
Objaśnienie 7 rodzajów sieci neuronowych w sztucznej inteligencji
Opublikowany: 2020-12-29Sieci neuronowe to podzbiór technik uczenia maszynowego, które uczą się danych i wzorców w inny sposób, wykorzystując neurony i warstwy ukryte. Sieci neuronowe są znacznie potężniejsze ze względu na swoją złożoną strukturę i mogą być używane w aplikacjach, w których tradycyjne algorytmy uczenia maszynowego po prostu nie wystarczają.
Pod koniec tego samouczka będziesz mieć wiedzę na temat:
- Krótka historia sieci neuronowych
- Czym są sieci neuronowe
- Rodzaje sieci neuronowych
- Perceptron
- Sieci przekazujące informacje
- Perceptron wielowarstwowy
- Sieci promieniowe
- Konwolucyjne sieci neuronowe
- Rekurencyjne sieci neuronowe
- Sieci pamięci krótkotrwałej
Spis treści
Krótka historia sieci neuronowych
Naukowcy z lat 60. badali i formułowali sposoby naśladowania funkcjonowania ludzkich neuronów i działania mózgu. Chociaż dekodowanie jest niezwykle skomplikowane, zaproponowano podobną strukturę, która może być niezwykle skuteczna w nauce ukrytych wzorców w Danych.
Przez większość XX wieku sieci neuronowe uważano za niekompetentne. Były złożone, a ich wydajność była słaba. Ponadto wymagały dużej mocy obliczeniowej, która nie była wówczas dostępna. Jednak kiedy zespół Sir Geoffreya Hintona, nazywany również „Ojcem głębokiego uczenia”, opublikował artykuł badawczy na temat propagacji wstecznej, sytuacja całkowicie się odwróciła. Sieci neuronowe mogły teraz osiągnąć to, o czym nie myślano.
Co to są sieci neuronowe?
Sieci neuronowe wykorzystują architekturę ludzkich neuronów, które mają wiele wejść, jednostkę przetwarzającą i pojedyncze/wielokrotne wyjścia. Z każdym połączeniem neuronów związane są wagi. Dostosowując te wagi, sieć neuronowa uzyskuje równanie, które służy do przewidywania wyników nowych niewidocznych danych. Proces ten odbywa się poprzez wsteczną propagację i aktualizację wag.
Rodzaje sieci neuronowych
Różne typy sieci neuronowych są używane do różnych danych i aplikacji. Różne architektury sieci neuronowych są specjalnie zaprojektowane do pracy z tymi konkretnymi typami danych lub domen. Zacznijmy od najbardziej podstawowych i przejdźmy do bardziej złożonych.

Perceptron
Perceptron jest najbardziej podstawową i najstarszą formą sieci neuronowych. Składa się tylko z 1 neuronu, który pobiera dane wejściowe i stosuje na nim funkcję aktywacji w celu wytworzenia wyjścia binarnego. Nie zawiera żadnych ukrytych warstw i może być używany tylko do zadań klasyfikacji binarnej.
Neuron przetwarza dodawanie wartości wejściowych wraz z ich wagami. Otrzymana suma jest następnie przekazywana do funkcji aktywacji w celu wytworzenia wyjścia binarnego.
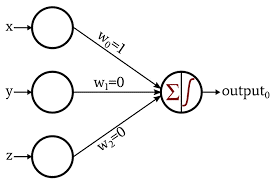
Źródło obrazu
Dowiedz się więcej o: Głębokie uczenie a sieci neuronowe
Feed Forward Network
Sieci Feed Forward (FF) składają się z wielu neuronów i ukrytych warstw, które są ze sobą połączone. Są one nazywane „feed-forward”, ponieważ dane przepływają tylko w kierunku do przodu i nie ma propagacji wstecznej. Ukryte warstwy mogą niekoniecznie być obecne w sieci, w zależności od aplikacji.
Większa liczba warstw może być dostosowana do ciężarów. A zatem większa będzie zdolność sieci do uczenia się. Wagi nie są aktualizowane, ponieważ nie ma propagacji wstecznej. Wyjście wielokrotności wag z wejściami jest podawane do funkcji aktywacji, która pełni rolę wartości progowej.
Sieci FF są wykorzystywane w:
- Klasyfikacja
- Rozpoznawanie mowy
- Rozpoznawanie twarzy
- Rozpoznawanie wzorców
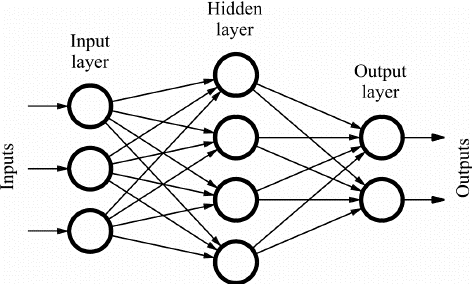
Źródło obrazu
Perceptron wielowarstwowy
Główną wadą sieci Feed Forward była niezdolność do uczenia się z propagacją wsteczną. Perceptrony wielowarstwowe to sieci neuronowe, które zawierają wiele ukrytych warstw i funkcji aktywacji. Nauka odbywa się w sposób nadzorowany, gdzie wagi są aktualizowane za pomocą funkcji Gradient Descent.
Perceptron wielowarstwowy jest dwukierunkowy, tj. propagacja do przodu sygnałów wejściowych i propagacja wsteczna aktualizacji wagi. Funkcje aktywacji mogą być zmianami w zależności od rodzaju celu. Softmax jest zwykle używany do klasyfikacji wieloklasowej, Sigmoid do klasyfikacji binarnej i tak dalej. Są one również nazywane gęstymi sieciami, ponieważ wszystkie neurony w warstwie są połączone ze wszystkimi neuronami w następnej warstwie.
Są używane w aplikacjach opartych na głębokim uczeniu, ale generalnie są powolne ze względu na złożoną strukturę.
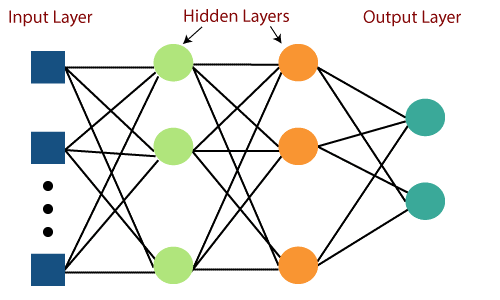
Źródło obrazu
Radialne sieci bazowe
Radial Basis Networks (RBN) wykorzystują zupełnie inny sposób przewidywania celów. Składa się z warstwy wejściowej, warstwy z neuronami RBF i wyjściowej. Neurony RBF przechowują rzeczywiste klasy dla każdej instancji danych uczących. RBN różnią się od zwykłego perceptronu wielowarstwowego z powodu funkcji promieniowej używanej jako funkcja aktywacji.

Kiedy nowe dane są wprowadzane do sieci neuronowej, neurony RBF porównują odległość euklidesową wartości cech z rzeczywistymi klasami przechowywanymi w neuronach. Jest to podobne do znajdowania klastra, do którego należy dana instancja. Klasa, w której odległość jest minimalna, jest przypisywana jako przewidywana klasa.
RBN są używane głównie w aplikacjach aproksymacji funkcji, takich jak systemy przywracania mocy.
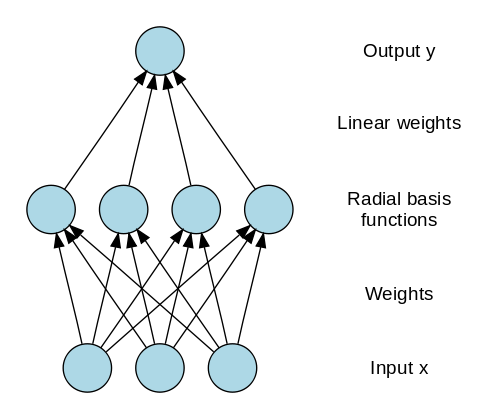
Źródło obrazu
Przeczytaj także : Aplikacje sieci neuronowych w świecie rzeczywistym
Konwolucyjne sieci neuronowe
Jeśli chodzi o klasyfikację obrazów, najczęściej używane sieci neuronowe to Convolution Neural Networks (CNN). CNN zawiera wiele warstw splotu, które są odpowiedzialne za wydobycie ważnych cech z obrazu. Wcześniejsze warstwy są odpowiedzialne za szczegóły niskiego poziomu, a późniejsze warstwy odpowiadają za więcej obiektów na wysokim poziomie.
Operacja Convolution wykorzystuje niestandardową macierz, zwaną również filtrami, do splatania obrazu wejściowego i tworzenia map. Filtry te są inicjowane losowo, a następnie aktualizowane przez wsteczną propagację. Jednym z przykładów takiego filtra jest Canny Edge Detector, który służy do znajdowania krawędzi na dowolnym obrazie.
Po warstwie konwolucyjnej znajduje się warstwa puli, która odpowiada za agregację map wytworzonych z warstwy konwolucyjnej. Może to być Max Pooling, Min Pooling itp. W celu regularyzacji, CNN zawierają również opcję dodawania warstw dropout, które upuszczają lub powodują nieaktywność niektórych neuronów w celu zmniejszenia przepełnienia i szybszej konwergencji.
Sieci CNN używają ReLU (Rectified Linear Unit) jako funkcji aktywacji w warstwach ukrytych. Jako ostatnia warstwa, CNN mają w pełni połączoną gęstą warstwę i funkcję aktywacji głównie jako Softmax do klasyfikacji i głównie ReLU do regresji.
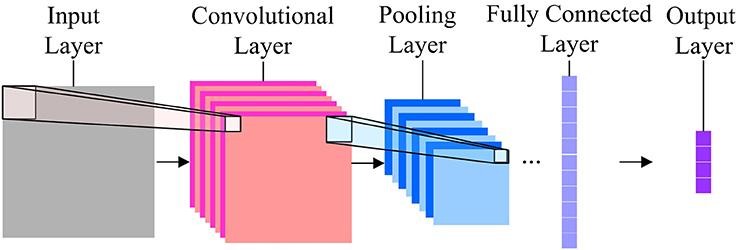
Źródło obrazu
Rekurencyjne sieci neuronowe
Rekurencyjne sieci neuronowe pojawiają się, gdy istnieje potrzeba przewidywania przy użyciu danych sekwencyjnych. Dane sekwencyjne mogą być sekwencją obrazów, słów itp. RNN ma podobną strukturę do sieci Feed-Forward, z wyjątkiem tego, że warstwy otrzymują również opóźnione w czasie dane wejściowe predykcji poprzedniej instancji. Ta predykcja instancji jest przechowywana w komórce RNN, która jest drugim wejściem dla każdej predykcji.
Jednak główną wadą RNN jest problem znikającego gradientu, który bardzo utrudnia zapamiętanie wag wcześniejszych warstw.
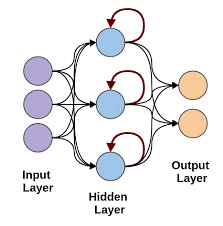
Źródło obrazu
Sieci pamięci krótkotrwałej
Sieci neuronowe LSTM rozwiązują problem znikającego gradientu w sieciach RNN, dodając specjalną komórkę pamięci, która może przechowywać informacje przez długi czas. LSTM używa bramek do zdefiniowania, które wyjście powinno zostać użyte lub zapomniane. Wykorzystuje 3 bramki: bramkę wejściową, bramkę wyjściową i bramkę zapomnij. Bramka wejściowa kontroluje, jakie dane powinny być przechowywane w pamięci. Bramka wyjściowa kontroluje dane przekazywane do następnej warstwy, a bramka zapominania kontroluje, kiedy zrzucić/zapomnieć dane, które nie są wymagane.
LSTM są używane w różnych aplikacjach, takich jak:
- Rozpoznawanie gestów
- Rozpoznawanie mowy
- Przewidywanie tekstu
Zanim pójdziesz
Sieci neuronowe mogą stać się bardzo złożone w krótkim czasie, gdy będziesz dodawać kolejne warstwy w sieci. Są chwile, kiedy możemy wykorzystać ogromne badania w tej dziedzinie, korzystając z wcześniej przeszkolonych sieci do naszego użytku.
Nazywa się to transferem uczenia się. W tym samouczku omówiliśmy większość podstawowych sieci neuronowych i ich działanie. Wypróbuj je, korzystając z platform Deep Learning, takich jak Keras i Tensorflow.
Jeśli chcesz dowiedzieć się więcej o sieciach neuronowych, uczeniu maszynowym i sztucznej inteligencji, sprawdź dyplom PG IIIT-B i upGrad w uczeniu maszynowym i sztucznej inteligencji, który jest przeznaczony dla pracujących profesjonalistów i oferuje ponad 450 godzin rygorystycznych szkoleń, ponad 30 studiów przypadków i zadania, status absolwentów IIIT-B, ponad 5 praktycznych praktycznych projektów zwieńczenia i pomoc w pracy z najlepszymi firmami.
Czym są sieci neuronowe?
Sieci neuronowe to modele probabilistyczne, które można wykorzystać do przeprowadzenia klasyfikacji i regresji nieliniowej, co oznacza aproksymację odwzorowania z przestrzeni wejściowej do przestrzeni wyjściowej. Interesującą rzeczą w sieciach neuronowych jest to, że można je trenować przy użyciu dużej ilości danych i można ich używać do modelowania złożonego zachowania nieliniowego. Można je szkolić na wielu przykładach i można ich używać do znajdowania wzorców bez żadnych wskazówek. Tak więc sieci neuronowe są używane w wielu aplikacjach, w których występuje losowość i złożoność.
Jakie są 3 główne kategorie sieci neuronowych?
Sieć neuronowa to obliczeniowe podejście do uczenia się, analogiczne do mózgu. Istnieją trzy główne kategorie sieci neuronowych. Klasyfikacja, uczenie się sekwencji i aproksymacja funkcji to trzy główne kategorie sieci neuronowych. Istnieje wiele rodzajów sieci neuronowych, takich jak Perceptron, Hopfield, mapy samoorganizujące się, maszyny Boltzmanna, sieci głębokich przekonań, kodery automatyczne, splotowe sieci neuronowe, ograniczone maszyny Boltzmanna, sieci neuronowe o wartościach ciągłych, sieci neuronowe rekurencyjne i sieci łączy funkcjonalnych.
Jakie są ograniczenia sieci neuronowych?
Sieci neuronowe mogą rozwiązywać problemy, które mają dużą liczbę wejść i dużą liczbę wyjść. Ale są też ograniczenia dla sieci neuronowych. Do klasyfikacji wykorzystuje się głównie sieci neuronowe. Bardzo źle radzą sobie z regresją. I to jest bardzo ważny punkt: sieci neuronowe potrzebują dużej ilości danych uczących. Jeśli zbiór danych jest mały, sieci neuronowe nie będą w stanie nauczyć się podstawowych zasad. Kolejnym ograniczeniem sieci neuronowych jest to, że są one czarnymi skrzynkami. Nie są przezroczyste. Wewnętrzna struktura sieci neuronowej nie jest łatwa do zrozumienia.