom em gerar texto, atraiu bastante a atenção da mídia e levantou muitas questões sobre o futuro da IA.
Treinado em 40 GB de dados textuais, o GPT-2 é um modelo muito grande que contém uma enorme quantidade de conhecimento compactado de uma seção transversal da Internet.
O GPT-2 tem muitos casos de uso em potencial. Ele pode ser usado para prever a probabilidade de uma sentença. Isso, por sua vez, pode ser usado para autocorreção de texto. Em seguida, a previsão de palavras pode ser usada diretamente para criar um componente de preenchimento automático para um IDE (como Visual Studio Code ou PyCharm) para escrever código, bem como escrever texto geral. Vamos usá-lo para geração automática de texto, e um grande corpus de texto pode ser usado para análise de linguagem natural.
Geração de Texto
A capacidade de um modelo pré-treinado como o GPT-2 para gerar texto coerente é muito impressionante. Podemos dar-lhe um texto de prefixo e pedir-lhe para gerar a próxima palavra, frase ou frase.
Um exemplo de caso de uso é gerar um conjunto de dados de avaliações de produtos para ver quais tipos de palavras são geralmente usados em avaliações positivas versus críticas negativas.
Vejamos alguns exemplos, começando com o que obtemos se começarmos com o prefixo positivo, “Gostei muito deste filme!”
| Amostra 1 | Adorava as emoções do personagem por estar em constante perigo e como seus medos internos foram lentamente superados por esses eventos. Também adorei que ele está tão focado em sobreviver; mesmo por um tempo parecia que algo fora de Batman v Superman estava aparecendo de vez em quando porque você sempre sabia que seu inimigo iria aparecer eventualmente de qualquer maneira :) |
| Amostra 2 | Ele fez exatamente o que eu queria fazer, apenas muito divertido. O elenco foi incrível e a história faz sentido até agora depois de ver todo o resto já no IMDB. Há dicas sobre estar em uma cidade subterrânea desde tempos imemoriais devido ao seu “poder” (ou falta dele), mas eles realmente não dizem muito… eu acho que é mais um grande mistério do que alguns outros aspectos vindo junto comigo por enquanto embora….é suposto… |
Como você pode ver, a palavra resenha não estava em nenhum lugar do prefixo, mas como a maioria das resenhas são títulos seguidos do corpo da resenha, isso forçou o modelo a se adaptar a essa distribuição. Observe também a referência a Batman v Superman .
Vamos ver outro exemplo. Em vez de uma resenha de filme, tentaremos gerar uma resenha de produto usando o prefixo negativo “Um produto lixo! Não compre."
| Amostra 1 | E, por favor, NÃO tente usar isso como fertilizante para seus jardins ou gramados – causará sérios danos à água se ingerido por peixes e pássaros. Use com cautela devido à possibilidade de que pesticidas possam estar presentes em alimentos para animais de estimação disponíveis on-line em mercearias orgânicas, nomes muito “bons” como Petsmart, PetSmart e Safeway. Quão tóxico é o desperdício de alimentos? Os resíduos podem contribuir com quantidades significativas - o suficiente para que mesmo muito… |
| Amostra 2 | Ninguém vai te dar um pedaço desse lixo nunca mais. Apenas faça um favor a si mesmo e à sua empresa e limpe antes de comprá-lo por nada mais do que economizar algum dinheiro ou conveniência no futuro. Embalagem de plástico para armazenamento de alimentos de 1/2 oz + 1 pacote #1636370105702615 (P, 3ml) $ 7 Compre agora Você pode comprar essas garrafas em qualquer loja de varejo, mas aqui está como obter… |
Novamente, o prefixo pode ser inferido como o título de uma revisão de produto, de modo que o modelo começa a gerar texto seguindo esse padrão. O GPT-2 pode gerar qualquer tipo de texto como este.
Um notebook do Google Colab está pronto para ser usado em experimentos, assim como a demonstração ao vivo “Write With Transformer”.
Resposta a perguntas
Sim, como o GPT-2 é treinado na web, ele “conhece” muito conhecimento humano que foi publicado online até 2019. Pode funcionar para questões contextuais também, mas teremos que seguir o formato explícito de “ Pergunta: X, Resposta:” antes de deixá-lo tentar completar automaticamente. Mas se forçarmos o modelo a responder à nossa pergunta, ele pode gerar uma resposta bastante vaga. Aqui está o que acontece tentando forçá-lo a responder a perguntas abertas para testar seu conhecimento:
| Amostra 1 | Pergunta: Quem inventou a teoria da evolução? Resposta: A teoria da evolução foi proposta pela primeira vez por Charles Darwin em 1859. |
| Amostra 2 | Pergunta: Quantos dentes os humanos têm? Resposta: Os humanos têm 21 dentes. |
Como podemos ver, o modelo pré-treinado deu uma resposta bastante detalhada à primeira pergunta. Para o segundo, deu o seu melhor, mas não se compara com a Pesquisa Google.
É claro que o GPT-2 tem um enorme potencial. Ajustando-o, ele pode ser usado para os exemplos mencionados acima com precisão muito maior. Mas mesmo o GPT-2 pré-treinado que estamos avaliando ainda não é tão ruim.
Modelos de PNL pré-treinados: T5 do Google
O T5 do Google é um dos modelos de linguagem natural mais avançados até hoje. Ele se baseia em trabalhos anteriores em modelos Transformer em geral. Ao contrário do BERT, que tinha apenas blocos codificadores, e GPT-2, que possuía apenas blocos decodificadores, o T5 usa os dois .
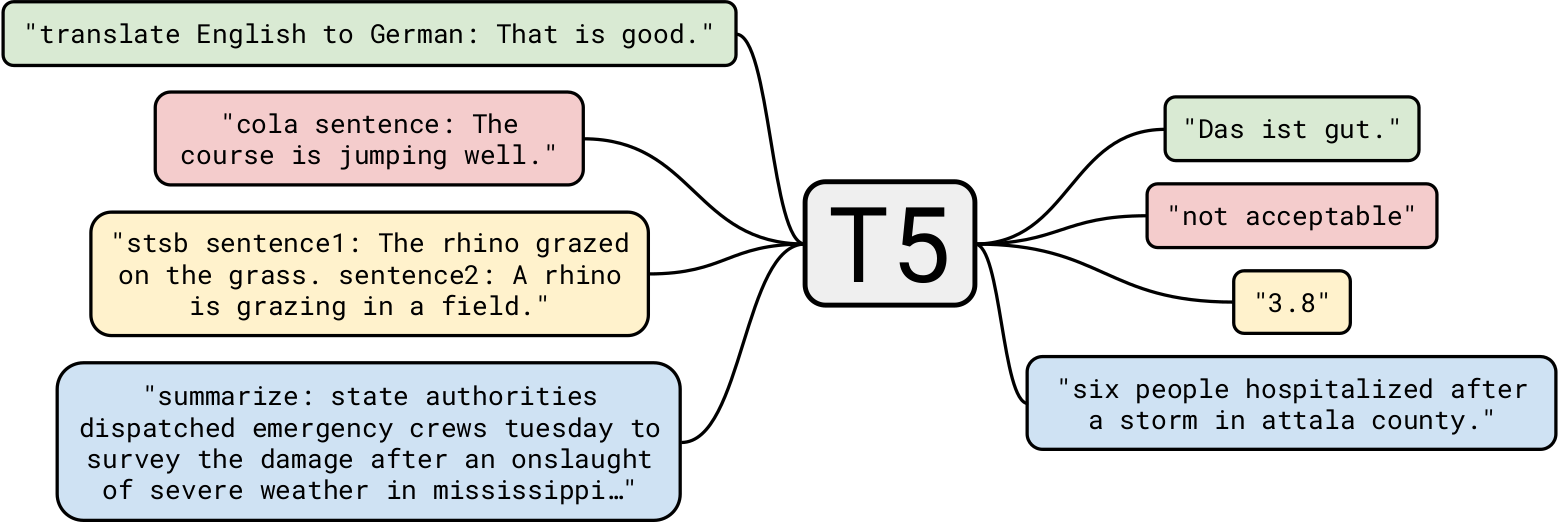
GPT-2 sendo treinado em 40 GB de dados de texto já era impressionante, mas T5 foi treinado em um conjunto de dados de 7 TB . Apesar de ter sido treinado para um número muito, muito grande de iterações, não conseguiu percorrer todo o texto. Embora o T5 possa fazer geração de texto como o GPT-2, nós o usaremos para casos de uso de negócios mais interessantes.

Resumo
Vamos começar com uma tarefa simples: sumarização de texto. Para as empresas de desenvolvimento de IA que desejam criar um aplicativo que resume um artigo de notícias, o T5 é perfeitamente adequado para a tarefa. Por exemplo, entregando este artigo ao T5, aqui estão três resumos diferentes que ele produziu:
| V1 | A próxima temporada do destino 2, a partir de 10 de março, retrabalhará espadas. eles terão energia de recarga usada para alimentar ataques pesados e defesa. o evento do dia dos namorados, crimson days, também está acontecendo este mês. |
| V2 | A Bungie revelou que a próxima temporada de Destino 2 irá retrabalhar dramaticamente as espadas. o estúdio tem sido principalmente tímido sobre o que a temporada irá acarretar. o repensar permitirá que as espadas contornem parcialmente os escudos dos inimigos. |
| V3 | A próxima temporada do destino 2 irá retrabalhar as espadas e deixá-las contornar os escudos dos inimigos. a temporada começa em 10 de março. você pode jogar o destino 2 durante os dias carmesins, um evento do dia dos namorados. |
Como podemos ver, ele fez um trabalho muito bacana ao resumir o artigo. Além disso, cada resumo é diferente dos outros.
Resumir usando modelos pré-treinados tem um enorme potencial de aplicações. Um caso de uso interessante poderia ser gerar um resumo de cada artigo automaticamente e colocá-lo no início para os leitores que querem apenas uma sinopse. Poderia ser levado adiante personalizando o resumo para cada usuário . Por exemplo, se alguns usuários tiverem vocabulários menores, eles poderão receber um resumo com escolhas de palavras menos complicadas. Este é um exemplo muito simples, mas demonstra o poder deste modelo.
Outro caso de uso interessante pode ser usar esses resumos no SEO de um site. Embora o T5 possa ser treinado para gerar automaticamente SEO de alta qualidade, o uso de um resumo pode ajudar imediatamente, sem retreinar o modelo.
Compreensão de leitura
T5 também pode ser usado para compreensão de leitura, por exemplo, respondendo a perguntas de um determinado contexto. Este aplicativo tem casos de uso muito interessantes que veremos mais adiante. Mas vamos começar com alguns exemplos:
| Pergunta | Quem inventou a teoria da evolução? |
| Contexto (Enciclopédia Britânica) | A descoberta de ossos fósseis de grandes mamíferos extintos na Argentina e a observação de inúmeras espécies de tentilhões nas Ilhas Galápagos estavam entre os eventos creditados por estimular o interesse de Darwin em como as espécies se originam. Em 1859 ele publicou A Origem das Espécies por Meio da Seleção Natural, um tratado que estabelece a teoria da evolução e, mais importante, o papel da seleção natural na determinação de seu curso. |
| Responda | darwin |
Não há menção explícita de que Darwin inventou a teoria, mas o modelo usou seu conhecimento existente junto com algum contexto para chegar à conclusão correta.
Que tal um contexto muito pequeno?
| Pergunta | Onde nós fomos? |
| Contexto | No meu aniversário, decidimos visitar as áreas do norte do Paquistão. Foi muito divertido. |
| Responda | áreas do norte do Paquistão |
Ok, isso foi bem fácil. Que tal uma questão filosófica?
| Pergunta | Qual o significado da vida? |
| Contexto (Wikipédia) | O significado da vida como a percebemos é derivado da contemplação filosófica e religiosa e das investigações científicas sobre a existência, os laços sociais, a consciência e a felicidade. Muitas outras questões também estão envolvidas, como significado simbólico, ontologia, valor, propósito, ética, bem e mal, livre arbítrio, a existência de um ou vários deuses, concepções de Deus, a alma e a vida após a morte. As contribuições científicas concentram-se principalmente na descrição de fatos empíricos relacionados sobre o universo, explorando o contexto e os parâmetros relativos ao “como” da vida. |
| Responda | contemplação filosófica e religiosa e investigações científicas sobre existência, laços sociais, consciência e felicidade |
Embora saibamos que a resposta a esta pergunta é muito complicada, T5 tentou chegar a uma resposta muito próxima, mas sensata. Parabéns!
Vamos levá-lo mais longe. Vamos fazer algumas perguntas usando o artigo Engadget mencionado anteriormente como contexto.
| Pergunta | Do que se trata? |
| Responda | o destino 2 irá retrabalhar dramaticamente |
| Pergunta | Quando podemos esperar essa atualização? |
| Responda | 10 de março |
Como você pode ver, a resposta a perguntas contextuais do T5 é muito boa. Um caso de uso de negócios pode ser criar um chatbot contextual para sites que responda a consultas relevantes para a página atual.
Outro caso de uso pode ser pesquisar algumas informações em documentos, por exemplo, fazer perguntas como: “É uma violação de contrato usar um laptop da empresa para um projeto pessoal?” usando um documento legal como contexto. Embora o T5 tenha seus limites, ele é bastante adequado para esse tipo de tarefa.
Os leitores podem se perguntar: por que não usar modelos especializados para cada tarefa? É um bom ponto: a precisão seria muito maior e o custo de implantação de modelos especializados seria muito menor do que o modelo de PNL pré-treinado do T5. Mas a beleza do T5 é precisamente que é “um modelo para governar todos”, ou seja, você pode usar um modelo pré-treinado para quase qualquer tarefa de PNL. Além disso, queremos usar esses modelos prontos para uso, sem retreinamento ou ajuste fino. Portanto, para desenvolvedores que criam um aplicativo que resume artigos diferentes, bem como um aplicativo que responde a perguntas contextuais, o mesmo modelo T5 pode fazer os dois.
Modelos pré-treinados: os modelos de aprendizado profundo que em breve serão onipresentes
Neste artigo, exploramos modelos pré-treinados e como usá-los imediatamente para diferentes casos de uso de negócios. Assim como um algoritmo de ordenação clássico é usado em quase todos os lugares para ordenar problemas, esses modelos pré-treinados serão usados como algoritmos padrão. Está bem claro que o que exploramos foi apenas arranhar a superfície dos aplicativos de PNL, e há muito mais que pode ser feito por esses modelos.
Modelos de aprendizado profundo pré-treinados, como StyleGAN-2 e DeepLabv3, podem potencializar, de maneira semelhante, aplicativos de visão computacional. Espero que tenham gostado deste artigo e aguardo seus comentários abaixo.