
人工智能中的 7 种神经网络类型解释
已发表: 2020-12-29神经网络是机器学习技术的一个子集,它利用神经元和隐藏层以不同的方式学习数据和模式。 神经网络由于其复杂的结构而更加强大,并且可以用于传统机器学习算法无法满足的应用。
在本教程结束时,您将掌握以下知识:
- 神经网络简史
- 什么是神经网络
- 神经网络的类型
- 感知器
- 前馈网络
- 多层感知器
- 径向网络
- 卷积神经网络
- 递归神经网络
- 长短期记忆网络
目录
神经网络简史
上世纪 60 年代的研究人员一直在研究和制定模仿人类神经元功能和大脑运作方式的方法。 尽管解码非常复杂,但提出了一种类似的结构,可以非常有效地学习数据中的隐藏模式。
在 20 世纪的大部分时间里,神经网络被认为是无能的。 它们很复杂,性能很差。 此外,他们需要大量的计算能力,而这在当时是不可用的。 然而,当 Geoffrey Hinton 爵士(也被称为“深度学习之父”)的团队发表了关于反向传播的研究论文时,局面彻底扭转了。 神经网络现在可以实现以前没有想到的。
什么是神经网络?
神经网络使用具有多个输入、一个处理单元和单个/多个输出的人类神经元架构。 每个神经元连接都有权重。 通过调整这些权重,神经网络得出一个方程,用于预测新的未见数据的输出。 这个过程是通过反向传播和更新权重来完成的。
神经网络的类型
不同类型的神经网络用于不同的数据和应用。 神经网络的不同架构专门设计用于处理那些特定类型的数据或领域。 让我们从最基本的开始,向更复杂的方向发展。

感知器
感知器是最基本和最古老的神经网络形式。 它仅由 1 个神经元组成,该神经元接受输入并对其应用激活函数以产生二进制输出。 它不包含任何隐藏层,只能用于二进制分类任务。
神经元使用它们的权重来处理输入值的加法。 然后将结果和传递给激活函数以产生二进制输出。
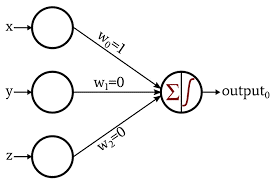
图片来源
了解:深度学习与神经网络
前馈网络
前馈(FF)网络由相互连接的多个神经元和隐藏层组成。 这些被称为“前馈”,因为数据仅在前向方向流动,没有反向传播。 取决于应用程序,隐藏层可能不一定存在于网络中。
层数越多,可以自定义权重。 因此,更多的将是网络学习的能力。 由于没有反向传播,权重不会更新。 权重与输入相乘的输出被馈送到充当阈值的激活函数。
FF 网络用于:
- 分类
- 语音识别
- 人脸识别
- 模式识别
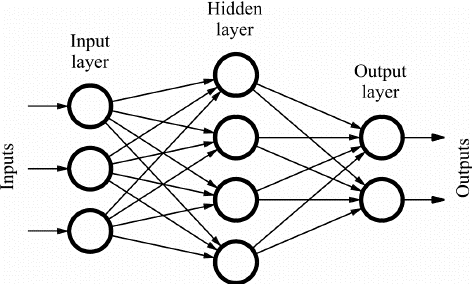
图片来源
多层感知器
前馈网络的主要缺点是无法通过反向传播进行学习。 多层感知器是包含多个隐藏层和激活函数的神经网络。 学习以监督方式进行,其中权重通过梯度下降进行更新。
多层感知器是双向的,即输入的前向传播和权重更新的后向传播。 激活函数可以根据目标的类型而改变。 Softmax 通常用于多类分类,Sigmoid 用于二分类等。 这些也称为密集网络,因为一层中的所有神经元都连接到下一层中的所有神经元。
它们用于基于深度学习的应用程序中,但由于其复杂的结构,通常速度较慢。

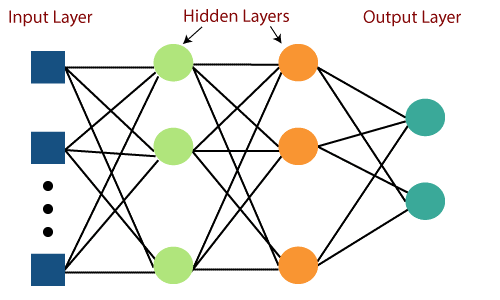
图片来源
径向基网络
径向基网络 (RBN) 使用完全不同的方式来预测目标。 它由一个输入层、一个带有 RBF 神经元的层和一个输出组成。 RBF 神经元存储每个训练数据实例的实际类。 RBN 与通常的多层感知器不同,因为径向函数用作激活函数。
当新数据输入神经网络时,RBF 神经元将特征值的欧几里得距离与存储在神经元中的实际类别进行比较。 这类似于查找特定实例属于哪个集群。 距离最小的类被指定为预测类。
RBN 主要用于函数逼近应用,如电力恢复系统。
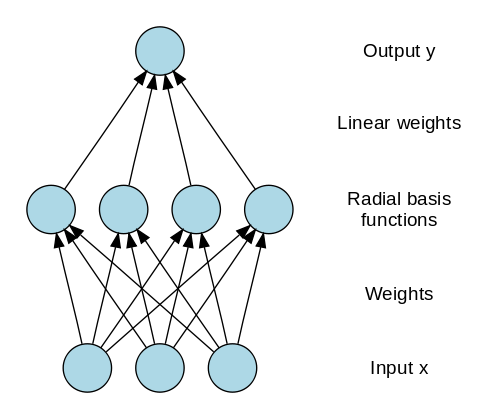
图片来源
另请阅读:现实世界中的神经网络应用
卷积神经网络
在图像分类方面,最常用的神经网络是卷积神经网络 (CNN)。 CNN 包含多个卷积层,负责从图像中提取重要特征。 较早的层负责低级细节,而较晚的层负责更高级的特征。
卷积操作使用自定义矩阵(也称为过滤器)对输入图像进行卷积并生成地图。 这些过滤器随机初始化,然后通过反向传播更新。 这种过滤器的一个例子是 Canny 边缘检测器,它用于查找任何图像中的边缘。
在卷积层之后,有一个池化层,负责聚合从卷积层生成的地图。 它可以是 Max Pooling、Min Pooling 等。对于正则化,CNN 还包括一个添加 dropout 层的选项,这些层会丢弃或使某些神经元不活跃,以减少过度拟合和更快的收敛。
CNN 使用 ReLU(整流线性单元)作为隐藏层中的激活函数。 作为最后一层,CNNs 有一个全连接的密集层,激活函数主要是用于分类的 Softmax,主要是用于回归的 ReLU。
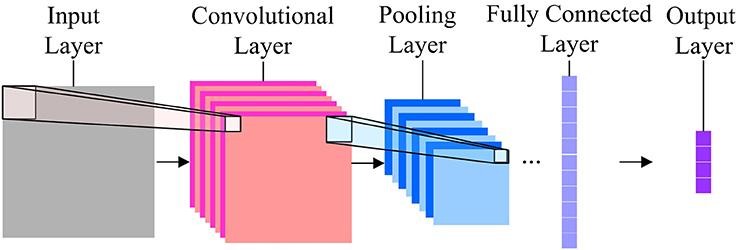
图片来源
递归神经网络
当需要使用顺序数据进行预测时,递归神经网络就会出现。 序列数据可以是图像、单词等的序列。RNN 具有与前馈网络类似的结构,除了层还接收先前实例预测的时间延迟输入。 此实例预测存储在 RNN 单元中,这是每个预测的第二个输入。
然而,RNN 的主要缺点是梯度消失问题,这使得记住早期层的权重非常困难。
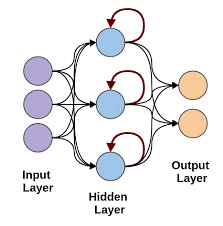
图片来源
长短期记忆网络
LSTM 神经网络通过添加一个可以长时间存储信息的特殊存储单元来克服 RNN 中梯度消失的问题。 LSTM 使用门来定义应该使用或忘记哪些输出。 它使用 3 个门:输入门、输出门和遗忘门。 输入门控制所有数据应保存在内存中的内容。 输出门控制提供给下一层的数据,而遗忘门控制何时转储/忘记不需要的数据。
LSTM 用于各种应用,例如:
- 手势识别
- 语音识别
- 文本预测
在你走之前
如果您不断在网络中添加层,神经网络很快就会变得非常复杂。 有时,我们可以通过使用预先训练的网络来利用该领域的大量研究。
这称为迁移学习。 在本教程中,我们介绍了大部分基本的神经网络及其功能。 确保使用 Keras 和 Tensorflow 等深度学习框架尝试这些。
如果您有兴趣了解有关神经网络、机器学习和人工智能的更多信息,请查看 IIIT-B 和 upGrad 的机器学习和人工智能 PG 文凭,该文凭专为在职专业人士设计,提供 450 多个小时的严格培训、30 多个案例研究和分配,IIIT-B 校友身份,5 个以上实用的实践顶点项目和顶级公司的工作协助。
什么是神经网络?
神经网络是可用于执行非线性分类和回归的概率模型,这意味着近似从输入空间到输出空间的映射。 神经网络的有趣之处在于,它们可以用大量数据进行训练,并且可以用来对复杂的非线性行为进行建模。 它们可以通过大量示例进行训练,并且可以在没有任何指导的情况下用于查找模式。 因此,神经网络被用于许多具有随机性和复杂性的应用中。
神经网络的三大类是什么?
神经网络是一种计算学习方法,类似于大脑。 神经网络主要分为三大类。 分类、序列学习和函数逼近是神经网络的三大类。 有许多类型的神经网络,如感知器、Hopfield、自组织图、玻尔兹曼机、深度信念网络、自动编码器、卷积神经网络、受限玻尔兹曼机、连续值神经网络、循环神经网络和功能链接网络。
神经网络的局限性是什么?
神经网络可以解决具有大量输入和大量输出的问题。 但是神经网络也有局限性。 神经网络主要用于分类。 它们在回归方面表现非常糟糕。 这是非常重要的一点:神经网络需要大量的训练数据。 如果数据集很小,那么神经网络将无法学习底层规则。 神经网络的另一个限制是它们是黑盒子。 它们不透明。 神经网络的内部结构并不容易理解。