
Eine Einführung in das neuronale Feedforward-Netzwerk: Schichten, Funktionen und Bedeutung
Veröffentlicht: 2020-05-28Deep-Learning-Technologie ist das Rückgrat von Suchmaschinen, maschineller Übersetzung und mobilen Anwendungen. Es funktioniert, indem es das menschliche Gehirn nachahmt, um Muster aus verschiedenen Arten von Daten zu finden und zu erstellen.
Ein wichtiger Bestandteil dieser unglaublichen Technologie ist ein neuronales Feedforward-Netzwerk, das Softwareentwickler bei der Mustererkennung und -klassifizierung, nichtlinearen Regression und Funktionsannäherung unterstützt.
Lassen Sie uns einige Einblicke in diesen wesentlichen Aspekt der Kernarchitektur des neuronalen Netzwerks erhalten.
Inhaltsverzeichnis
Was ist Feedforward Neural Network?
Feedforward-neuronale Netze, die allgemein als mehrschichtiges Netzwerk von Neuronen bekannt sind, werden so genannt, weil alle Informationen nur in Vorwärtsrichtung übertragen werden.
Die Informationen treten zuerst in die Eingabeknoten ein, bewegen sich durch die verborgenen Schichten und kommen schließlich durch die Ausgabeknoten heraus. Das Netzwerk enthält keine Verbindungen, um die am Ausgangsknoten herauskommenden Informationen wieder in das Netzwerk einzuspeisen.
Neuronale Feedforward-Netze sollen Funktionen approximieren.

So funktioniert es .
Es gibt einen Klassifikator y = f*(x).
Dies füttert die Eingabe x in die Kategorie y.
Das Feedforward-Netzwerk bildet y = f (x; θ) ab. Dann merkt es sich den Wert von θ, der die Funktion am besten annähert.
Feedforward neuronales Netzwerk als Basis für die Objekterkennung in Bildern, wie man es in der Google Fotos App erkennen kann.
Die Schichten eines neuronalen Feedforward-Netzwerks
Ein neuronales Feedforward-Netzwerk besteht aus Folgendem.
Eingabeschicht
Es enthält die Input-empfangenden Neuronen. Sie geben dann die Eingabe an die nächste Schicht weiter. Die Gesamtzahl der Neuronen in der Eingabeschicht entspricht den Attributen im Datensatz.
Versteckte Schicht
Dies ist die mittlere Schicht, die zwischen der Eingabe- und der Ausgabeschicht verborgen ist. In dieser Schicht gibt es eine große Anzahl von Neuronen, die Transformationen auf die Eingaben anwenden. Sie geben es dann an die Ausgabeschicht weiter.
Ausgabeschicht
Es ist die letzte Schicht und hängt vom Aufbau des Modells ab. Außerdem ist die Ausgabeschicht das vorhergesagte Feature, da Sie wissen, wie das Ergebnis aussehen soll.
Neuronengewichte
Die Stärke einer Verbindung zwischen den Neuronen wird Gewicht genannt. Der Wert einer Gewichtung reicht von 0 bis 1.
Mehr wissen: Neuronales Netzwerkmodell: Kurze Einführung, Glossar
Kostenfunktion im Feedforward Neural Network
Die Auswahl der Kostenfunktion ist einer der wichtigsten Teile eines neuronalen Feedforward-Netzwerks. Normalerweise wirken sich kleine Änderungen der Gewichtungen und Verzerrungen nicht auf die klassifizierten Datenpunkte aus. Also, um einen Weg zu finden, die Leistung zu verbessern, indem eine glatte Kostenfunktion verwendet wird, um kleine Änderungen an Gewichtungen und Bias vorzunehmen.
Die Formel für die Kostenfunktion des mittleren quadratischen Fehlers lautet:
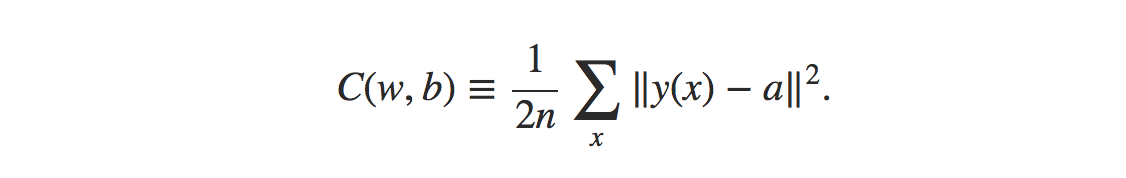
Quelle
Woher,
w = Sammlung von Gewichten im Netzwerk
b = Vorurteile
n = Anzahl der Trainingseingaben
a = Ausgangsvektoren
x = Eingang
‖v‖ = übliche Länge des Vektors v
Verlustfunktion im Feedforward Neural Network
Die Verlustfunktion im neuronalen Netz dient der Bestimmung, ob der Lernprozess korrigiert werden muss.
Die Neuronen der Ausgabeschicht sind gleich der Anzahl der Klassen. Um die Differenz zwischen vorhergesagter und wahrer Wahrscheinlichkeitsverteilung zu vergleichen.
Der Kreuzentropieverlust für die binäre Klassifizierung beträgt:
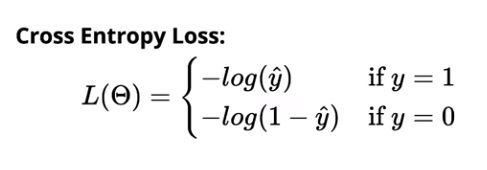
Der Kreuzentropieverlust für die Mehrklassenklassifizierung beträgt:

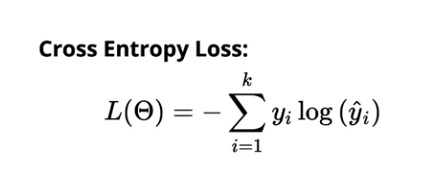
Quelle
Gradienten-Lernalgorithmus
Dieser Algorithmus hilft dabei, alle bestmöglichen Werte für Parameter zu bestimmen, um den Verlust in dem neuronalen Feedforward-Netzwerk zu verringern.

Bild
Alle Gewichte (w₁₁₁, w₁₁₂, …) und Bias b (b₁, b₂, ….) werden zufällig initialisiert. Sobald dies geschehen ist, werden die Beobachtungen in den Daten iteriert. Dann wird die entsprechende vorhergesagte Verteilung für jede Beobachtung bestimmt. Schließlich wird der Verlust unter Verwendung der Kreuzentropiefunktion berechnet.
Der Verlustwert hilft dann dabei, die an den Gewichtungen vorzunehmenden Änderungen zu ermitteln, um den Gesamtverlust des Modells zu verringern.
Lesen Sie: 13 interessante Projektideen und -themen für neuronale Netze
Die Notwendigkeit eines Neuronenmodells
Nehmen wir an, die Eingaben, die in das Netzwerk eingespeist werden, sind rohe Pixeldaten, die von einem gescannten Bild einer Figur stammen. Damit die Ausgabe im Netzwerk die Ziffer korrekt klassifiziert, sollten Sie die richtige Menge an Gewichtungen und Verzerrungen bestimmen.
Jetzt müssten Sie kleine Änderungen an der Gewichtung im Netzwerk vornehmen, um zu sehen, wie das Lernen funktionieren würde. Damit dies perfekt gelingt, sollten kleine Änderungen in den Gewichten nur zu kleinen Änderungen in der Ausgabe führen.
Was aber, wenn die kleine Änderung des Gewichts zu einer großen Änderung der Leistung führt? Das Sigmoidneuronenmodell kann ein solches Problem lösen.
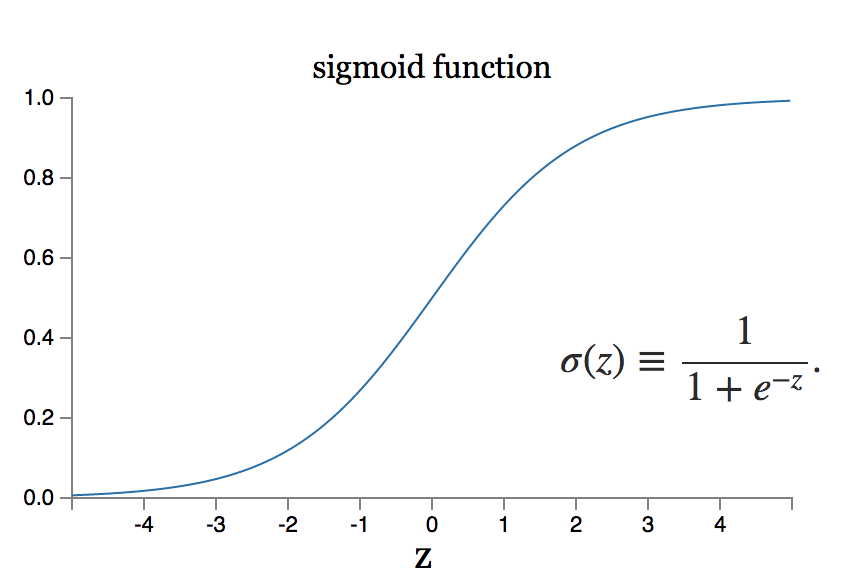
Quelle
Lesen Sie auch: Die 7 Arten von künstlichen neuronalen Netzen, die ML-Ingenieure benötigen
Fazit
Deep Learning ist ein Gebiet des Software Engineering mit einem kolossalen Umfang an Forschung. Es gibt viele neuronale Netzwerkarchitekturen, die für verschiedene Datentypen aktualisiert wurden. Faltungsneuronale Systeme haben zum Beispiel Best-in-Class-Ausführung auf den Gebieten der Bildbearbeitungsprozeduren erreicht, während rekurrente neurale Systeme im Allgemeinen in der Inhalts- und Sprachverarbeitung verwendet werden.
An dem Punkt, an dem sie auf riesige Datensätze angewendet werden, benötigen neuronale Systeme monströse Maße an Rechenleistung und Gerätebeschleunigung, was durch das Design von Grafikverarbeitungseinheiten oder GPUs erreicht werden kann. Wenn Sie neu in der Verwendung von GPUs sind, können Sie kostenlos konfigurierte Einstellungen im Internet finden. Die am meisten bevorzugten sind Kaggle Notebooks oder Google Collab Notebooks.
Um ein effektives neuronales Feedforward-Netzwerk zu erreichen, führen Sie mehrere Iterationen in der Netzwerkarchitektur durch, was viele Tests erfordert.
Weitere Informationen zur Funktionsweise dieser Netzwerke erhalten Sie von den Experten von upGrad. Unsere Kurse sind unglaublich umfassend und Sie können Ihre Fragen lösen, indem Sie sich direkt mit unseren erfahrenen und erstklassigen Lehrern in Verbindung setzen.
Wenn Sie mehr über maschinelles Lernen erfahren möchten, sehen Sie sich das PG-Diplom in maschinellem Lernen und KI von IIIT-B & upGrad an, das für Berufstätige konzipiert ist und mehr als 450 Stunden strenge Schulungen, mehr als 30 Fallstudien und Aufgaben bietet, IIIT- B-Alumni-Status, mehr als 5 praktische, praktische Abschlussprojekte und Jobunterstützung bei Top-Unternehmen.
Ist lineare Algebra in neuronalen Netzen erforderlich?
Ein neuronales Netzwerk ist ein mathematisches Modell, das jedes komplexe Problem löst. Das Netzwerk nimmt eine Reihe von Eingaben und berechnet eine Reihe von Ausgaben mit dem Ziel, das gewünschte Ergebnis zu erzielen. Beim Studium der Theorie neuronaler Netze werden die meisten Neuronen und Schichten häufig in linearer Algebra formatiert. Lineare Algebra ist notwendig, um das mathematische Modell zu konstruieren. Sie können auch lineare Algebra verwenden, um die Vernetzung des Modells zu verstehen. Um also die Frage zu beantworten, ja, die Grundkenntnisse der linearen Algebra sind bei der Verwendung neuronaler Netze zwingend erforderlich.
Was versteht man unter Backpropagation in neuronalen Netzen?
Im Fall von neuronalen Netzen, die einen Gradientenabstieg verwenden, wird Backpropagation verwendet. Dieser Algorithmus schätzt den Gradienten der Fehlerfunktion in Bezug auf die Gewichtungen des neuronalen Netzes und ist im Wesentlichen eine Rückwärtsausbreitung von Fehlern. Dieser Ansatz wird verwendet, weil die Feinabstimmung der Gewichte die Fehlerraten reduziert und somit die Verallgemeinerung des neuronalen Netzwerkmodells verbessert und es zuverlässiger macht. Backpropagation wird allgemein als eine Form des überwachten maschinellen Lernens kategorisiert, da es ein bekanntes, beabsichtigtes Ergebnis für jeden Eingabewert erfordert, um den Gradienten der Verlustfunktion in neuronalen Netzwerken zu berechnen.
Wie unterscheidet sich Backpropagation von Optimierern?
In neuronalen Netzen werden sowohl Optimierer als auch der Backpropagation-Algorithmus verwendet, und sie arbeiten zusammen, um das Modell zuverlässiger zu machen. Backpropagation wird verwendet, um Gradienten effizient zu berechnen, und Optimierer werden verwendet, um das neuronale Netzwerk unter Verwendung der durch Backpropagation erhaltenen Gradienten zu trainieren. Kurz gesagt, Backpropagation berechnet für uns Gradienten, die anschließend von Optimierern verwendet werden.