
机器学习中的等渗回归:理解机器学习中的回归
已发表: 2020-12-21有多种类型的回归模型(算法)可用于训练机器学习程序,例如线性回归、逻辑回归、岭回归和套索回归。 其中,线性回归模型是最基本、应用最广泛的回归模型。 机器学习中的等渗回归基于线性回归。 因此,在我们继续等渗回归之前,让我们先看看机器学习中的线性回归。
目录
了解机器学习中的线性回归
资源
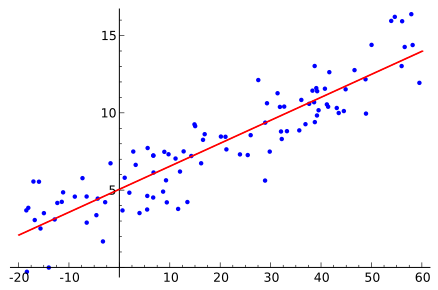
线性回归模型用于确定因变量和自变量之间的关系。 它假设两个变量之间存在线性关系,由最佳拟合线表示。 方程 y= mx + c + e 用于表示线性回归模型,其中:
m = 线的斜率
c=拦截
e= 模型中的错误

线性回归模型容易受到异常值的影响,高度不灵活,因此不能用于大数据。 当此模型部署在大型测试数据上时,有多个实例位于线的斜率之外,也称为残差。 诸如 L1 和 L2 正则化之类的方法可用于降低直线斜率的陡度,但它们并没有被证明是有用的。
必读:机器学习模型解释
这限制了机器学习算法的准确性。 正在采用一种新的机器学习等渗回归方法来克服这一限制。 虽然目前还没有普及,但这种方法非常强大,可以帮助提高机器学习程序的准确性。
了解机器学习中的等渗回归
在深入研究技术内容之前,让我们通俗地理解机器学习中的等渗回归。
让我们从解码“等渗”这个词开始。 “isotonic”一词源于希腊语词根,由“iso”和“tonic”两部分组成。 在这里,“iso”表示相等,“tonic”表示伸展。 因此,就机器学习算法而言,等渗回归可以理解为沿线性回归线的相等拉伸。 它适用于线性回归模型。
让我们看一下与等渗回归相关的不同方面,这将有助于我们更好地理解它。
1.分段线性模型
如前所述,线性回归线的斜率需要最小化,为此使用了L1和L2正则化方法。 等渗回归方法完全不同,它通过创建阈值并将每个部分端到端连接的线性线划分为分段部分。
例如,在上图中,X 轴可以进一步划分为多个较小的部分,例如以 10 为等间隔。这些间隔中的每一个都可以称为 bin,例如 bin1、bin2、bin3、bin4 等在。 因此,线性方程现在变为,
y= m1x1 + m2x2 + m3x3 +….. mnxn + c,其中:
m1、m2、m3….mn = 各个 bin 的直线斜率。
这有助于最小化误差并减小最佳拟合线的斜率。
2. 非负斜率
由于等渗函数是单调函数,所以解的斜率总是非负的。 从一个阈值移动到另一个阈值时,不允许降低斜率。 阈值中的最低点应始终大于前一个阈值中的最高点。

例如,设 x1、x2、x3、x4…xn 是考虑到 bin b1、b2、b3、b4…bn 中的斜率的数据点的值。 然后,根据规则,斜率应该是非负的。 因此,
f(x1) <= f(x2) <= f(x3) <= f(x4)…<= f(xn)。
因此,我们从较低的点(其中 f(x1) 是最低点)开始,然后随着每个阈值逐渐移动到较高的点。 阈值的斜率可以为零(水平线),但永远不能为负(向下斜率)。
阅读:面向初学者的机器学习项目创意
在机器学习模型中使用等渗回归的优势
使用等渗回归提供了两个主要好处,这将在下面讨论。
1. 多维缩放
如果您有多个输入变量,等渗回归非常有用。 我们可以将每个维度作为每个函数进行检查,并以线性方式对其进行插值。 这允许简单的多维缩放。
2. 概率值的校准
在逻辑回归中,假设我们有一个变量 x,我们表示一个概率 p(1),其中变量的概率值不增加。 但是,实际上,现实世界中的概率值更高。 在这种情况下,出于校准目的或增加此类变量的概率,等渗回归证明非常有用。
查看:机器学习面试问题
在机器学习模型中使用等渗回归的缺点
使用等渗回归有一个主要缺点,将在下面讨论。
过拟合的风险
随着等渗约束和预测器特征的数量增加,超参数 (K) 过度拟合的风险很大,但可以使用交叉验证工作流方法来管理该问题。
结论
目前,只有三种主要语言具有 Isotonic 回归的开源包。 然而,看看在机器学习问题中使用等渗回归的好处,等渗回归包的范围、使用和可用性在未来肯定会增加。
我们可以看到等渗回归主要取代线性回归和 L1 和 L2 归一化方法。 因此,要为未来做好准备,有必要从现在开始更新并了解等渗回归!
如果您有兴趣了解有关机器学习中的等渗回归或其他机器学习相关概念的更多信息,您可以查看 IIIT-B 和 upGrad 的机器学习和人工智能 PG 文凭,这是印度最畅销的课程,获得 4.5 星评级. 该课程有 450 多个小时的学习时间、30 多个案例研究和作业,并帮助学生学习与机器学习和 AI 相关的紧缺技能。
为什么回归在机器学习中很重要?
回归分析是一种监督学习算法,是机器学习中的基本概念之一。 回归用于通过尝试估计一个变量的值如何影响另一个变量的值来建立不同变量之间的关系。 在机器学习领域,回归包含复杂的数学算法,这些算法有助于根据一个或多个预测变量的连续变化值来估计特定目标变量的结果。 最流行的回归分析是线性回归,因为它很容易用于进行预测和预测。
机器学习和数据科学一样吗?
随着数据科学和机器学习等流行语成为当今主流,许多人经常对它们的实际含义感到困惑。 让我们试着在这里快速解释一下。 数据科学是指对组织产生的大量数据的研究。 数据科学家采用各种技术从这些数据中揭示有价值的见解,以便企业能够获得最大的利益并在竞争中保持领先地位。 机器学习不同于数据科学; 它采用数据科学技术来了解数据,然后用于训练机器。 机器学习使用复杂的数学模型来帮助计算机在没有人工干预的情况下学习。
机器学习和深度学习一样吗?
机器学习是人工智能的一个子集。 它采用的算法或模型可以分析数据,从中学习,然后应用这些学习来帮助计算机或机器在没有明确的人工输入的情况下做出决策。 另一方面,深度学习是机器学习的一个子领域。 它用于分层构建算法或数学模型,以开发类似于人脑结构的人工神经网络。 该神经网络可以自行学习,并使用自己的逻辑框架和分析数据做出智能决策。