
事前にトレーニングされたモデルを最大限に活用する
公開: 2022-03-11特にNLPでリリースされている新しい深層学習モデルのほとんどは、非常に大きく、数億から数百億の範囲のパラメーターを持っています。
十分なアーキテクチャがあれば、モデルが大きいほど、学習能力が高くなります。 したがって、これらの新しいモデルには膨大な学習能力があり、非常に大きなデータセットでトレーニングされています。
そのため、彼らは訓練を受けたデータセットの分布全体を学びます。 それらはこれらのデータセットの圧縮された知識をエンコードしていると言えます。 これにより、これらのモデルを非常に興味深いアプリケーションに使用できます。最も一般的なアプリケーションは転移学習です。 転移学習は、カスタムデータセット/タスクで事前にトレーニングされたモデルを微調整することであり、必要なデータははるかに少なく、モデルは最初からトレーニングする場合に比べて非常に迅速に収束します。
事前にトレーニングされたモデルが将来のアルゴリズムである方法
事前にトレーニングされたモデルはコンピュータービジョンでも使用されますが、この記事では、自然言語処理(NLP)ドメインでの最先端の使用に焦点を当てます。 Transformerアーキテクチャは、これらのモデルで使用されている最も一般的で最も強力なアーキテクチャです。
BERTはNLP転送学習革命を開始しましたが、GPT-2およびT5モデルを調査します。 これらのモデルは事前にトレーニングされています。特定のアプリケーションでモデルを微調整すると、評価指標が大幅に向上しますが、そのまま使用します。つまり、微調整は行いません。
事前トレーニング済みのNLPモデル:OpenAIのGPT-2
GPT-2は、2019年にリリースされたときにかなりの論争を巻き起こしました。テキストの生成に非常に優れていたため、メディアの注目を集め、AIの将来について多くの質問を投げかけました。
40 GBのテキストデータでトレーニングされたGPT-2は、インターネットの断面からの大量の圧縮された知識を含む非常に大きなモデルです。
GPT-2には多くの潜在的なユースケースがあります。 文の確率を予測するために使用できます。 これは、テキストの自動修正に使用できます。 次に、単語予測を直接使用して、コードを記述したり、一般的なテキストを記述したりするためのIDEのオートコンプリートコンポーネント(Visual Studio CodeやPyCharmなど)を構築できます。 自動テキスト生成に使用し、大量のテキストを自然言語分析に使用できます。
テキスト生成
一貫性のあるテキストを生成するGPT-2のような事前にトレーニングされたモデルの能力は非常に印象的です。 接頭辞テキストを付けて、次の単語、フレーズ、または文を生成するように依頼できます。
ユースケースの例は、製品レビューデータセットを生成して、肯定的なレビューと否定的なレビューで一般的に使用される単語のタイプを確認することです。
いくつかの例を見てみましょう。正の接頭辞「この映画が本当に気に入りました」から始めた場合に得られるものから始めましょう。
| サンプル1 | 絶え間ない危険にさらされているキャラクターの感情と、これらのイベントによって彼の内面の恐怖がゆっくりと克服された方法が大好きでした。 彼が生き残ることにとても集中していることも大好きでした。 しばらくの間でも、バットマンvsスーパーマンの何かが再び現れているように感じました。とにかく敵が最終的に現れることを常に知っていたからです:)エンディングのテーマも本当に私に固執しました…つまり、彼らはそうしなければなりませんでした… |
| サンプル2 | それは私がやりたかったことを正確に実行しました。とても楽しいものでした。 キャストは素晴らしく、IMDBで他のすべてをすでに見た後、ストーリーはこれまでのところ理にかなっています。 彼らの「力」(またはその欠如)のために太古の昔から地下都市にいることについてのヒントがありますが、彼らは実際にはそれほど多くを語っていません...でも…。それは… |
ご覧のとおり、レビューという単語は接頭辞のどこにもありませんでしたが、ほとんどのレビューはタイトルの後にレビューの本文が続くため、モデルはその分布に適応する必要がありました。 バットマンvsスーパーマンへの言及にも注意してください。
別の例を見てみましょう。 映画レビューの代わりに、「ゴミ箱の商品!」という負の接頭辞を使用して商品レビューを生成しようとします。 買わないで。"
| サンプル1 | また、これを庭や芝生の肥料として使用しないでください。魚や鳥が摂取すると、深刻な水害を引き起こす可能性があります。 Petsmart、PetSmart、Safewayなどの「良い」名前が多すぎる有機食料品店でオンラインで入手できるペットフードに農薬が含まれている可能性があるため、注意して使用してください。食品廃棄物はどの程度毒性がありますか。 廃棄物はかなりの量をもたらす可能性があります-非常に… |
| サンプル2 | 誰もあなたにそのゴミを二度と与えないでしょう。 あなた自身とあなたのビジネスを支持し、将来的にいくらかのお金や便利さを節約するためだけにそれを購入する前に片付けてください。1/2オンスボトルプラスチック食品貯蔵包装+1パック#1636370105702615(P、3ml)$7今すぐ購入これらのボトルはどの小売店でも購入できますが、入手方法は次のとおりです… |
繰り返しになりますが、プレフィックスは製品レビューのタイトルとして推測できるため、モデルはそのパターンに従ってテキストの生成を開始します。 GPT-2は、このような任意のタイプのテキストを生成できます。
「WriteWithTransformer」のライブデモと同様に、GoogleColabノートブックを実験に使用する準備ができています。
質問応答
はい、GPT-2はウェブ上でトレーニングされているため、2019年までにオンラインで公開された多くの人間の知識を「知っています」。状況に応じた質問にも使用できますが、「」の明示的な形式に従う必要があります。質問:X、回答:」オートコンプリートを試行する前に。 しかし、モデルに質問に答えさせると、かなり漠然とした答えが出力される可能性があります。 知識をテストするために自由形式の質問に答えるように強制しようとすると、次のようになります。
| サンプル1 | 質問:進化論を発明したのは誰ですか? 回答:進化論は、1859年にチャールズダーウィンによって最初に提案されました。 |
| サンプル2 | 質問:人間は何本の歯を持っていますか? 回答:人間には21本の歯があります。 |
ご覧のとおり、事前にトレーニングされたモデルは、最初の質問に対してかなり詳細な回答を提供しました。 第二に、それは最善を尽くしましたが、それはグーグル検索と比較しません。
GPT-2が大きな可能性を秘めていることは明らかです。 微調整することで、上記の例にはるかに高い精度で使用できます。 しかし、私たちが評価している事前に訓練されたGPT-2でさえ、それでもそれほど悪くはありません。
事前トレーニング済みのNLPモデル:GoogleのT5
GoogleのT5は、これまでで最も先進的な自然言語モデルの1つです。 これは、一般的なTransformerモデルに関する以前の作業に基づいて構築されています。 エンコーダーブロックのみを備えたBERTやデコーダーブロックのみを備えたGPT-2とは異なり、T5は両方を使用します。
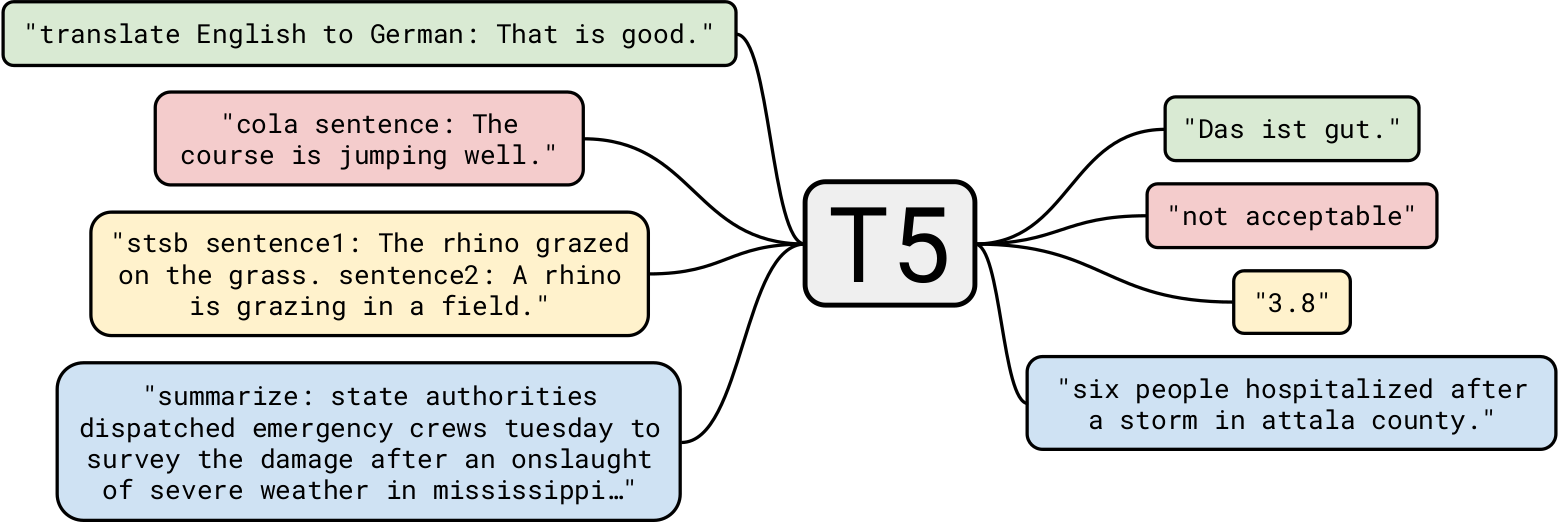
40 GBのテキストデータでトレーニングされたGPT-2はすでに印象的でしたが、 T5は7TBのデータセットでトレーニングされました。 非常に多くの反復のためにトレーニングされたにもかかわらず、すべてのテキストを通過することはできませんでした。 T5はGPT-2のようなテキスト生成を行うことができますが、より興味深いビジネスユースケースに使用します。

要約
簡単なタスクから始めましょう:テキストの要約。 ニュース記事を要約したアプリを作成したいAI開発会社にとって、T5はそのタスクに最適です。 たとえば、この記事をT5に渡すと、次の3つの要約が作成されます。
| V1 | 3月10日から始まるdestiny2の次のシーズンは剣を作り直します。 彼らは、激しい攻撃と防御の両方に電力を供給するために使用される再充電エネルギーを持っています。 バレンタインデーのイベントである深紅の日も今月開催されます。 |
| V2 | バンジーは、運命2の次のシーズンが劇的に剣を作り直すことを明らかにしました。 スタジオは、シーズンが何を伴うかについてほとんど気が狂っていました。 再考すると、剣がaiの敵の盾を部分的にバイパスするようになります。 |
| V3 | Destiny 2の次のシーズンは剣を作り直し、敵の盾を迂回させます。 シーズンは3月10日から始まります。 バレンタインデーのイベントである深紅の日に運命2をプレイできます。 |
ご覧のとおり、記事を要約するというかなり気の利いた仕事をしました。 また、各要約は他の要約とは異なります。
事前にトレーニングされたモデルを使用して要約すると、大きな潜在的なアプリケーションがあります。 興味深いユースケースの1つは、すべての記事の要約を自動的に生成し、概要が必要な読者のためにそれを最初に配置することです。 各ユーザーの要約をパーソナライズすることで、さらに理解を深めることができます。 たとえば、一部のユーザーの語彙が少ない場合は、単語の選択肢がそれほど複雑ではない要約が提供される可能性があります。 これは非常に単純な例ですが、このモデルの威力を示しています。
もう1つの興味深いユースケースは、WebサイトのSEOでそのような要約を使用することです。 T5は、非常に高品質のSEOを自動的に生成するようにトレーニングできますが、要約を使用すると、モデルを再トレーニングしなくても、すぐに役立つ場合があります。
読解
T5は、読解にも使用できます。たとえば、特定のコンテキストからの質問に答えることができます。 このアプリケーションには、後で説明する非常に興味深いユースケースがあります。 しかし、いくつかの例から始めましょう。
| 質問 | 進化論を発明したのは誰ですか? |
| 環境 (ブリタニカ百科事典) | アルゼンチンで絶滅した大型哺乳類から化石の骨が発見され、ガラパゴス諸島で多数のアトリが観察されたことは、種の起源に対するダーウィンの関心を刺激したことで知られています。 1859年に彼は、進化論、そして最も重要なこととして、その進路を決定する上での自然淘汰の役割を確立する論文である「自然淘汰による種の起源について」を発表しました。 |
| 答え | ダーウィン |
ダーウィンが理論を発明したという明確な言及はありませんが、モデルは正しい結論に到達するために、いくつかのコンテキストとともに既存の知識を使用しました。
非常に小さなコンテキストはどうですか?
| 質問 | どこに行ったの? |
| 環境 | 私の誕生日に、私たちはパキスタンの北部を訪問することにしました。 とても楽しかったです。 |
| 答え | パキスタン北部 |
さて、それはかなり簡単でした。 哲学的な質問はどうですか?
| 質問 | 人生の意味とは? |
| 環境 (ウィキペディア) | 私たちが知覚する人生の意味は、存在、社会的つながり、意識、幸福についての哲学的および宗教的な熟考、および科学的な調査から導き出されます。 象徴的な意味、存在論、価値、目的、倫理、善と悪、自由意志、1つまたは複数の神の存在、神の概念、魂、来世など、他の多くの問題も関係しています。 科学的貢献は、主に宇宙に関する関連する経験的事実を説明し、生命の「方法」に関する文脈とパラメーターを探求することに焦点を当てています。 |
| 答え | 存在、社会的つながり、意識、幸福についての哲学的および宗教的熟考、および科学的調査 |
この質問への答えは非常に複雑であることはわかっていますが、T5は非常に近いが賢明な答えを考え出そうとしました。 称賛!
さらに進んでみましょう。 前述のEngadgetの記事をコンテキストとして使用して、いくつか質問してみましょう。
| 質問 | これは何ですか? |
| 答え | Destiny2は劇的に作り直されます |
| 質問 | このアップデートはいつ期待できますか? |
| 答え | 3月10日 |
ご覧のとおり、T5のコンテキスト質問応答は非常に優れています。 ビジネスのユースケースの1つは、現在のページに関連するクエリに応答するWebサイト用のコンテキストチャットボットを構築することです。
別の使用例は、ドキュメントからいくつかの情報を検索することです。たとえば、「会社のラップトップを個人的なプロジェクトに使用することは契約違反ですか?」などの質問をします。 法的文書をコンテキストとして使用します。 T5には限界がありますが、このタイプのタスクには非常に適しています。
読者は疑問に思うかもしれません、なぜ各タスクに特化したモデルを使用しませんか? これは良い点です。T5の事前トレーニング済みNLPモデルよりも、精度がはるかに高く、特殊なモデルの展開コストがはるかに低くなります。 しかし、T5の優れている点は、「すべてを統治する1つのモデル」であるということです。つまり、ほとんどすべてのNLPタスクに1つの事前トレーニング済みモデルを使用できます。 さらに、再トレーニングや微調整を行わずに、これらのモデルをそのまま使用したいと考えています。 したがって、さまざまな記事を要約するアプリや、状況に応じた質問応答を行うアプリを作成する開発者にとって、同じT5モデルで両方を実行できます。
事前トレーニング済みモデル:まもなくユビキタスになるディープラーニングモデル
この記事では、事前にトレーニングされたモデルと、さまざまなビジネスユースケースでそれらをすぐに使用する方法について説明しました。 従来の並べ替えアルゴリズムがほとんどすべての場所で並べ替えの問題に使用されるように、これらの事前トレーニング済みモデルは標準アルゴリズムとして使用されます。 私たちが調査したのはNLPアプリケーションの表面をかじっただけであり、これらのモデルで実行できることは他にもたくさんあります。
StyleGAN-2やDeepLabv3のような事前トレーニング済みの深層学習モデルは、同様の方法で、コンピュータービジョンのアプリケーションに電力を供給することができます。 この記事を楽しんでいただければ幸いです。以下のコメントをお待ちしております。