
机器学习中的决策树解释[带示例]
已发表: 2020-12-21介绍
决策树学习是一种主流的数据挖掘技术,是监督机器学习的一种形式。 决策树就像一个图表,人们使用它来表示统计概率或找到发生的过程、行动或结果。 决策树示例可以更清楚地理解这个概念。
决策树图中的分支显示了可能的结果、可能的决策或反应。 决策树末端的分支显示预测或结果。 决策树通常用于为手动解决的复杂问题找到解决方案。 让我们借助一些决策树示例详细了解这一点。
决策树是一种流行且功能强大的工具,用于对数据或事件进行预测和分类。 它类似于流程图,但具有树结构。 树的内部节点代表一个属性的测试或问题; 每个分支都是所问问题的可能结果,终端节点也称为叶节点,表示一个类标签。
在决策树中,我们有几个预测变量。 根据这些预测变量,尝试预测所谓的响应变量。
相关阅读:决策树分类:您需要知道的一切
ML 中的决策树
通过以序列的形式表示几个步骤,决策树成为一种简单而有效的方式来理解和可视化可能的决策选项和范围内的潜在结果。 决策树还有助于识别可能的选项,并根据可以产生的每个行动方案权衡回报和风险。

决策树部署在许多小型和大型组织中,作为一种决策支持系统。 由于决策树示例是结构化模型,因此读者可以理解图表并分析特定选项如何以及为什么会导致相应的决策。 决策树示例还允许读者预测并获得单个问题的多种可能解决方案,了解格式以及不同事件和数据与决策之间的关系。
树中的每个结果都有一个奖励和风险编号或分配的权重。 如果您曾经使用过决策树,那么您将获得每一个最终结果,可能会有缺点和好处。 为了正确地结束您的树,您可以根据事件和数据量的需要将其跨度尽可能短或长。 让我们举一个简单的决策树示例来更好地理解它。
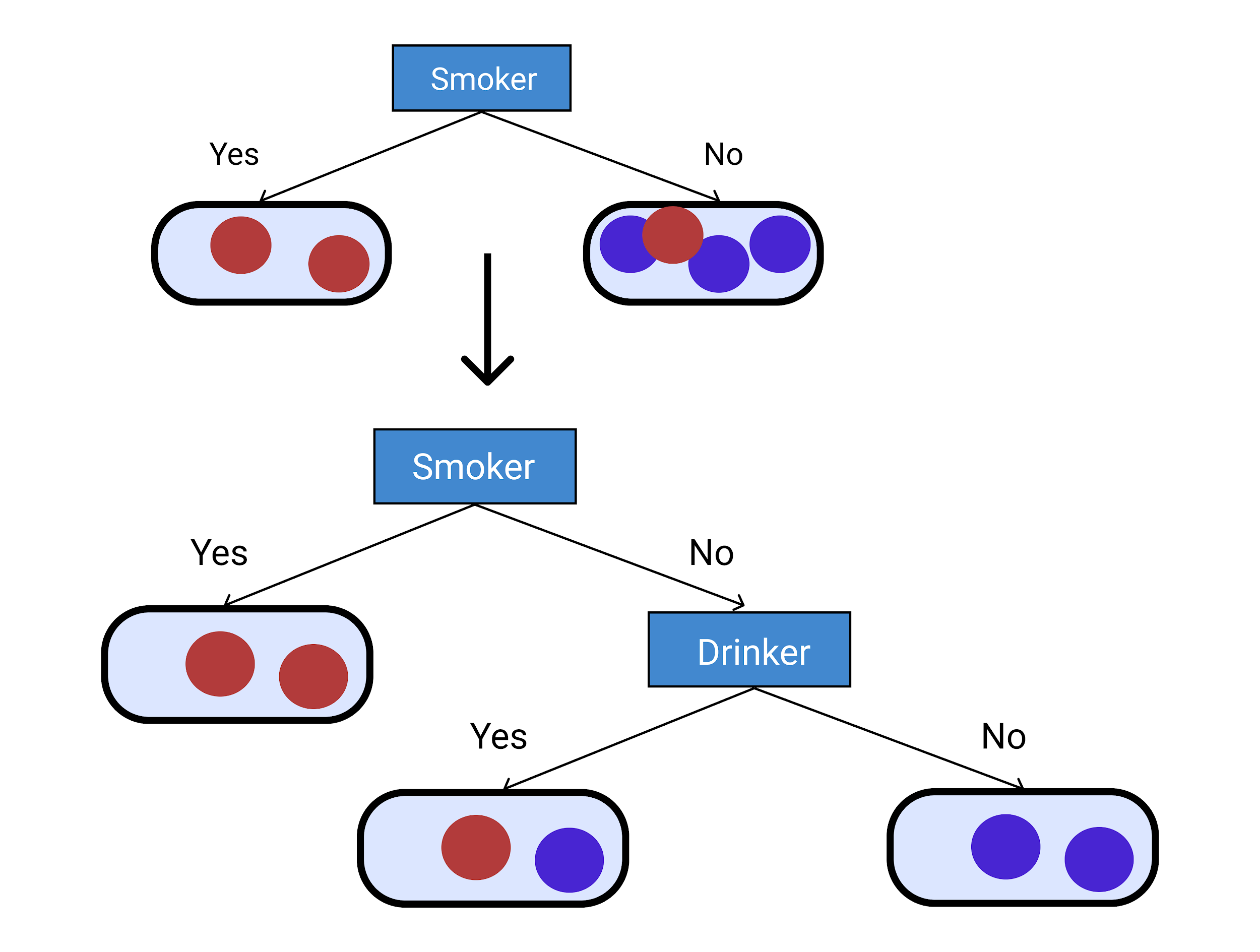
考虑给定的数据,其中包含以下人员的详细信息:他们是否饮酒、吸烟、体重以及这些人的死亡年龄。
| 姓名 | 饮酒者 | 吸烟者 | 重量 | 年龄(死亡) |
| 山姆 | 是的 | 是的 | 120 | 44 |
| 玛丽 | 不 | 不 | 70 | 96 |
| 乔纳斯 | 是的 | 不 | 72 | 88 |
| 泰勒 | 是的 | 是的 | 55 | 52 |
| 乔 | 不 | 是的 | 94 | 56 |
| 哈利 | 不 | 不 | 62 | 93 |
让我们尝试预测人们会在更年轻还是更年长时死亡。 饮酒者、吸烟者和体重等特征将作为预测值。 使用这些,我们将年龄视为响应变量。
让我们将70岁之前去世的人称为“年轻”,将70岁之后死亡的人称为“老”。 现在让我们根据预测变量预测响应变量。 下面给出的是学习数据后做出的决策树。
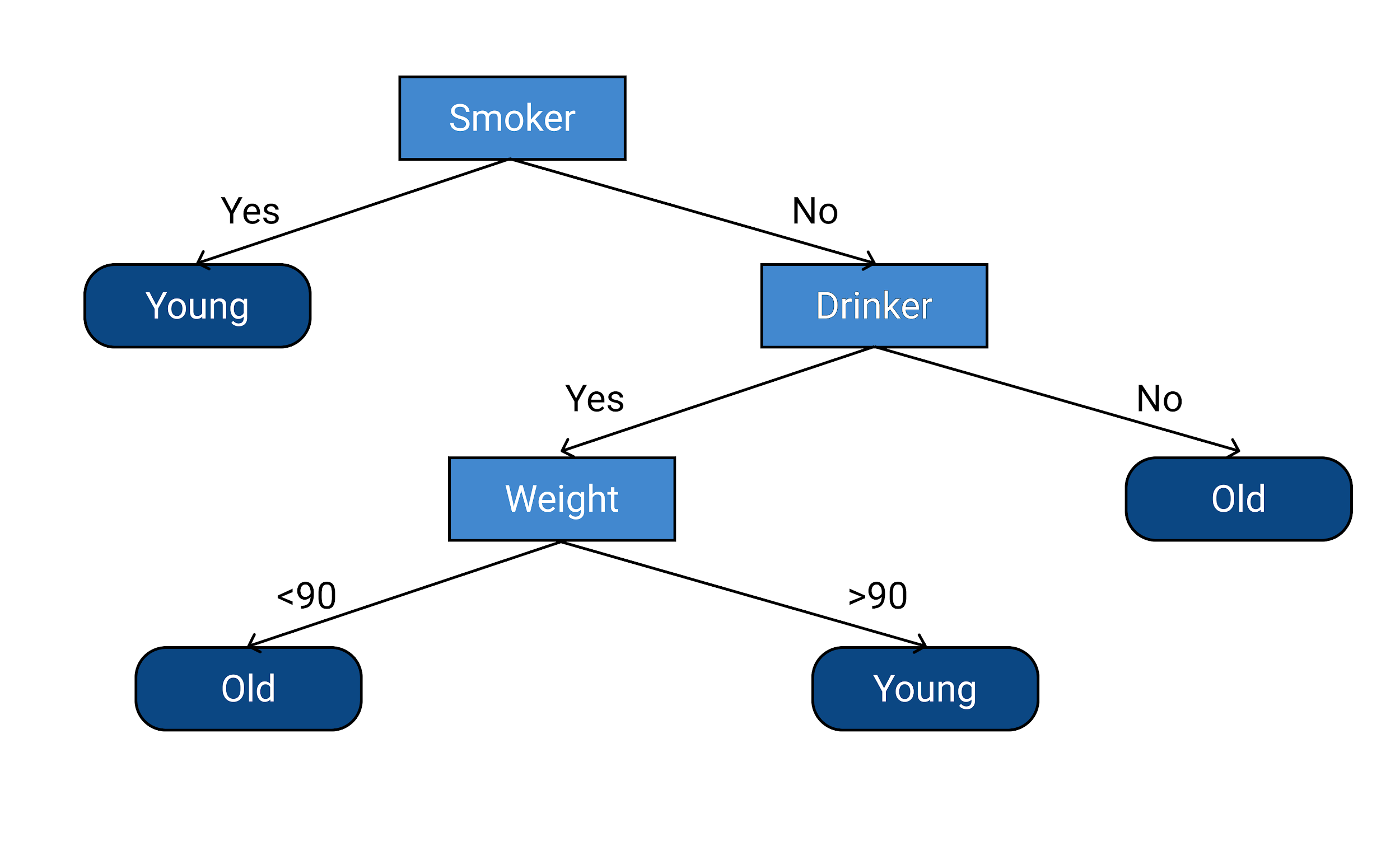
上面的决策树解释说,如果一个人是吸烟者,他们会英年早逝。 如果一个人不是吸烟者,那么考虑的下一个因素是这个人是否饮酒。 如果一个人不吸烟也不喝酒,这个人就会老死。
如果一个人不是吸烟者并且是饮酒者,则考虑该人的体重。 如果一个人不吸烟,饮酒,并且体重低于 90 公斤,那么这个人就会老死。 最后,如果一个人不吸烟,饮酒,体重超过 90 公斤,那么他们就会英年早逝。
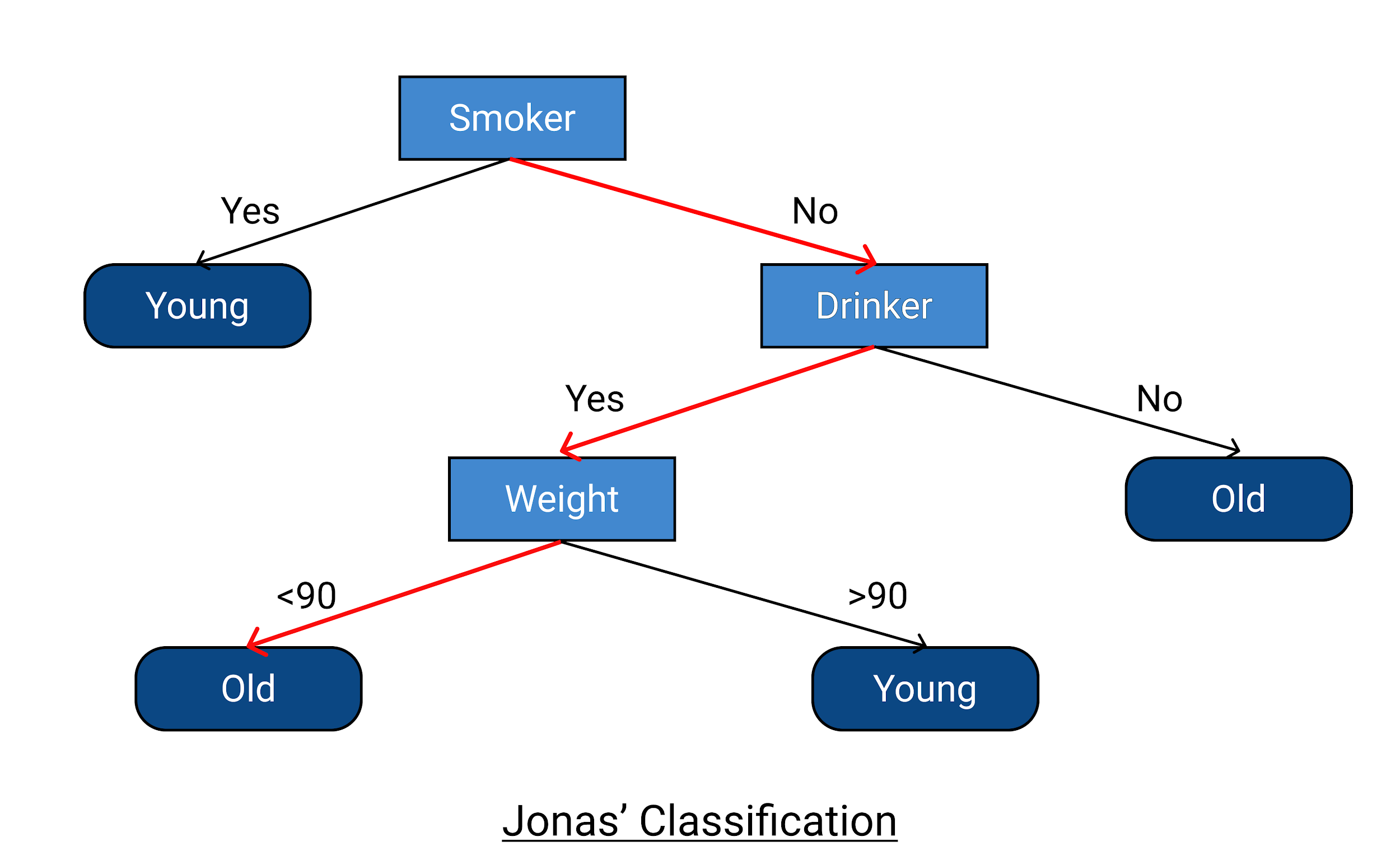
从给定的数据中,让我们以 Jonas 的例子来检查决策树是否分类正确以及它是否正确预测了响应变量。 乔纳斯不吸烟,酗酒,体重不到 90 公斤。 根据决策树,他会老死(他去世的年龄>70)。 此外,根据数据,他在 88 岁时去世,这意味着决策树示例已正确分类并且运行良好。
但是你有没有想过决策树工作背后的基本思想? 在决策树中,实例集以每个子集的变化变小的方式分成子集。 也就是说,我们想要减少熵,因此减少了变化,并且试图使事件或实例变得纯粹。
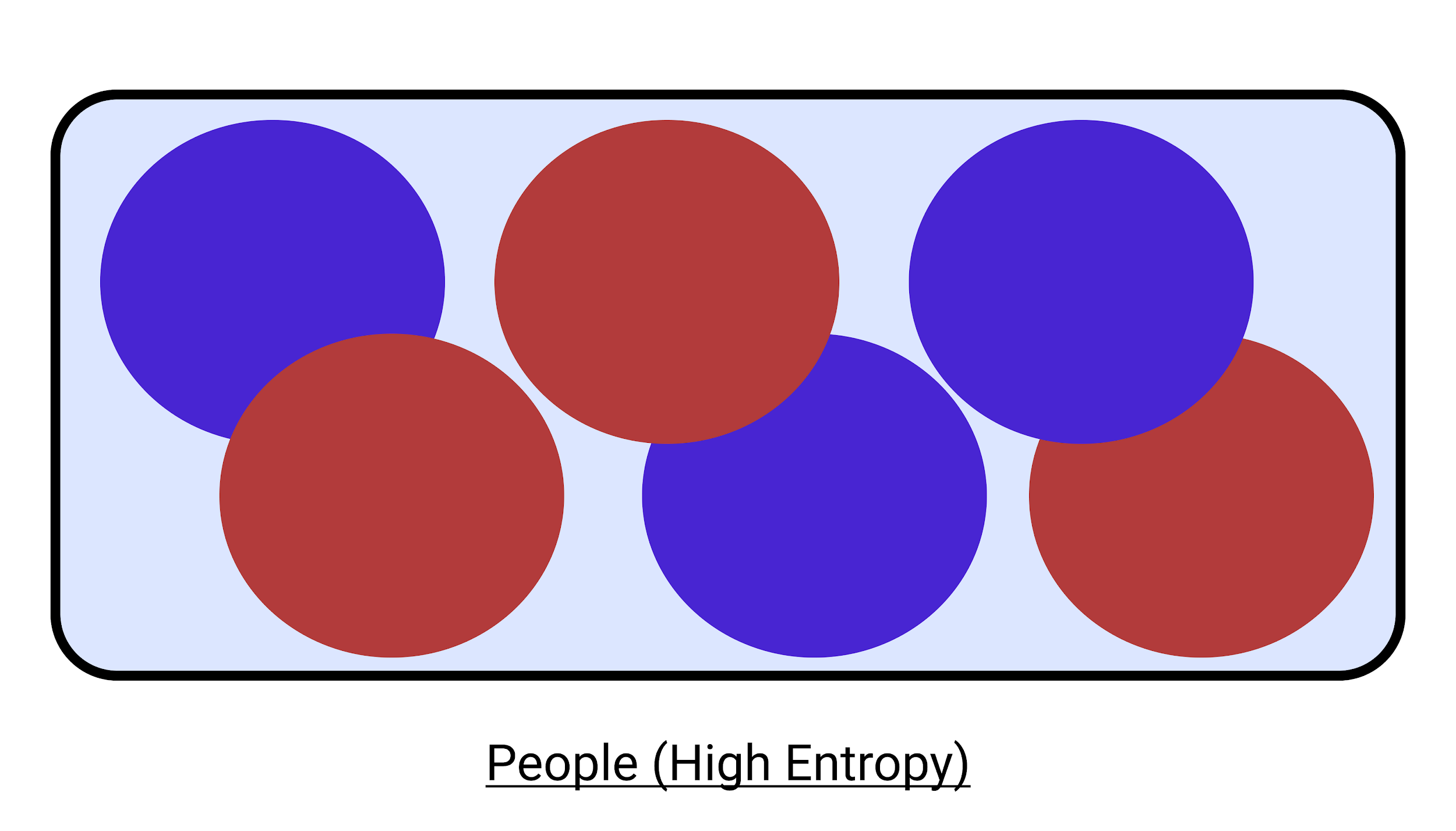
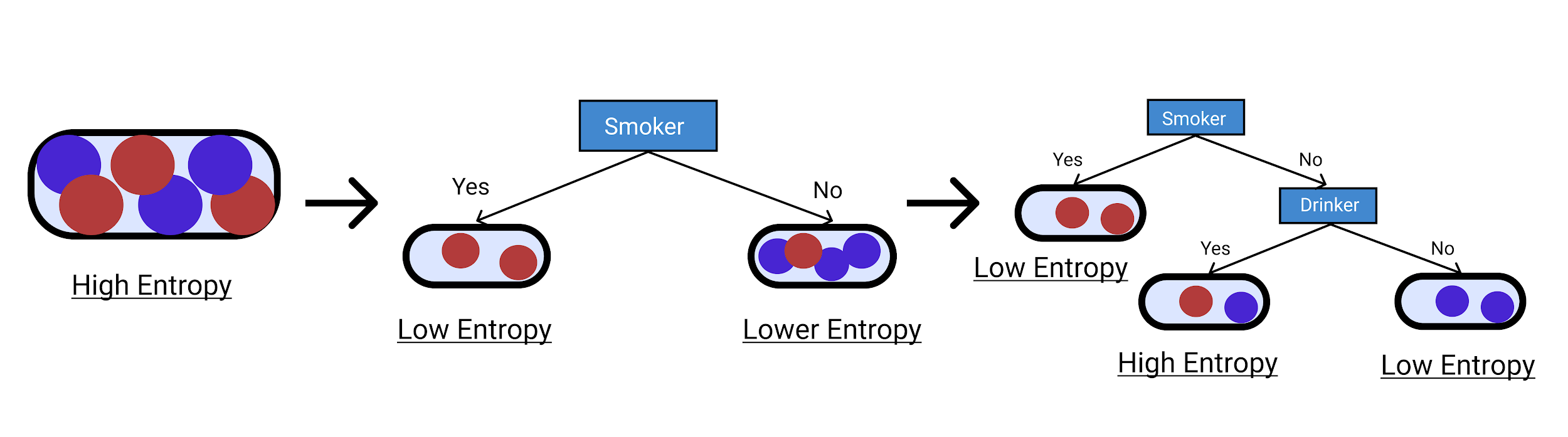
让我们考虑一个类似的决策树示例。 首先,我们考虑这个人是否吸烟。
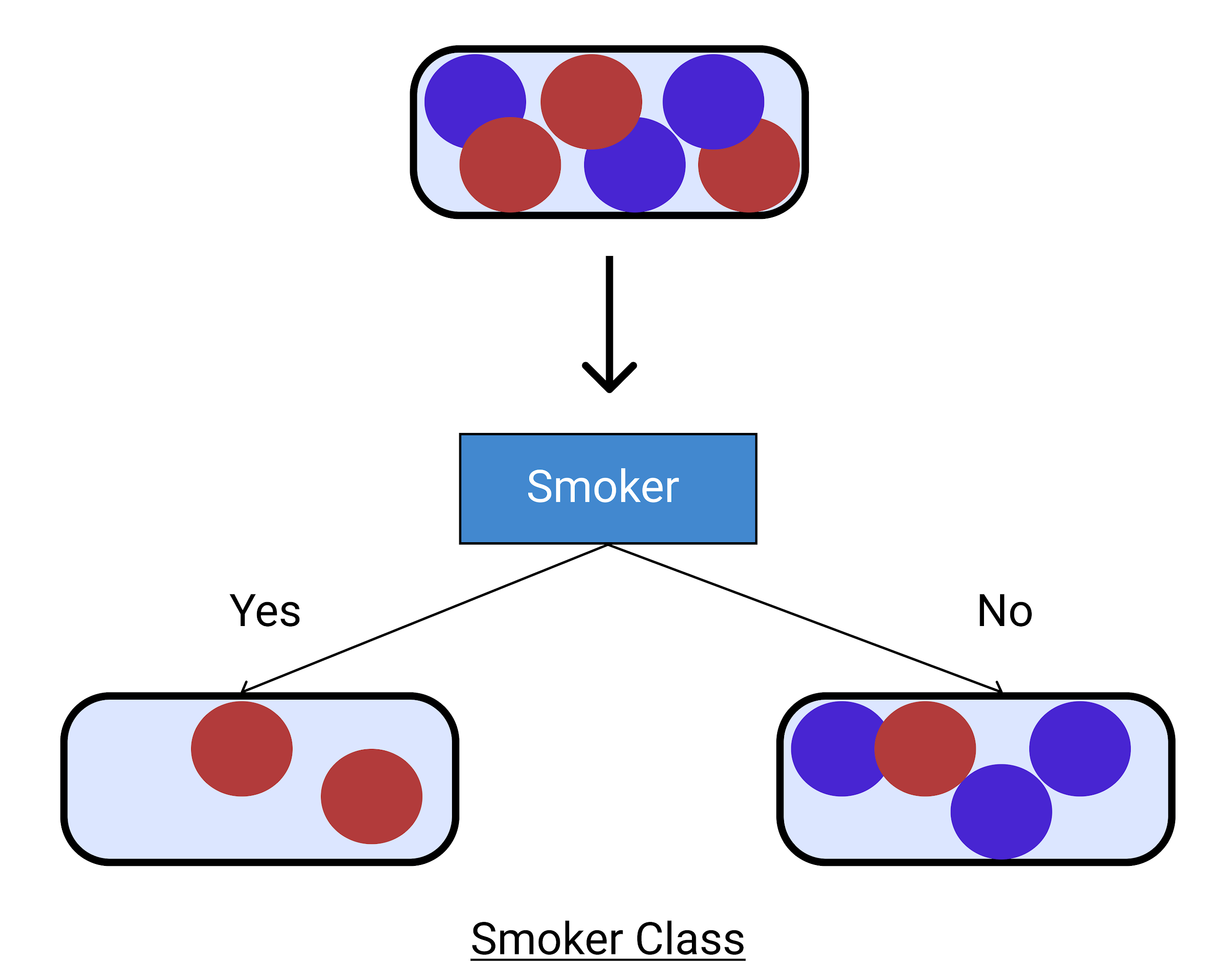

在这里,我们不确定非吸烟者。 因此,我们将其分为饮酒者和非饮酒者。
从下面给出的图表中我们可以看到,我们从具有大变化的高熵到将其减少到我们更确定的更小的类。 通过这种方式,您可以增量构建任何决策树示例。
让我们使用 ID3 算法构建决策树。 在决策树中更重要的是对熵的深刻理解。 熵只不过是不确定性的程度。 它由以下给出:
![]()
(有时也用“E”表示)
如果我们将它应用于上面的示例,它将如下所示:
考虑我们没有将人分成任何类别的情况。 当两种类型的人数量相同时,这是最坏的情况(高熵)。 这里的比例是 3:3。
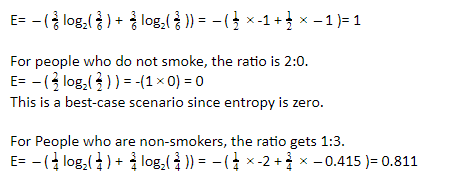
同样,对于不喝酒的人,比例为 1:1,熵为 1。因此,由于不确定性,需要进一步拆分。 对于不喝酒的人来说,这个比例是2:0。 因此,熵为 0。
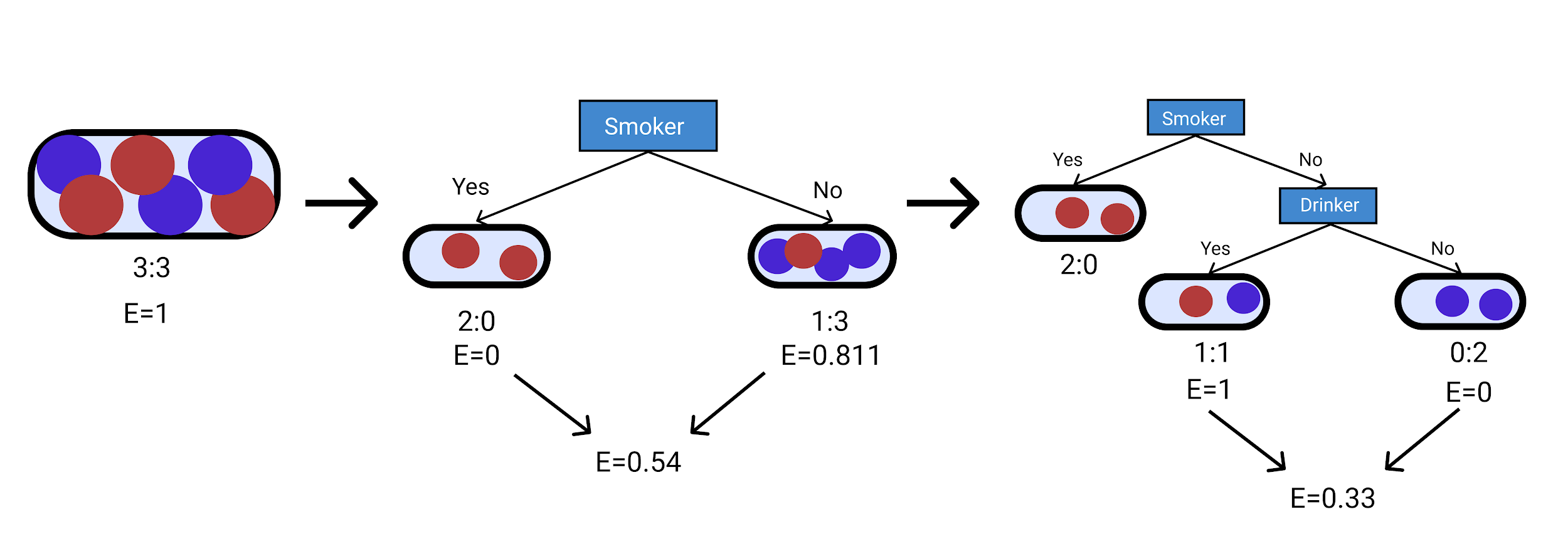
现在,我们已经计算了不同情况的熵,因此我们可以计算相同情况的加权平均值。
对于第一个分支, E= 6 6 1=1
对于吸烟者类别, E= 2 6 0+ 4 6 0.811=0.54
对于吸烟者和饮酒者类别, E= 2 6 0+ 2 6 1+ 2 6 0=0.33
下图将帮助您快速理解上述计算。
最后,信息增益:
| 班级 | 熵 | 信息增益(E2-E1) |
| 人们 | 1 | 0.46 |
| 吸烟者 | 0.54 | 0.21 |
| 吸烟者+饮酒者 | 0.33 | – |
另请阅读:决策树面试问答
结论
我们已经成功地从理论到实际决策树示例深入研究了决策树。 我们还使用 ID3 算法构建了决策树。 如果您觉得这很有趣,您可能会喜欢详细探索数据科学。
如果您有兴趣了解有关决策树、机器学习的更多信息,请查看 IIIT-B 和 upGrad 的机器学习和人工智能 PG 文凭,该文凭专为在职专业人士设计,提供 450 多个小时的严格培训、30 多个案例研究和作业,IIIT-B 校友身份,5 个以上实用的实践顶点项目和顶级公司的工作协助。
什么是决策树?
决策树用于直观地组织和组织决策信息。 绘制树木,使根在顶部,叶子在底部。 决策树从下往上读取,从左到右移动。 树的每一层都是进一步测试的基础,每一层的决定都会缩小范围,直到问题得到回答。 决策树将问题或决策分解为多个子决策,并遵循通往根的逻辑路径,这是主要目标。 决策树用于分析业务环境,确定优先级并提供洞察力,以决定采取什么方向。
机器学习中的决策树学习存在哪些问题?
决策树可用作测试新策略或向他人解释策略的基础。 决策树解释了在给定的一组假设下会发生什么。 它们还可用于评估过去使用的策略的性能。 众所周知,决策树因其所有分支而太容易出错。 决策树并不总是准确的,因为有时它们没有考虑所有可能的变量,并且分析决策树的人可能不会在特定情况的所有方面都有经验。
什么样的数据最适合决策树?
决策树可帮助您使用类似结构的流程图来查找数据中的模式。 最好的数据类型是定性的、分类的和数字的。 尽管决策树适用于所有类型的数据,但它们最适用于数字数据。 它们必须能够具有数字值,或者应该有办法将它们转换为数字。 决策树在很大程度上取决于数据的类型和数量。 如果数据点的数量超过 100,决策树将是一个很好的模型。