
Получение максимальной отдачи от предварительно обученных моделей
Опубликовано: 2022-03-11Большинство новых выпускаемых моделей глубокого обучения, особенно в НЛП, очень и очень большие: их параметры варьируются от сотен миллионов до десятков миллиардов.
При достаточно хорошей архитектуре, чем больше модель, тем больше у нее возможностей для обучения. Таким образом, эти новые модели обладают огромным потенциалом обучения и обучаются на очень и очень больших наборах данных.
Из-за этого они изучают все распределение наборов данных, на которых они обучаются. Можно сказать, что они кодируют сжатые знания об этих наборах данных. Это позволяет использовать эти модели для очень интересных приложений, наиболее распространенным из которых является трансферное обучение. Трансферное обучение — это тонкая настройка предварительно обученных моделей на пользовательских наборах данных/задачах, для чего требуется гораздо меньше данных, а модели сходятся очень быстро по сравнению с обучением с нуля.
Как предварительно обученные модели являются алгоритмами будущего
Хотя предварительно обученные модели также используются в компьютерном зрении, в этой статье основное внимание будет уделено их передовому использованию в области обработки естественного языка (NLP). Архитектура трансформатора является наиболее распространенной и наиболее мощной архитектурой, используемой в этих моделях.
Хотя BERT начал революцию в обучении переносу в НЛП, мы рассмотрим модели GPT-2 и T5. Эти модели предварительно обучены — их тонкая настройка для конкретных приложений приведет к гораздо лучшим показателям оценки, но мы будем использовать их «из коробки», т. е. без тонкой настройки.
Предварительно обученные модели НЛП: OpenAI GPT-2
GPT-2 вызвал много споров, когда был выпущен в 2019 году. Поскольку он очень хорошо генерировал текст, он привлек внимание средств массовой информации и вызвал много вопросов относительно будущего ИИ.
GPT-2, обученный на 40 ГБ текстовых данных, представляет собой очень большую модель, содержащую огромное количество сжатых знаний из разных частей Интернета.
GPT-2 имеет множество потенциальных вариантов использования. Его можно использовать для предсказания вероятности предложения. Это, в свою очередь, можно использовать для автокоррекции текста. Далее, прогнозирование слов можно напрямую использовать для создания компонента автозаполнения для IDE (например, Visual Studio Code или PyCharm) для написания кода, а также для написания обычного текста. Мы будем использовать его для автоматической генерации текста, а большой корпус текста можно использовать для анализа естественного языка.
Генерация текста
Способность предварительно обученной модели, такой как GPT-2, генерировать связный текст очень впечатляет. Мы можем дать ему текст префикса и попросить сгенерировать следующее слово, фразу или предложение.
Пример использования — создание набора данных отзывов о продуктах, чтобы увидеть, какие типы слов обычно используются в положительных отзывах, а какие — в отрицательных.
Давайте рассмотрим несколько примеров, начиная с того, что мы получим, если начнем с положительной приставки «Очень понравился этот фильм!»
| Образец 1 | Понравились эмоции персонажа при постоянной опасности и то, как эти события постепенно преодолевали его внутренние страхи. Также понравилось, что он так сосредоточен на выживании; даже какое-то время мне казалось, что что-то из «Бэтмена против Супермена» снова и снова появляется каждый раз, потому что вы всегда знали, что ваш враг все равно когда-нибудь появится :) Тема финала действительно зацепила меня… Я имею в виду, да, они действительно должны были… |
| Образец 2 | Он сделал именно то, что я хотел, просто очень весело. Актерский состав был потрясающим, и история имеет смысл, учитывая, что все остальное уже есть на IMDB. Есть намёки на то, что они были в подземном городе с незапамятных времён из-за их «силы» (или её отсутствия), но на самом деле они мало что говорят… Я думаю, это больше похоже на одну большую тайну, чем на какие-то другие аспекты, которые приходят вместе со мной на данный момент. хотя….Предполагается… |
Как видите, слова « обзор » не было нигде в префиксе, но поскольку большинство обзоров представляют собой заголовки, за которыми следует основная часть обзора, это заставило модель адаптироваться к этому дистрибутиву. Также обратите внимание на отсылку к « Бэтмен против Супермена» .
Давайте посмотрим на другой пример. Вместо обзора фильма мы попробуем создать обзор продукта, используя отрицательный префикс «Отстойный продукт! Не покупай."
| Образец 1 | И, пожалуйста, НЕ пытайтесь использовать это в качестве удобрения для ваших садов или газонов — это может привести к серьезному повреждению воды, если его проглотят рыбы и птицы. Используйте с осторожностью из-за возможности того, что пестициды могут присутствовать в кормах для домашних животных, доступных в Интернете в магазинах органических продуктов, таких как слишком «хорошие» названия, такие как Petsmart, PetSmart и Safeway. Насколько токсичны пищевые отходы? Отходы могут вносить значительные суммы — настолько, что даже очень… |
| Образец 2 | Никто больше никогда не даст вам кусок этого мусора. Просто сделайте одолжение себе и своему бизнесу и очистите его перед покупкой, чтобы сэкономить деньги или удобство в будущем. Бутылка 1/2 унции Пластиковая упаковка для хранения пищевых продуктов + 1 упаковка № 1636370105702615 (P, 3 мл) $ 7 Купить сейчас Вы можете купить эти бутылки в любом розничном магазине, но вот как получить… |
Опять же, префикс может быть выведен как заголовок обзора продукта, поэтому модель начинает генерировать текст по этому шаблону. GPT-2 может генерировать текст любого типа.
Блокнот Google Colab готов к использованию для экспериментов, как и живая демонстрация Write With Transformer.
Вопрос Ответ
Да, поскольку GPT-2 обучается в сети, он «знает» множество человеческих знаний, которые были опубликованы в сети до 2019 года. Он может работать и для контекстных вопросов, но нам придется следовать явному формату « Вопрос: X, Ответ:», прежде чем разрешить автозаполнение. Но если мы заставим модель отвечать на наш вопрос, она может дать довольно расплывчатый ответ. Вот что происходит, когда его пытаются заставить отвечать на открытые вопросы, чтобы проверить его знания:
| Образец 1 | Вопрос: Кто изобрел теорию эволюции? Ответ: Теория эволюции была впервые предложена Чарльзом Дарвином в 1859 году. |
| Образец 2 | Вопрос: Сколько зубов у человека? Ответ: У человека 21 зуб. |
Как видим, предварительно обученная модель дала довольно развернутый ответ на первый вопрос. Для второго старался на славу, но с поиском Google не идет ни в какое сравнение.
Понятно, что GPT-2 имеет огромный потенциал. Доработав его, его можно использовать для приведенных выше примеров с гораздо большей точностью. Но даже предварительно обученный GPT-2, который мы оцениваем, все еще не так уж плох.
Предварительно обученные модели НЛП: Google T5
Google T5 — одна из самых передовых моделей естественного языка на сегодняшний день. Он основан на предыдущей работе над моделями Transformer в целом. В отличие от BERT, у которого были только блоки энкодера, и GPT-2, у которого были только блоки декодера, T5 использует оба .

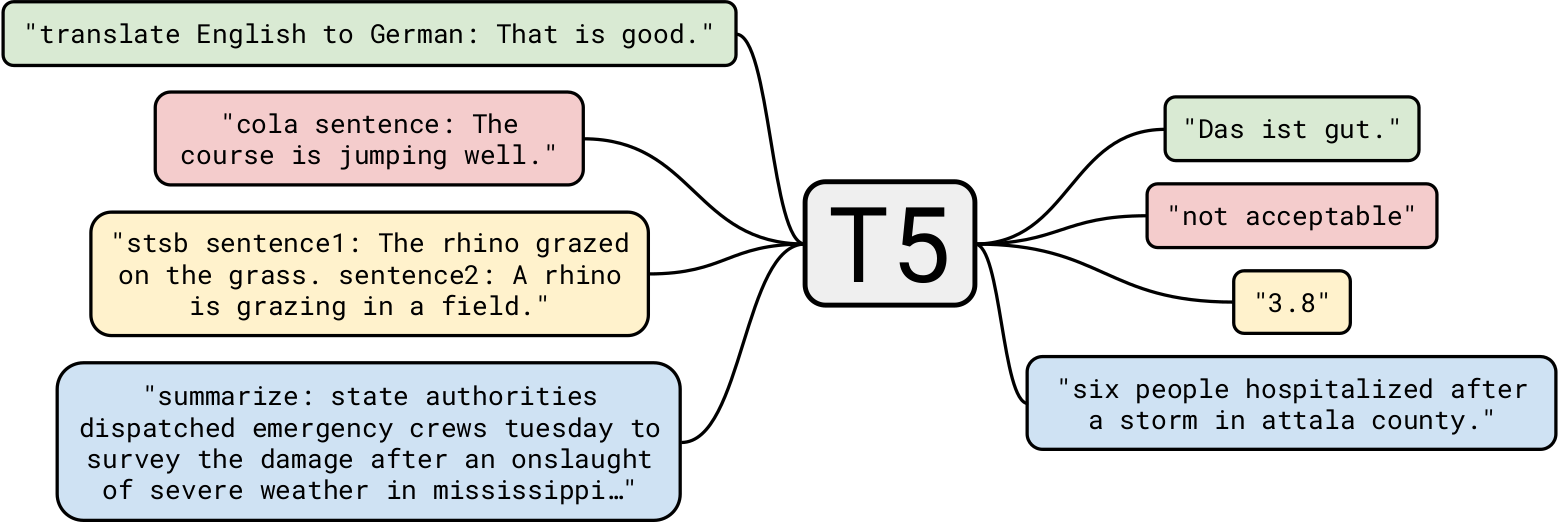
Обучение GPT-2 на 40 ГБ текстовых данных уже впечатляло, а вот T5 обучался на наборе данных в 7 ТБ . Несмотря на то, что он был обучен на очень и очень большое количество итераций, он не смог пройти весь текст. Хотя T5 может генерировать текст, как GPT-2, мы будем использовать его для более интересных бизнес-применений.
Подведение итогов
Начнем с простой задачи: реферирование текста. Для тех компаний-разработчиков ИИ, которые хотят создать приложение, резюмирующее новостную статью, T5 идеально подходит для этой задачи. Например, отдав эту статью T5, вот три разных резюме, которые она подготовила:
| V1 | В следующем сезоне Destiny 2, начиная с 10 марта, будут переработаны мечи. у них будет перезаряжающаяся энергия, используемая как для тяжелых атак, так и для защиты. день святого валентина, малиновые дни, также происходит в этом месяце. |
| V2 | Bungie сообщила, что в следующем сезоне Destiny 2 мечи будут кардинально переработаны. студия по большей части была сдержанна в отношении того, что повлечет за собой сезон. переосмысление позволит мечу частично обходить щиты врагов. |
| V3 | В следующем сезоне Destiny 2 мечи будут переработаны, чтобы они могли обходить щиты врагов. сезон начинается 10 марта. Вы можете играть в Destiny 2 во время малиновых дней, события дня святого Валентина. |
Как мы видим, он проделал довольно изящную работу по подведению итогов статьи. Кроме того, каждое резюме отличается от других.
Обобщение с использованием предварительно обученных моделей имеет огромное потенциальное применение. Одним из интересных вариантов использования может быть автоматическое создание резюме каждой статьи и размещение его в начале для читателей, которым просто нужен краткий обзор. Можно пойти дальше, персонализировав сводку для каждого пользователя . Например, если у некоторых пользователей меньший словарный запас, им может быть предоставлена сводка с менее сложным выбором слов. Это очень простой пример, но он демонстрирует силу этой модели.
Другим интересным вариантом использования может быть использование таких сводок в поисковой оптимизации веб-сайта. Хотя T5 можно обучить автоматически генерировать очень качественные SEO, использование сводки может помочь сразу же, без переобучения модели.
Понимание прочитанного
T5 также можно использовать для понимания прочитанного, например, для ответов на вопросы из заданного контекста. Это приложение имеет очень интересные варианты использования, которые мы увидим позже. Но начнем с нескольких примеров:
| Вопрос | Кто изобрел теорию эволюции? |
| Контекст (Британская энциклопедия) | Открытие ископаемых костей крупных вымерших млекопитающих в Аргентине и наблюдение за многочисленными видами вьюрков на Галапагосских островах были одними из событий, которым приписывают стимулирование интереса Дарвина к происхождению видов. В 1859 году он опубликовал трактат «О происхождении видов путем естественного отбора», излагающий теорию эволюции и, что наиболее важно, роль естественного отбора в определении ее течения. |
| Отвечать | Дарвин |
Нет явного упоминания о том, что Дарвин изобрел теорию, но модель использовала имеющиеся знания вместе с некоторым контекстом, чтобы прийти к правильному выводу.
Как насчет очень маленького контекста?
| Вопрос | Куда мы пошли? |
| Контекст | В мой день рождения мы решили посетить северные районы Пакистана. Это было действительно весело. |
| Отвечать | северные районы пакистана |
Хорошо, это было довольно легко. Как насчет философского вопроса?
| Вопрос | В чем смысл жизни? |
| Контекст (Википедия) | Смысл жизни в том виде, в каком мы его воспринимаем, вытекает из философских и религиозных размышлений и научных исследований о существовании, социальных связях, сознании и счастье. Также затрагиваются многие другие вопросы, такие как символическое значение, онтология, ценность, цель, этика, добро и зло, свобода воли, существование одного или нескольких богов, представления о Боге, душе и загробной жизни. Научные вклады сосредоточены в первую очередь на описании связанных эмпирических фактов о Вселенной, изучении контекста и параметров, касающихся «как» жизни. |
| Отвечать | философское и религиозное созерцание и научные исследования существования, социальных связей, сознания и счастья |
Хотя мы знаем, что ответ на этот вопрос очень сложен, T5 попытался дать очень близкий, но разумный ответ. Слава!
Давайте пойдем дальше. Давайте зададим несколько вопросов, используя в качестве контекста ранее упомянутую статью Engadget.
| Вопрос | О чем это? |
| Отвечать | Destiny 2 сильно переработают |
| Вопрос | Когда мы можем ожидать это обновление? |
| Отвечать | 10 марта |
Как видите, контекстуальные ответы на вопросы T5 очень хороши. Одним из вариантов использования в бизнесе может быть создание контекстного чат-бота для веб-сайтов, который отвечает на запросы, относящиеся к текущей странице.
Другим вариантом использования может быть поиск некоторой информации в документах, например, задавать вопросы вроде «Является ли нарушением контракта использование ноутбука компании для личного проекта?» использование юридического документа в качестве контекста. Хотя у T5 есть свои ограничения, он вполне подходит для такого рода задач.
Читатели могут задаться вопросом: почему бы не использовать специализированные модели для каждой задачи? Это хороший момент: точность будет намного выше, а стоимость развертывания специализированных моделей будет намного ниже, чем предварительно обученная модель НЛП T5. Но прелесть Т5 как раз в том, что это «одна модель для управления всеми», т. е. вы можете использовать одну предварительно обученную модель практически для любой задачи НЛП. Плюс мы хотим использовать эти модели «из коробки», без переобучения и доводки. Таким образом, для разработчиков, создающих приложение, которое обобщает различные статьи, а также приложение, отвечающее на контекстные вопросы, одна и та же модель T5 может выполнять и то, и другое.
Предварительно обученные модели: модели глубокого обучения, которые скоро станут повсеместными
В этой статье мы рассмотрели предварительно обученные модели и то, как их использовать «из коробки» для различных вариантов использования в бизнесе. Подобно тому, как классический алгоритм сортировки используется почти везде для сортировки задач, эти предварительно обученные модели будут использоваться в качестве стандартных алгоритмов. Совершенно ясно, что то, что мы исследовали, было лишь прикосновением к поверхности приложений НЛП, и эти модели могут сделать гораздо больше.
Предварительно обученные модели глубокого обучения, такие как StyleGAN-2 и DeepLabv3, аналогичным образом могут использоваться в приложениях компьютерного зрения. Надеюсь, вам понравилась эта статья, и я с нетерпением жду ваших комментариев ниже.