
Régression isotonique dans l'apprentissage automatique : comprendre les régressions dans l'apprentissage automatique
Publié: 2020-12-21Il existe différents types de modèles de régression (algorithmes) qui sont utilisés pour former des programmes d'apprentissage automatique, tels que la régression linéaire, logistique, ridge et lasso. Parmi ceux-ci, le modèle de régression linéaire est le modèle de régression le plus basique et le plus largement utilisé. La régression isotonique dans l'apprentissage automatique est basée sur la régression linéaire. Par conséquent, avant de passer à la régression isotonique, examinons d'abord la régression linéaire dans l'apprentissage automatique.
Table des matières
Comprendre la régression linéaire dans l'apprentissage automatique
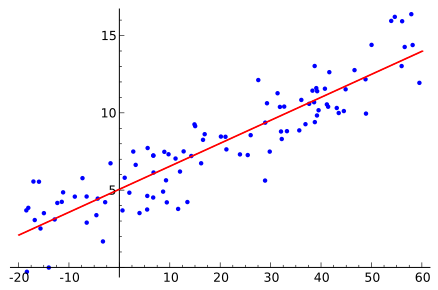
La source
Le modèle de régression linéaire est utilisé pour déterminer la relation entre les variables dépendantes et indépendantes. Il suppose une relation linéaire, représentée par la ligne de meilleur ajustement, entre les deux variables. L'équation y= mx + c + e est utilisée pour désigner le modèle de régression linéaire où :
m= pente de la droite
c= intercepter
e= erreur dans le modèle

Le modèle de régression linéaire est sensible aux valeurs aberrantes, très rigide et ne peut donc pas être utilisé pour des données de grande taille. Lorsque ce modèle est déployé sur des données de test de grande taille, plusieurs instances se trouvent en dehors de la pente de la ligne, également appelées erreurs résiduelles. Des méthodes telles que la régularisation L1 et L2 peuvent être utilisées pour réduire la pente de la pente de la ligne, mais elles ne s'avèrent pas aussi utiles.
Doit lire : Explication des modèles d'apprentissage automatique
Cela limite la précision de l'algorithme d'apprentissage automatique. Une nouvelle approche de régression isotonique en apprentissage automatique est adoptée pour surmonter cette limite. Bien qu'elle ne soit pas répandue actuellement, cette approche est très puissante et peut aider à améliorer la précision du programme d'apprentissage automatique.
Comprendre la régression isotonique dans l'apprentissage automatique
Avant de plonger dans les détails techniques, comprenons la régression isotonique dans l'apprentissage automatique en termes simples.
Commençons par décoder le mot "isotonique". Le mot « isotonique » a des origines grecques, composées de deux parties, « iso » et « tonique ». Ici, « iso » signifie égal et « tonique » signifie étirement. En termes d'algorithmes d'apprentissage automatique, la régression isotonique peut donc être comprise comme un étirement égal le long de la ligne de régression linéaire. Il fonctionne sur un modèle de régression linéaire.
Examinons différents aspects liés à la régression isotonique qui nous aideront à mieux la comprendre.
1. Modèle linéaire par morceaux
Comme mentionné précédemment, la pente de la pente de la droite de régression linéaire doit être minimisée, pour laquelle les méthodes de régularisation L1 et L2 sont utilisées. L'approche de régression isotonique est complètement différente en divisant le graphique en sections par morceaux en créant des seuils et en ayant une ligne linéaire pour chaque section connectée bout à bout.
Par exemple, dans l'image ci-dessus, l'axe X peut être divisé en plusieurs sections plus petites, par exemple en intervalles égaux de 10. Chacun de ces intervalles peut être appelé bacs, tels que bin1, bin2, bin3, bin4, etc. au. L'équation linéaire devient donc maintenant,
y= m1x1 + m2x2 + m3x3 +….. mnxn + c, où :
m1, m2, m3….mn = pente de la ligne pour les bacs individuels.
Cela permet de minimiser l'erreur et de réduire la pente de la ligne de meilleur ajustement.
2. Pente non négative
Puisqu'une fonction isotonique est une fonction monotone, la pente de la solution est toujours non négative. Une diminution de la pente n'est pas autorisée lors du passage d'un seuil à l'autre. Le point le plus bas d'un seuil doit toujours être supérieur au point le plus haut du seuil précédent.
Par exemple, soit x1, x2, x3, x4…xn les valeurs des points de données considérés pour la pente dans les bacs b1, b2, b3, b4…bn. Ensuite, selon la règle, la pente doit être non négative. D'où,
f(x1) <= f(x2) <= f(x3) <= f(x4)…<= f(xn).
Ainsi, nous commençons par un point inférieur (où f(x1) est le point le plus bas) et passons progressivement à un point supérieur à chaque seuil. La pente d'un seuil peut être nulle (ligne horizontale) mais ne peut jamais être négative (pente descendante).

Lire : Idées de projets d'apprentissage automatique pour les débutants
Avantages de l'utilisation de la régression isotonique dans les modèles d'apprentissage automatique
L'utilisation de la régression isotonique offre deux avantages majeurs, qui sont discutés ci-dessous.
1. Mise à l'échelle multidimensionnelle
La régression isotonique est très utile si vous avez plusieurs variables d'entrée. Nous pouvons inspecter chaque dimension comme chaque fonction et l'interpoler de manière linéaire. Cela permet une mise à l'échelle multidimensionnelle facile.
2. Étalonnage des valeurs de probabilité
Dans la régression logistique, supposons que nous ayons une variable x et que nous désignons une probabilité p(1) où la valeur de probabilité de la variable n'augmente pas. Mais, en réalité, la valeur de probabilité est plus élevée dans le monde réel. Dans de tels cas, à des fins d'étalonnage ou d'augmentation de la probabilité de ces variables, la régression isotonique s'avère très utile.
Découvrez : Questions d'entretien sur l'apprentissage automatique
Inconvénients de l'utilisation de la régression isotonique dans les modèles d'apprentissage automatique
Il y a un inconvénient majeur à utiliser la régression isotonique, qui est discuté ci-dessous.
Risque de surajustement
Il existe un risque important de surajustement de l'hyperparamètre (K) à mesure que le nombre de contraintes isotoniques et de caractéristiques prédictives augmente, mais la méthode de workflow de validation croisée peut être utilisée pour gérer le problème.
Conclusion
Actuellement, seuls trois langages majeurs ont des packages open source avec régression isotonique. Cependant, en examinant les avantages de l'utilisation de la régression isotonique dans les problèmes d'apprentissage automatique , la portée, l'utilisation et la disponibilité des packages de régression isotonique augmenteront sûrement à l'avenir.
Nous pouvons voir que la régression isotonique remplace principalement la régression linéaire et les méthodes de normalisation L1 et L2. Par conséquent, pour être prêt pour l'avenir, il est nécessaire de se tenir informé et informé sur la régression isotonique dès maintenant !
Si vous souhaitez en savoir plus sur la régression isotonique dans l'apprentissage automatique ou sur d'autres concepts liés à l'apprentissage automatique, vous pouvez consulter le diplôme PG de IIIT-B et upGrad en apprentissage automatique et IA , qui est le programme le plus vendu en Inde avec une note de 4,5 étoiles. . Le cours compte plus de 450 heures d'apprentissage, plus de 30 études de cas et des devoirs, et aide les étudiants à acquérir des compétences recherchées liées à l'apprentissage automatique et à l'IA.
Pourquoi la régression est-elle importante dans l'apprentissage automatique ?
L'analyse de régression, une sorte d'algorithme d'apprentissage supervisé, est l'un des concepts fondamentaux de l'apprentissage automatique. La régression est utilisée pour établir la relation entre différentes variables en essayant d'estimer comment la valeur de l'une influence celle de l'autre. Dans le domaine de l'apprentissage automatique, la régression comprend des algorithmes mathématiques complexes qui aident à estimer les résultats d'une variable cible spécifique en fonction des valeurs en constante évolution d'une ou de plusieurs variables prédictives. Le type d'analyse de régression le plus populaire est la régression linéaire car il est très facile à utiliser pour faire des prévisions et des prédictions.
L'apprentissage automatique est-il la même chose que la science des données ?
Avec des mots à la mode comme la science des données et l'apprentissage automatique qui deviennent courants aujourd'hui, de nombreuses personnes se sentent souvent confuses quant à leur signification réelle. Essayons ici d'expliquer rapidement. La science des données fait référence à l'étude de volumes massifs de données générées par les organisations. Les scientifiques des données utilisent diverses techniques pour révéler des informations précieuses à partir de ces données afin que les entreprises puissent tirer le maximum d'avantages et garder une longueur d'avance sur la concurrence. L'apprentissage automatique est différent de la science des données ; il utilise des techniques de science des données pour en savoir plus sur les données qui sont ensuite utilisées pour former des machines. L'apprentissage automatique utilise des modèles mathématiques complexes pour aider les ordinateurs à apprendre sans intervention humaine.
L'apprentissage automatique est-il la même chose que l'apprentissage en profondeur ?
L'apprentissage automatique est un sous-ensemble de l'intelligence artificielle. Il utilise des algorithmes ou des modèles qui peuvent analyser les données, en tirer des enseignements, puis appliquer ces apprentissages pour aider les ordinateurs ou les machines à prendre des décisions sans intervention humaine explicite. D'autre part, l'apprentissage en profondeur est un sous-domaine de l'apprentissage automatique. Il est utilisé pour structurer des algorithmes ou des modèles mathématiques en couches pour développer un réseau neuronal artificiel qui ressemble à la structure du cerveau humain. Ce réseau de neurones peut apprendre par lui-même et prendre des décisions intelligentes en utilisant son propre cadre logique et en analysant les données.