
อธิบาย 7 ประเภทของโครงข่ายประสาทเทียมในปัญญาประดิษฐ์
เผยแพร่แล้ว: 2020-12-29Neural Networks เป็นส่วนย่อยของเทคนิค Machine Learning ซึ่งเรียนรู้ข้อมูลและรูปแบบต่าง ๆ โดยใช้ Neurons และ Hidden Layers โครงข่ายประสาทเทียมมีประสิทธิภาพมากขึ้นเนื่องจากโครงสร้างที่ซับซ้อน และสามารถนำมาใช้ในแอปพลิเคชันที่อัลกอริธึมการเรียนรู้ของเครื่องแบบเดิมไม่เพียงพอ
ในตอนท้ายของบทช่วยสอนนี้ คุณจะมีความรู้เกี่ยวกับ:
- ประวัติโดยย่อของ Neural Networks
- Neural Networks คืออะไร
- ประเภทของโครงข่ายประสาทเทียม
- เพอร์เซ็ปตรอน
- ฟีดฟอร์เวิร์ดเน็ตเวิร์ก
- Perceptron หลายชั้น
- เครือข่ายตามรัศมี
- โครงข่ายประสาทเทียม
- โครงข่ายประสาทกำเริบ
- เครือข่ายหน่วยความจำระยะสั้นระยะยาว
สารบัญ
ประวัติโดยย่อของโครงข่ายประสาทเทียม
นักวิจัยจากยุค 60 ได้ทำการวิจัยและกำหนดวิธีการเลียนแบบการทำงานของเซลล์ประสาทของมนุษย์และการทำงานของสมอง แม้ว่าการถอดรหัสจะซับซ้อนอย่างยิ่ง แต่ก็มีการนำเสนอโครงสร้างที่คล้ายกันซึ่งอาจมีประสิทธิภาพอย่างมากในการเรียนรู้รูปแบบที่ซ่อนอยู่ในข้อมูล
เกือบตลอดศตวรรษที่ 20 โครงข่ายประสาทเทียมถูกพิจารณาว่าไร้ความสามารถ พวกเขาซับซ้อนและผลงานของพวกเขาแย่ นอกจากนี้ พวกเขายังต้องการพลังประมวลผลจำนวนมากซึ่งไม่พร้อมใช้งานในขณะนั้น อย่างไรก็ตาม เมื่อทีมงานของเซอร์ เจฟฟรีย์ ฮินตัน หรือที่เรียกกันว่า “บิดาแห่งการเรียนรู้อย่างลึกซึ้ง” ได้ตีพิมพ์บทความวิจัยเรื่อง Backpropagation ตารางก็เปลี่ยนไปอย่างสิ้นเชิง ตอนนี้ Neural Networks สามารถบรรลุได้ซึ่งไม่ได้คิดมาก่อน
โครงข่ายประสาทเทียมคืออะไร?
โครงข่ายประสาทเทียมใช้สถาปัตยกรรมของเซลล์ประสาทของมนุษย์ซึ่งมีอินพุตหลายตัว หน่วยประมวลผล และเอาต์พุตเดี่ยว/หลายรายการ มีน้ำหนักที่เกี่ยวข้องกับการเชื่อมต่อของเซลล์ประสาทแต่ละครั้ง โดยการปรับน้ำหนักเหล่านี้ โครงข่ายประสาทเทียมจะมาถึงสมการที่ใช้สำหรับการทำนายผลลัพธ์ของข้อมูลที่มองไม่เห็นใหม่ กระบวนการนี้ทำได้โดยการขยายพันธุ์ด้านหลังและการปรับปรุงตุ้มน้ำหนัก
ประเภทของโครงข่ายประสาทเทียม
โครงข่ายประสาทเทียมประเภทต่างๆ ใช้สำหรับข้อมูลและแอปพลิเคชันต่างๆ สถาปัตยกรรมต่างๆ ของโครงข่ายประสาทเทียมได้รับการออกแบบมาโดยเฉพาะเพื่อทำงานกับข้อมูลหรือโดเมนบางประเภทโดยเฉพาะ เริ่มจากสิ่งพื้นฐานที่สุดและไปสู่สิ่งที่ซับซ้อนยิ่งขึ้น

เพอร์เซ็ปตรอน
Perceptron เป็นโครงข่ายประสาทรูปแบบพื้นฐานและเก่าแก่ที่สุด ประกอบด้วยเซลล์ประสาทเพียง 1 เซลล์ที่รับอินพุตและใช้ฟังก์ชันการเปิดใช้งานเพื่อสร้างเอาต์พุตไบนารี ไม่มีเลเยอร์ที่ซ่อนอยู่และสามารถใช้ได้เฉพาะสำหรับงานจัดประเภทไบนารีเท่านั้น
เซลล์ประสาททำการประมวลผลการเพิ่มค่าอินพุตด้วยน้ำหนัก ผลรวมที่ได้จะถูกส่งไปยังฟังก์ชันการเปิดใช้งานเพื่อสร้างเอาต์พุตไบนารี
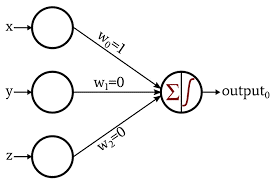
ที่มาของภาพ
เรียนรู้เกี่ยวกับ: การเรียนรู้เชิงลึกกับโครงข่ายประสาทเทียม
เครือข่ายฟีดฟอร์เวิร์ด
เครือข่าย Feed Forward (FF) ประกอบด้วยเซลล์ประสาทหลายเซลล์และเลเยอร์ที่ซ่อนอยู่ซึ่งเชื่อมต่อซึ่งกันและกัน สิ่งเหล่านี้เรียกว่า "ฟีดไปข้างหน้า" เนื่องจากข้อมูลไหลในทิศทางไปข้างหน้าเท่านั้น และไม่มีการแพร่กระจายย้อนกลับ เลเยอร์ที่ซ่อนอยู่อาจไม่จำเป็นต้องปรากฏในเครือข่าย ทั้งนี้ขึ้นอยู่กับแอปพลิเคชัน
จำนวนชั้นที่มากขึ้นสามารถกำหนดน้ำหนักเองได้ และด้วยเหตุนี้ความสามารถของเครือข่ายในการเรียนรู้มากขึ้น ตุ้มน้ำหนักจะไม่ได้รับการอัปเดตเนื่องจากไม่มีการแพร่กลับ เอาต์พุตของการคูณน้ำหนักด้วยอินพุตจะถูกป้อนไปยังฟังก์ชันการเปิดใช้งานซึ่งทำหน้าที่เป็นค่าขีดจำกัด
เครือข่าย FF ใช้ใน:
- การจำแนกประเภท
- การรู้จำเสียง
- การจดจำใบหน้า
- การจดจำรูปแบบ
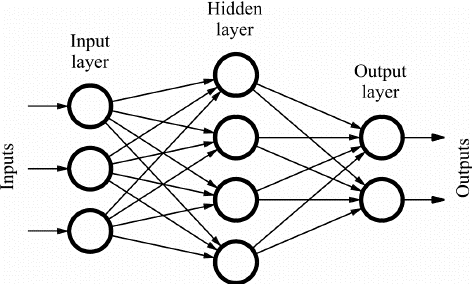
ที่มาของภาพ
Perceptron หลายชั้น
ข้อบกพร่องหลักของเครือข่าย Feed Forward คือการไม่สามารถเรียนรู้ด้วย backpropagation Perceptrons แบบหลายชั้นคือโครงข่ายประสาทเทียมที่รวมเลเยอร์ที่ซ่อนอยู่หลายชั้นและฟังก์ชันการเปิดใช้งาน การเรียนรู้เกิดขึ้นในลักษณะที่มีการควบคุมดูแล โดยจะมีการอัพเดทน้ำหนักโดยใช้ Gradient Descent
Perceptron แบบหลายชั้นเป็นแบบสองทิศทาง กล่าวคือ การขยายพันธุ์ไปข้างหน้าของอินพุต และการขยายพันธุ์แบบย้อนหลังของการอัปเดตน้ำหนัก ฟังก์ชันการเปิดใช้งานสามารถเปลี่ยนแปลงได้ตามประเภทของเป้าหมาย โดยปกติแล้ว Softmax จะใช้สำหรับการจำแนกประเภทหลายคลาส, Sigmoid สำหรับการจำแนกประเภทไบนารีและอื่นๆ สิ่งเหล่านี้เรียกว่าเครือข่ายหนาแน่นเพราะเซลล์ประสาททั้งหมดในชั้นหนึ่งเชื่อมต่อกับเซลล์ประสาททั้งหมดในชั้นถัดไป
ใช้ในแอปพลิเคชันที่ใช้ Deep Learning แต่โดยทั่วไปจะช้าเนื่องจากโครงสร้างที่ซับซ้อน
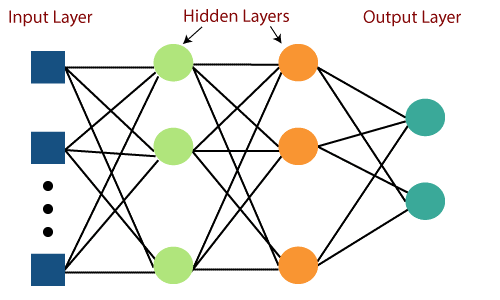
ที่มาของภาพ
เครือข่ายพื้นฐานเรเดียล
Radial Basis Networks (RBN) ใช้วิธีทำนายเป้าหมายที่แตกต่างไปจากเดิมอย่างสิ้นเชิง ประกอบด้วยเลเยอร์อินพุต เลเยอร์ที่มีเซลล์ประสาท RBF และเอาต์พุต เซลล์ประสาท RBF เก็บคลาสจริงสำหรับอินสแตนซ์ข้อมูลการฝึกอบรมแต่ละรายการ RBN นั้นแตกต่างจาก Multilayer perceptron ปกติเนื่องจากฟังก์ชัน Radial ที่ใช้เป็นฟังก์ชันการเปิดใช้งาน

เมื่อข้อมูลใหม่ถูกป้อนเข้าสู่โครงข่ายประสาทเทียม เซลล์ประสาท RBF จะเปรียบเทียบระยะห่างแบบยุคลิเดียนของค่าคุณลักษณะกับคลาสจริงที่จัดเก็บไว้ในเซลล์ประสาท ซึ่งคล้ายกับการค้นหาว่าอินสแตนซ์ใดเป็นของคลัสเตอร์ใด คลาสที่ระยะทางน้อยที่สุดถูกกำหนดเป็นคลาสที่คาดการณ์ไว้
RBN ส่วนใหญ่จะใช้ในแอปพลิเคชันการประมาณฟังก์ชัน เช่น ระบบ Power Restoration
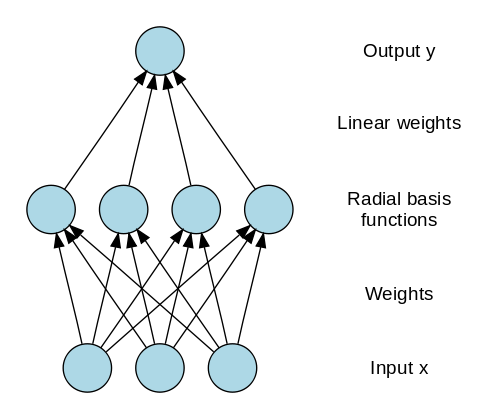
ที่มาของภาพ
อ่าน เพิ่มเติม : แอปพลิเคชั่น Neural Network ในโลกแห่งความจริง
โครงข่ายประสาทเทียม
เมื่อพูดถึงการจัดประเภทรูปภาพ โครงข่ายประสาทเทียมที่ใช้มากที่สุดคือ Convolution Neural Networks (CNN) CNN มีเลเยอร์การบิดหลายชั้นซึ่งมีหน้าที่ในการดึงคุณสมบัติที่สำคัญออกจากภาพ เลเยอร์ก่อนหน้านี้รับผิดชอบรายละเอียดระดับต่ำ และเลเยอร์ต่อมามีหน้าที่รับผิดชอบในคุณสมบัติระดับสูงมากขึ้น
การดำเนินการ Convolution ใช้เมทริกซ์แบบกำหนดเอง หรือที่เรียกว่าเป็นตัวกรอง เพื่อแปลงเป็นรูปภาพอินพุตและสร้างแผนที่ ตัวกรองเหล่านี้เริ่มต้นแบบสุ่ม จากนั้นจะอัปเดตผ่านการขยายพันธุ์ย้อนหลัง ตัวอย่างหนึ่งของตัวกรองดังกล่าวคือ Canny Edge Detector ซึ่งใช้เพื่อค้นหาขอบในภาพใดๆ
หลังจากเลเยอร์ Convolution มีเลเยอร์การรวมซึ่งรับผิดชอบการรวมของแผนที่ที่สร้างจากเลเยอร์ที่บิดเบี้ยว อาจเป็น Max Pooling, Min Pooling เป็นต้น สำหรับการทำให้เป็นมาตรฐาน CNN ยังรวมตัวเลือกสำหรับการเพิ่มเลเยอร์ dropout ซึ่งจะทำให้เซลล์ประสาทบางตัวไม่ทำงานเพื่อลด overfitting และ convergence ที่เร็วขึ้น
CNN ใช้ ReLU (Rectified Linear Unit) เป็นฟังก์ชันการเปิดใช้งานในเลเยอร์ที่ซ่อนอยู่ ในฐานะที่เป็นเลเยอร์สุดท้าย CNNs มีเลเยอร์หนาแน่นที่เชื่อมต่ออย่างสมบูรณ์และฟังก์ชั่นการเปิดใช้งานส่วนใหญ่เป็น Softmax สำหรับการจำแนกประเภท และส่วนใหญ่เป็น ReLU สำหรับการถดถอย
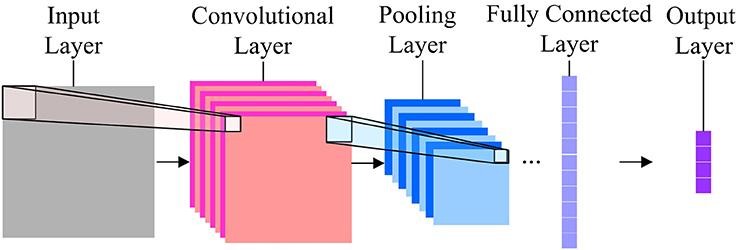
ที่มาของภาพ
โครงข่ายประสาทกำเริบ
โครงข่ายประสาทที่เกิดซ้ำจะปรากฎขึ้นเมื่อมีความจำเป็นในการคาดคะเนโดยใช้ข้อมูลตามลำดับ ข้อมูลตามลำดับอาจเป็นลำดับของรูปภาพ คำ ฯลฯ RNN มีโครงสร้างคล้ายกับเครือข่าย Feed-Forward ยกเว้นว่าเลเยอร์ยังได้รับอินพุตล่าช้าตามเวลาของการทำนายอินสแตนซ์ก่อนหน้า การทำนายอินสแตนซ์นี้ถูกเก็บไว้ในเซลล์ RNN ซึ่งเป็นอินพุตที่สองสำหรับทุกการคาดการณ์
อย่างไรก็ตาม ข้อเสียเปรียบหลักของ RNN คือปัญหา Vanishing Gradient ซึ่งทำให้จำน้ำหนักของเลเยอร์ก่อนหน้าได้ยากมาก
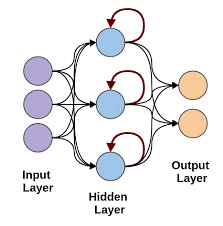
ที่มาของภาพ
เครือข่ายหน่วยความจำระยะสั้นระยะยาว
โครงข่ายประสาทเทียม LSTM เอาชนะปัญหา Vanishing Gradient ใน RNN โดยการเพิ่มเซลล์หน่วยความจำพิเศษที่สามารถเก็บข้อมูลได้เป็นเวลานาน LSTM ใช้เกทเพื่อกำหนดว่าควรใช้หรือลืมเอาต์พุตใด ใช้ 3 ประตู: ประตูเข้า ประตูออก และประตูลืม ประตูเข้าควบคุมข้อมูลทั้งหมดที่ควรเก็บไว้ในหน่วยความจำ ประตูเอาต์พุตจะควบคุมข้อมูลที่มอบให้กับเลเยอร์ถัดไป และประตูที่ลืมจะควบคุมว่าเมื่อใดควรถ่ายโอนข้อมูล/ลืมข้อมูลโดยไม่จำเป็น
LSTM ถูกนำมาใช้ในการใช้งานต่างๆ เช่น:
- การจดจำท่าทาง
- การรู้จำเสียง
- การทำนายข้อความ
ก่อนที่คุณจะไป
โครงข่ายประสาทเทียมอาจซับซ้อนมากภายในเวลาไม่นาน คุณยังคงเพิ่มเลเยอร์ในเครือข่ายต่อไป มีบางครั้งที่เราสามารถใช้ประโยชน์จากการวิจัยขนาดใหญ่ในสาขานี้โดยใช้เครือข่ายที่ได้รับการฝึกอบรมล่วงหน้าสำหรับการใช้งานของเรา
นี้เรียกว่าโอนการเรียนรู้ ในบทช่วยสอนนี้ เราได้กล่าวถึงโครงข่ายประสาทพื้นฐานส่วนใหญ่และการทำงานของโครงข่ายประสาทเหล่านี้ อย่าลืมลองใช้กรอบเหล่านี้ด้วย Deep Learning เช่น Keras และ Tensorflow
หากคุณสนใจที่จะเรียนรู้เพิ่มเติมเกี่ยวกับโครงข่ายประสาทเทียม แมชชีนเลิร์นนิง & AI โปรดดูประกาศนียบัตร PG ของ IIIT-B & upGrad ในการเรียนรู้ด้วยเครื่องและ AI ซึ่งออกแบบมาสำหรับมืออาชีพที่ทำงานและมีการฝึกอบรมที่เข้มงวดมากกว่า 450 ชั่วโมง กรณีศึกษามากกว่า 30 รายการ & การมอบหมาย, สถานะศิษย์เก่า IIIT-B, 5+ โครงการหลักที่ใช้งานได้จริง & ความช่วยเหลือด้านงานกับ บริษัท ชั้นนำ
โครงข่ายประสาทเทียมคืออะไร?
โครงข่ายประสาทเทียมเป็นแบบจำลองความน่าจะเป็นที่สามารถใช้ในการจำแนกประเภทและการถดถอยแบบไม่เชิงเส้น ซึ่งหมายถึงการประมาณการแมปจากพื้นที่อินพุตไปยังพื้นที่เอาต์พุต สิ่งที่น่าสนใจเกี่ยวกับโครงข่ายประสาทเทียมคือ มันสามารถฝึกด้วยข้อมูลจำนวนมาก และสามารถใช้เพื่อสร้างแบบจำลองพฤติกรรมไม่เชิงเส้นที่ซับซ้อนได้ พวกเขาสามารถฝึกได้ด้วยตัวอย่างมากมาย และสามารถใช้เพื่อค้นหารูปแบบโดยไม่มีคำแนะนำใดๆ ดังนั้นโครงข่ายประสาทเทียมจึงถูกใช้ในหลาย ๆ แอปพลิเคชันที่มีการสุ่มและมีความซับซ้อน
3 หมวดหมู่หลักของโครงข่ายประสาทเทียมคืออะไร?
โครงข่ายประสาทเทียมเป็นวิธีการคำนวณเพื่อการเรียนรู้ ซึ่งคล้ายกับสมอง โครงข่ายประสาทเทียมมีสามประเภทหลัก การจำแนกประเภท การเรียนรู้ตามลำดับ และการประมาณฟังก์ชันเป็นสามหมวดหมู่หลักของโครงข่ายประสาทเทียม มีเครือข่ายประสาทหลายประเภทเช่น Perceptron, Hopfield, แผนที่ที่จัดระเบียบตัวเอง, เครื่อง Boltzmann, เครือข่ายความเชื่อลึก, ตัวเข้ารหัสอัตโนมัติ, เครือข่ายประสาท Convolutional, เครื่อง Boltzmann ที่ถูก จำกัด , เครือข่ายประสาทที่มีคุณค่าอย่างต่อเนื่อง, เครือข่ายประสาทที่เกิดซ้ำและเครือข่ายลิงค์ที่ใช้งานได้
โครงข่ายประสาทเทียมมีข้อจำกัดอย่างไร?
โครงข่ายประสาทสามารถแก้ปัญหาที่มีอินพุตจำนวนมากและเอาต์พุตจำนวนมาก แต่ก็มีข้อจำกัดสำหรับโครงข่ายประสาทเช่นกัน โครงข่ายประสาทส่วนใหญ่จะใช้ในการจำแนกประเภท พวกมันทำงานได้ดีมากสำหรับการถดถอย และนี่คือจุดที่สำคัญมาก: โครงข่ายประสาทต้องการข้อมูลการฝึกจำนวนมาก หากชุดข้อมูลมีขนาดเล็ก โครงข่ายประสาทจะไม่สามารถเรียนรู้กฎพื้นฐานได้ ข้อจำกัดอีกประการหนึ่งสำหรับโครงข่ายประสาทคือพวกมันคือกล่องดำ พวกเขาไม่โปร่งใส โครงสร้างภายในของโครงข่ายประสาทเทียมนั้นไม่ง่ายที่จะเข้าใจ