
Un'introduzione alla rete neurale feedforward: livelli, funzioni e importanza
Pubblicato: 2020-05-28La tecnologia di deep learning è la spina dorsale dei motori di ricerca, della traduzione automatica e delle applicazioni mobili. Funziona imitando il cervello umano per trovare e creare modelli da diversi tipi di dati.
Una parte importante di questa incredibile tecnologia è una rete neurale feedforward, che assiste gli ingegneri del software nel riconoscimento e nella classificazione dei modelli, nella regressione non lineare e nell'approssimazione delle funzioni.
Diamo un'occhiata a questo aspetto essenziale dell'architettura della rete neurale di base.
Sommario
Che cos'è la rete neurale feedforward?
Comunemente note come rete multistrato di neuroni, le reti neurali feedforward sono chiamate così perché tutte le informazioni viaggiano solo nella direzione in avanti.
Le informazioni prima entrano nei nodi di input, si spostano attraverso i livelli nascosti e infine escono attraverso i nodi di output. La rete non contiene connessioni per reinserire nella rete le informazioni che escono dal nodo di output.
Le reti neurali feedforward hanno lo scopo di approssimare le funzioni.

Ecco come funziona .
Esiste un classificatore y = f*(x).
Questo alimenta l'input x nella categoria y.
La rete feedforward mapperà y = f (x; θ). Memorizza quindi il valore di θ che meglio approssima la funzione.
Rete neurale feedforward per la base per il riconoscimento degli oggetti nelle immagini, come puoi individuare nell'app Google Foto.
Gli strati di una rete neurale feedforward
Una rete neurale feedforward è costituita da quanto segue.
Livello di input
Contiene i neuroni che ricevono l'input. Quindi passano l'input al livello successivo. Il numero totale di neuroni nel livello di input è uguale agli attributi nel set di dati.
Strato nascosto
Questo è il livello intermedio, nascosto tra i livelli di input e output. C'è un numero enorme di neuroni in questo strato che applicano trasformazioni agli input. Quindi lo passano al livello di output.
Livello di output
È l'ultimo livello e dipende dalla costruzione del modello. Inoltre, il livello di output è la funzione prevista poiché sai quale sia il risultato che desideri.
Pesi dei neuroni
La forza di una connessione tra i neuroni è chiamata pesi. Il valore di un peso varia da 0 a 1.
Per saperne di più: Modello di rete neurale: breve introduzione, glossario
Funzione di costo nella rete neurale feedforward
La scelta della funzione di costo è una delle parti più importanti di una rete neurale feedforward. Di solito, piccole variazioni di peso e distorsioni non influiscono sui punti dati classificati. Quindi, per trovare un modo per migliorare le prestazioni utilizzando una funzione di costo uniforme per apportare piccole modifiche a pesi e distorsioni.
La formula per la funzione del costo medio dell'errore quadrato è:
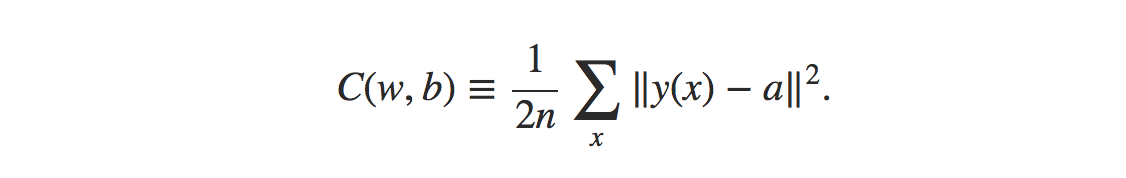
Fonte
Dove,
w = raccolta dei pesi nella rete
b = pregiudizi
n = numero di input di addestramento
a = vettori di uscita
x = ingresso
‖v‖ = lunghezza usuale del vettore v
Funzione di perdita nella rete neurale feedforward
La funzione di perdita nella rete neurale ha lo scopo di determinare se c'è qualche correzione necessaria al processo di apprendimento.
I neuroni dello strato di output saranno uguali al numero di classi. Per confrontare la differenza tra distribuzione di probabilità prevista e vera.
La perdita di entropia incrociata per la classificazione binaria è:
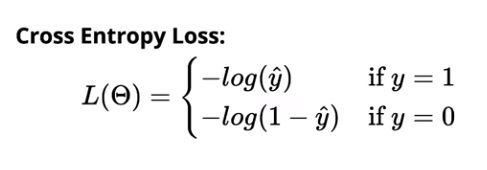
La perdita di entropia incrociata per la classificazione multiclasse è:
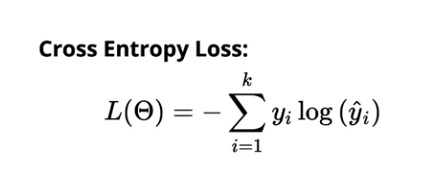

Fonte
Algoritmo di apprendimento graduale
Questo algoritmo aiuta a determinare tutti i migliori valori possibili per i parametri per ridurre la perdita nella rete neurale feedforward.

Immagine
Tutti i pesi (w₁₁₁, w₁₁₂,…) e le distorsioni b (b₁, b₂,….) vengono inizializzati casualmente. Una volta fatto ciò, le osservazioni nei dati vengono ripetute. Quindi, la distribuzione prevista corrispondente viene determinata rispetto a ciascuna osservazione. Infine, la perdita viene calcolata utilizzando la funzione di entropia incrociata.
Il valore della perdita aiuta quindi a calcolare le modifiche da apportare ai pesi per ridurre la perdita complessiva del modello.
Leggi: 13 Idee e argomenti interessanti per progetti di reti neurali
La necessità di un modello neuronale
Diciamo che gli input immessi nella rete sono dati di pixel grezzi che provengono da un'immagine scansionata di un personaggio. Affinché l'output nella rete classifichi correttamente la cifra, è necessario determinare la giusta quantità di pesi e distorsioni.
Ora, dovresti apportare piccole modifiche al peso nella rete per vedere come funzionerebbe l'apprendimento. Affinché ciò avvenga perfettamente, piccoli cambiamenti nei pesi dovrebbero portare solo a piccoli cambiamenti nell'output.
Tuttavia, cosa succede se il piccolo cambiamento nel peso equivale a un grande cambiamento nell'output? Il modello del neurone sigmoideo può risolvere un problema del genere.
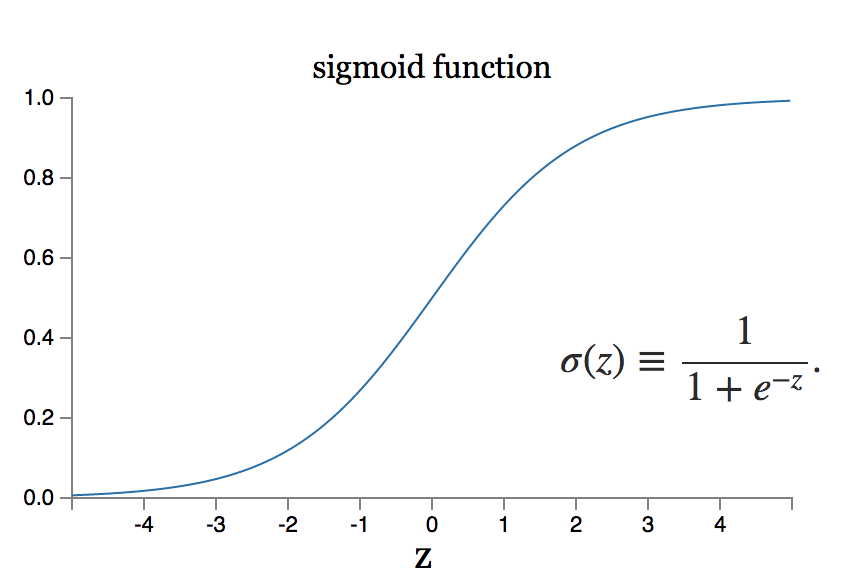
Fonte
Leggi anche: I 7 tipi di reti neurali artificiali di cui hanno bisogno gli ingegneri ML
Conclusione
Il deep learning è un territorio dell'ingegneria del software con una portata colossale di ricerca. Esistono molte architetture di rete neurale attualizzate per vari tipi di dati. I sistemi neurali convoluzionali, ad esempio, hanno ottenuto la migliore esecuzione nel campo delle procedure di gestione delle immagini, mentre i sistemi neurali ricorrenti sono generalmente utilizzati nell'elaborazione dei contenuti e della voce.
Quando vengono applicati a enormi set di dati, i sistemi neurali necessitano di misure mostruose della forza computazionale e dell'accelerazione delle apparecchiature, che possono essere ottenute attraverso la progettazione di unità di elaborazione grafica o GPU. Se sei nuovo nell'utilizzo delle GPU, puoi scoprire le impostazioni configurate gratuitamente sul web. I più preferiti sono i taccuini Kaggle o i taccuini di Google Collab.
Per realizzare una rete neurale feedforward efficace, si eseguono diverse iterazioni nell'architettura di rete, che richiedono una grande quantità di test.
Per ulteriori informazioni su come funzionano queste reti, impara dagli esperti di upGrad. I nostri corsi sono incredibilmente completi e puoi risolvere le tue domande contattando direttamente i nostri insegnanti esperti e migliori della classe.
Se sei interessato a saperne di più sull'apprendimento automatico, dai un'occhiata al Diploma PG di IIIT-B e upGrad in Machine Learning e AI, progettato per i professionisti che lavorano e offre oltre 450 ore di formazione rigorosa, oltre 30 casi di studio e incarichi, IIIT- B Status di Alumni, oltre 5 progetti pratici pratici e assistenza sul lavoro con le migliori aziende.
L'algebra lineare è richiesta nelle reti neurali?
Una rete neurale è un modello matematico che risolve qualsiasi problema complesso. La rete prende una serie di input e calcola una serie di output con l'obiettivo di ottenere il risultato desiderato. Quando si studia la teoria delle reti neurali, la maggior parte dei neuroni e degli strati sono spesso formattati in algebra lineare. L'algebra lineare è necessaria per costruire il modello matematico. Puoi anche usare l'algebra lineare per comprendere la rete del modello. Quindi, per rispondere alla domanda, sì, la conoscenza di base dell'algebra lineare è obbligatoria durante l'utilizzo delle reti neurali.
Cosa si intende per backpropagation nelle reti neurali?
Nel caso di reti neurali che utilizzano la discesa del gradiente, viene utilizzata la backpropagation. Questo algoritmo stima il gradiente della funzione di errore rispetto ai pesi della rete neurale ed è essenzialmente una propagazione all'indietro di errori. Questo approccio viene utilizzato perché la messa a punto dei pesi riduce i tassi di errore e quindi migliora la generalizzazione del modello di rete neurale, rendendolo più affidabile. La backpropagation è comunemente classificata come una forma di apprendimento automatico supervisionato poiché richiede un risultato noto e previsto per ciascun valore di input al fine di calcolare il gradiente della funzione di perdita nelle reti neurali.
In che modo la backpropagation è diversa dagli ottimizzatori?
Nelle reti neurali vengono utilizzati sia gli ottimizzatori che l'algoritmo di backpropagation e lavorano insieme per rendere il modello più affidabile. La backpropagation viene utilizzata per calcolare in modo efficiente i gradienti e gli ottimizzatori vengono utilizzati per addestrare la rete neurale utilizzando i gradienti ottenuti utilizzando la backpropagation. In poche parole, ciò che fa per noi la backpropagation è calcolare i gradienti, che vengono successivamente utilizzati dagli ottimizzatori.