
Mendapatkan Hasil Maksimal dari Model yang Sudah Terlatih
Diterbitkan: 2022-03-11Sebagian besar model pembelajaran mendalam baru yang dirilis, terutama di NLP, berukuran sangat, sangat besar: Mereka memiliki parameter mulai dari ratusan juta hingga puluhan miliar.
Mengingat arsitektur yang cukup baik, semakin besar modelnya, semakin banyak pula kapasitas belajar yang dimilikinya. Dengan demikian, model-model baru ini memiliki kapasitas belajar yang besar dan dilatih pada kumpulan data yang sangat, sangat besar.
Karena itu, mereka mempelajari seluruh distribusi kumpulan data tempat mereka dilatih. Orang dapat mengatakan bahwa mereka mengkodekan pengetahuan terkompresi dari kumpulan data ini. Hal ini memungkinkan model ini digunakan untuk aplikasi yang sangat menarik—yang paling umum adalah transfer learning. Pembelajaran transfer adalah menyempurnakan model pra-pelatihan pada kumpulan data/tugas khusus, yang membutuhkan jauh lebih sedikit data, dan model menyatu dengan sangat cepat dibandingkan dengan pelatihan dari awal.
Bagaimana Model Pra-terlatih Merupakan Algoritma Masa Depan
Meskipun model pra-terlatih juga digunakan dalam visi komputer, artikel ini akan fokus pada penggunaan mutakhirnya dalam domain pemrosesan bahasa alami (NLP). Arsitektur transformator adalah arsitektur paling umum dan paling kuat yang digunakan dalam model ini.
Meskipun BERT memulai revolusi pembelajaran transfer NLP, kami akan mengeksplorasi model GPT-2 dan T5. Model-model ini telah dilatih sebelumnya—menyesuaikannya pada aplikasi tertentu akan menghasilkan metrik evaluasi yang jauh lebih baik, tetapi kami akan menggunakannya secara langsung, yaitu, tanpa penyempurnaan.
Model NLP yang telah dilatih sebelumnya: GPT-2 OpenAI
GPT-2 cukup menimbulkan kontroversi ketika dirilis pada tahun 2019. Karena sangat bagus dalam menghasilkan teks, GPT-2 cukup menarik perhatian media dan menimbulkan banyak pertanyaan mengenai masa depan AI.
Dilatih pada data tekstual 40 GB, GPT-2 adalah model yang sangat besar yang berisi sejumlah besar pengetahuan terkompresi dari berbagai bagian internet.
GPT-2 memiliki banyak kasus penggunaan potensial. Ini dapat digunakan untuk memprediksi probabilitas sebuah kalimat. Ini, pada gilirannya, dapat digunakan untuk koreksi otomatis teks. Selanjutnya, prediksi kata dapat langsung digunakan untuk membangun komponen pelengkapan otomatis untuk IDE (seperti Visual Studio Code atau PyCharm) untuk menulis kode serta menulis teks umum. Kami akan menggunakannya untuk pembuatan teks otomatis, dan sejumlah besar teks dapat digunakan untuk analisis bahasa alami.
Pembuatan Teks
Kemampuan model pra-terlatih seperti GPT-2 untuk menghasilkan teks yang koheren sangat mengesankan. Kita dapat memberinya teks awalan dan memintanya untuk menghasilkan kata, frasa, atau kalimat berikutnya.
Contoh kasus penggunaan adalah menghasilkan kumpulan data ulasan produk untuk melihat jenis kata mana yang umumnya digunakan dalam ulasan positif versus ulasan negatif.
Mari kita lihat beberapa contoh, dimulai dengan apa yang kita dapatkan jika kita mulai dengan awalan positif, “Sangat menyukai film ini!”
| Contoh 1 | Mencintai emosi karakter karena berada dalam bahaya terus-menerus, dan bagaimana ketakutan batinnya perlahan-lahan diatasi oleh peristiwa ini. Juga menyukai bahwa dia sangat fokus untuk bertahan hidup; bahkan untuk sementara rasanya seperti sesuatu yang keluar dari Batman v Superman muncul lagi sekarang karena Anda selalu tahu musuh Anda akan muncul pada akhirnya :) Tema akhir benar-benar menempel dengan saya juga… Maksudku ya mereka memang harus… |
| Contoh 2 | Itu melakukan persis apa yang saya inginkan, hanya sangat menyenangkan. Pemerannya luar biasa dan ceritanya masuk akal sejauh ini setelah melihat yang lainnya sudah ada di IMDB. Ada petunjuk tentang berada di kota bawah tanah sejak dahulu kala karena "kekuatan" mereka (atau kekurangannya) tetapi mereka tidak benar-benar memberi tahu banyak ... Saya pikir itu lebih seperti satu misteri besar daripada beberapa aspek lain yang datang bersama saya untuk saat ini meskipun …. Seharusnya … |
Seperti yang Anda lihat, kata review tidak ada di awalan, tetapi karena sebagian besar ulasan adalah judul yang diikuti oleh isi ulasan, ini memaksa model untuk beradaptasi dengan distribusi itu. Perhatikan juga referensi Batman v Superman .
Mari kita lihat contoh lain. Alih-alih ulasan film, kami akan mencoba membuat ulasan produk menggunakan awalan negatif, “Produk sampah! Jangan Beli."
| Contoh 1 | Dan tolong, JANGAN mencoba menggunakan ini sebagai pupuk untuk kebun atau halaman Anda – ini akan menyebabkan kerusakan air yang serius jika tertelan oleh ikan dan burung. Gunakan dengan hati-hati karena kemungkinan pestisida ada dalam makanan hewan peliharaan yang tersedia online di toko bahan makanan organik seperti nama yang terlalu "baik" seperti Petsmart, PetSmart & Safeway. Seberapa beracun limbah makanan? Produk limbah dapat memberikan kontribusi dalam jumlah yang signifikan - cukup sehingga bahkan sangat… |
| Contoh 2 | Tidak ada yang akan memberi Anda sepotong sampah itu lagi. Bantulah diri Anda dan bisnis Anda dan bersihkan sebelum membelinya hanya untuk menghemat uang atau kenyamanan di masa depan.1/2 oz Botol Kemasan Penyimpanan Makanan Plastik + 1 bungkus #1636370105702615 (P, 3ml) $7 Beli Sekarang Anda dapat membeli botol-botol ini di toko ritel mana pun, tetapi berikut adalah cara… |
Sekali lagi, awalan dapat disimpulkan sebagai judul ulasan produk, sehingga model mulai menghasilkan teks mengikuti pola itu. GPT-2 dapat menghasilkan semua jenis teks seperti ini.
Notebook Google Colab siap digunakan untuk eksperimen, begitu juga dengan demo langsung "Tulis Dengan Transformer".
Pertanyaan Menjawab
Ya, karena GPT-2 dilatih di web, ia "mengetahui" banyak pengetahuan manusia yang telah dipublikasikan secara online hingga 2019. Ini dapat bekerja untuk pertanyaan kontekstual juga, tetapi kita harus mengikuti format eksplisit " Pertanyaan: X, Jawab:” sebelum membiarkannya mencoba melengkapi otomatis. Tetapi jika kita memaksa model untuk menjawab pertanyaan kita, itu mungkin menghasilkan jawaban yang agak kabur. Inilah yang terjadi ketika mencoba memaksanya untuk menjawab pertanyaan terbuka untuk menguji pengetahuannya:
| Contoh 1 | Pertanyaan: Siapa yang menemukan teori evolusi? Jawaban: Teori evolusi pertama kali dikemukakan oleh Charles Darwin pada tahun 1859. |
| Contoh 2 | Pertanyaan: Berapa banyak gigi yang dimiliki manusia? Jawaban: Manusia memiliki 21 gigi. |
Seperti yang bisa kita lihat, model pra-terlatih memberikan jawaban yang cukup rinci untuk pertanyaan pertama. Untuk yang kedua, ia mencoba yang terbaik, tetapi tidak dapat dibandingkan dengan Google Penelusuran.
Jelas bahwa GPT-2 memiliki potensi besar. Menyesuaikannya dengan baik, dapat digunakan untuk contoh yang disebutkan di atas dengan akurasi yang jauh lebih tinggi. Tetapi bahkan GPT-2 pra-terlatih yang kami evaluasi masih tidak terlalu buruk.
Model NLP pra-terlatih: Google T5
T5 Google adalah salah satu model bahasa alami paling canggih hingga saat ini. Ini dibangun di atas pekerjaan sebelumnya pada model Transformer secara umum. Tidak seperti BERT yang hanya memiliki blok encoder, dan GPT-2 yang hanya memiliki blok dekoder, T5 menggunakan keduanya .
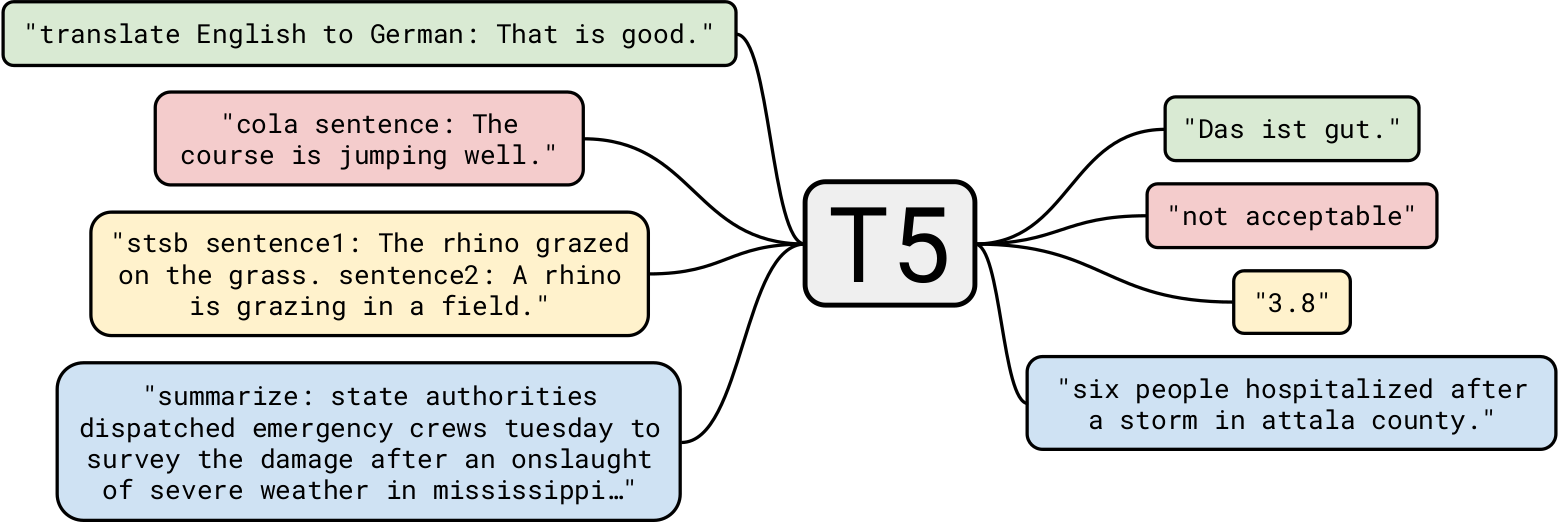
GPT-2 yang dilatih pada 40 GB data teks sudah mengesankan, tetapi T5 dilatih pada set data 7 TB . Meskipun dilatih untuk jumlah iterasi yang sangat, sangat besar, ia tidak dapat melewati semua teks. Meskipun T5 dapat melakukan pembuatan teks seperti GPT-2, kami akan menggunakannya untuk kasus penggunaan bisnis yang lebih menarik.

Ringkasan
Mari kita mulai dengan tugas sederhana: peringkasan teks. Bagi perusahaan pengembang AI yang ingin membuat aplikasi yang merangkum artikel berita, T5 sangat cocok untuk tugas tersebut. Misalnya, memberikan artikel ini ke T5, berikut adalah tiga ringkasan berbeda yang dihasilkannya:
| V1 | musim depan takdir 2, mulai 10 Maret, akan mengerjakan ulang pedang. mereka akan memiliki energi pengisian ulang yang digunakan untuk memberi kekuatan pada serangan berat dan penjagaan. acara hari valentine, hari merah, juga terjadi bulan ini. |
| V2 | bungie telah mengungkapkan bahwa musim berikutnya dari takdir 2 akan secara dramatis mengolah ulang pedang. studio sebagian besar malu-malu tentang apa musim akan memerlukan. pemikiran ulang akan membiarkan sebagian pedang melewati perisai musuh. |
| V3 | musim berikutnya takdir 2 akan mengerjakan ulang pedang dan membiarkannya melewati perisai musuh. musim dimulai 10 Maret. Anda dapat memainkan takdir 2 selama hari-hari merah, acara hari valentine. |
Seperti yang bisa kita lihat, ia telah melakukan pekerjaan yang cukup bagus dalam meringkas artikel. Juga, setiap ringkasan berbeda dari yang lain.
Meringkas menggunakan model pra-terlatih memiliki aplikasi potensial yang sangat besar. Salah satu kasus penggunaan yang menarik adalah membuat ringkasan setiap artikel secara otomatis dan meletakkannya di awal untuk pembaca yang hanya menginginkan sinopsis. Ini dapat diambil lebih jauh dengan mempersonalisasi ringkasan untuk setiap pengguna . Misalnya, jika beberapa pengguna memiliki kosakata yang lebih kecil, mereka dapat disajikan ringkasan dengan pilihan kata yang tidak terlalu rumit. Ini adalah contoh yang sangat sederhana, namun menunjukkan kekuatan model ini.
Kasus penggunaan lain yang menarik adalah menggunakan ringkasan seperti itu dalam SEO situs web. Meskipun T5 dapat dilatih untuk menghasilkan SEO berkualitas sangat tinggi secara otomatis, menggunakan ringkasan mungkin membantu, tanpa melatih ulang modelnya.
Pemahaman membaca
T5 juga dapat digunakan untuk pemahaman bacaan, misalnya menjawab pertanyaan dari konteks tertentu. Aplikasi ini memiliki kasus penggunaan yang sangat menarik yang akan kita lihat nanti. Tapi mari kita mulai dengan beberapa contoh:
| Pertanyaan | Siapa penemu teori evolusi? |
| Konteks (Encyclopadia Britannica) | Penemuan tulang fosil dari mamalia besar yang telah punah di Argentina dan pengamatan berbagai spesies kutilang di Kepulauan Galapagos termasuk di antara peristiwa-peristiwa yang dikreditkan dengan merangsang minat Darwin tentang bagaimana spesies berasal. Pada tahun 1859 ia menerbitkan On the Origin of Species by Means of Natural Selection, sebuah risalah yang menetapkan teori evolusi dan, yang paling penting, peran seleksi alam dalam menentukan jalannya. |
| Menjawab | darwin |
Tidak disebutkan secara eksplisit bahwa Darwin menemukan teori tersebut, tetapi model tersebut menggunakan pengetahuan yang ada bersama dengan beberapa konteks untuk mencapai kesimpulan yang tepat.
Bagaimana dengan konteks yang sangat kecil?
| Pertanyaan | Kemana kita pergi? |
| Konteks | Pada hari ulang tahun saya, kami memutuskan untuk mengunjungi daerah utara Pakistan. Itu benar-benar menyenangkan. |
| Menjawab | wilayah utara pakistan |
Oke, itu cukup mudah. Bagaimana dengan pertanyaan filosofis?
| Pertanyaan | apa arti kehidupan? |
| Konteks (Wikipedia) | Makna hidup seperti yang kita rasakan berasal dari perenungan filosofis dan religius, dan penyelidikan ilmiah tentang keberadaan, ikatan sosial, kesadaran, dan kebahagiaan. Banyak masalah lain yang juga terlibat, seperti makna simbolis, ontologi, nilai, tujuan, etika, baik dan jahat, kehendak bebas, keberadaan satu atau beberapa dewa, konsepsi tentang Tuhan, jiwa, dan kehidupan setelah kematian. Kontribusi ilmiah berfokus terutama pada penggambaran fakta empiris terkait tentang alam semesta, menjelajahi konteks dan parameter tentang "bagaimana" kehidupan. |
| Menjawab | perenungan filosofis dan religius, dan penyelidikan ilmiah tentang keberadaan, ikatan sosial, kesadaran, dan kebahagiaan |
Meskipun kami tahu jawaban atas pertanyaan ini sangat rumit, T5 mencoba memberikan jawaban yang sangat dekat, namun masuk akal. Pujian!
Mari kita ambil lebih jauh. Mari kita ajukan beberapa pertanyaan menggunakan artikel Engadget yang disebutkan sebelumnya sebagai konteksnya.
| Pertanyaan | Tentang apakah ini? |
| Menjawab | takdir 2 akan dikerjakan ulang secara dramatis |
| Pertanyaan | Kapan kita bisa mengharapkan pembaruan ini? |
| Menjawab | 10 Maret |
Seperti yang Anda lihat, jawaban pertanyaan kontekstual T5 sangat bagus. Salah satu kasus penggunaan bisnis adalah membangun chatbot kontekstual untuk situs web yang menjawab pertanyaan yang relevan dengan halaman saat ini.
Kasus penggunaan lainnya adalah untuk mencari beberapa informasi dari dokumen, misalnya, mengajukan pertanyaan seperti, “Apakah penggunaan laptop perusahaan untuk proyek pribadi merupakan pelanggaran kontrak?” menggunakan dokumen hukum sebagai konteksnya. Meskipun T5 memiliki batasannya, T5 cukup cocok untuk jenis tugas ini.
Pembaca mungkin bertanya-tanya, Mengapa tidak menggunakan model khusus untuk setiap tugas? Ini poin yang bagus: Akurasinya akan jauh lebih tinggi dan biaya penerapan model khusus akan jauh lebih rendah daripada model NLP pra-terlatih T5. Tapi keindahan T5 justru bahwa itu adalah "satu model untuk memerintah mereka semua," yaitu, Anda dapat menggunakan satu model pra-terlatih untuk hampir semua tugas NLP. Selain itu, kami ingin menggunakan model ini secara langsung, tanpa pelatihan ulang atau penyempurnaan. Jadi untuk pengembang yang membuat aplikasi yang merangkum berbagai artikel, serta aplikasi yang menjawab pertanyaan kontekstual, model T5 yang sama dapat melakukan keduanya.
Model Pra-terlatih: Model Pembelajaran Mendalam yang Akan Segera Ada di Mana-mana
Dalam artikel ini, kami menjelajahi model pra-terlatih dan cara menggunakannya di luar kotak untuk kasus penggunaan bisnis yang berbeda. Sama seperti algoritme pengurutan klasik yang digunakan hampir di semua tempat untuk masalah pengurutan, model pra-pelatihan ini akan digunakan sebagai algoritme standar. Cukup jelas bahwa apa yang kami jelajahi hanyalah menggores permukaan aplikasi NLP, dan masih banyak lagi yang dapat dilakukan oleh model ini.
Model pembelajaran mendalam yang telah dilatih sebelumnya seperti StyleGAN-2 dan DeepLabv3 dapat memberi daya, dengan cara yang sama, aplikasi visi komputer. Saya harap Anda menikmati artikel ini dan menantikan komentar Anda di bawah.