
7 Arten von neuronalen Netzen in der künstlichen Intelligenz erklärt
Veröffentlicht: 2020-12-29Neuronale Netze sind eine Untergruppe von maschinellen Lerntechniken, die die Daten und Muster auf andere Weise unter Verwendung von Neuronen und verborgenen Schichten lernen. Neuronale Netze sind aufgrund ihrer komplexen Struktur viel leistungsfähiger und können in Anwendungen eingesetzt werden, bei denen herkömmliche Algorithmen für maschinelles Lernen einfach nicht ausreichen.
Am Ende dieses Tutorials verfügen Sie über folgende Kenntnisse:
- Eine kurze Geschichte der neuronalen Netze
- Was sind neuronale Netze
- Arten von neuronalen Netzen
- Perzeptron
- Feed-Forward-Netzwerke
- Mehrschichtiges Perzeptron
- Radialbasierte Netzwerke
- Faltungsneuronale Netze
- Wiederkehrende neuronale Netze
- Lange Kurzzeitgedächtnisnetzwerke
Inhaltsverzeichnis
Eine kurze Geschichte der neuronalen Netze
Forscher aus den 60er Jahren haben Möglichkeiten erforscht und entwickelt, um die Funktionsweise menschlicher Neuronen und die Funktionsweise des Gehirns nachzuahmen. Obwohl die Decodierung äußerst komplex ist, wurde eine ähnliche Struktur vorgeschlagen, die beim Erlernen verborgener Muster in Daten äußerst effizient sein könnte.
Während des größten Teils des 20. Jahrhunderts galten neuronale Netze als inkompetent. Sie waren komplex und ihre Leistung war schlecht. Außerdem benötigten sie viel Rechenleistung, die damals nicht verfügbar war. Als jedoch das Team von Sir Geoffrey Hinton, auch als „The Father of Deep Learning“ bezeichnet, das Forschungspapier über Backpropagation veröffentlichte, drehte sich das Blatt komplett um. Neuronale Netze könnten nun leisten, woran nicht gedacht wurde.
Was sind neuronale Netze?
Neuronale Netze verwenden die Architektur menschlicher Neuronen, die mehrere Eingänge, eine Verarbeitungseinheit und einzelne/mehrere Ausgänge haben. Jeder Verbindung von Neuronen sind Gewichte zugeordnet. Durch Anpassen dieser Gewichte gelangt ein neuronales Netzwerk zu einer Gleichung, die zum Vorhersagen von Ausgaben auf neuen unsichtbaren Daten verwendet wird. Dieser Prozess erfolgt durch Backpropagation und Aktualisierung der Gewichtungen.
Arten von neuronalen Netzen
Für unterschiedliche Daten und Anwendungen werden unterschiedliche Arten von neuronalen Netzen verwendet. Die unterschiedlichen Architekturen neuronaler Netze sind speziell darauf ausgelegt, mit diesen bestimmten Arten von Daten oder Domänen zu arbeiten. Beginnen wir mit den grundlegendsten und gehen wir zu komplexeren über.

Perzeptron
Das Perzeptron ist die grundlegendste und älteste Form neuronaler Netze. Es besteht aus nur einem Neuron, das die Eingabe aufnimmt und eine Aktivierungsfunktion darauf anwendet, um eine binäre Ausgabe zu erzeugen. Es enthält keine versteckten Schichten und kann nur für binäre Klassifizierungsaufgaben verwendet werden.
Das Neuron führt die Verarbeitung der Addition von Eingabewerten mit ihren Gewichten durch. Die resultierende Summe wird dann an die Aktivierungsfunktion weitergegeben, um eine binäre Ausgabe zu erzeugen.
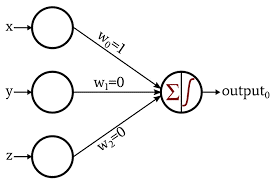
Bildquelle
Erfahren Sie mehr über: Deep Learning vs. neuronale Netze
Feed-Forward-Netzwerk
Die Feed Forward (FF)-Netzwerke bestehen aus mehreren Neuronen und verborgenen Schichten, die miteinander verbunden sind. Diese werden „Feed-Forward“ genannt, weil die Daten nur in Vorwärtsrichtung fließen und es keine Rückwärtsausbreitung gibt. Versteckte Schichten sind je nach Anwendung möglicherweise nicht unbedingt im Netzwerk vorhanden.
Je mehr Schichten, desto mehr können die Gewichte angepasst werden. Und damit wird die Lernfähigkeit des Netzwerks größer. Gewichtungen werden nicht aktualisiert, da es keine Backpropagation gibt. Der Ausgang der Multiplikation der Gewichte mit den Eingängen wird der Aktivierungsfunktion zugeführt, die als Schwellwert wirkt.
FF-Netzwerke werden eingesetzt in:
- Einstufung
- Spracherkennung
- Gesichtserkennung
- Mustererkennung
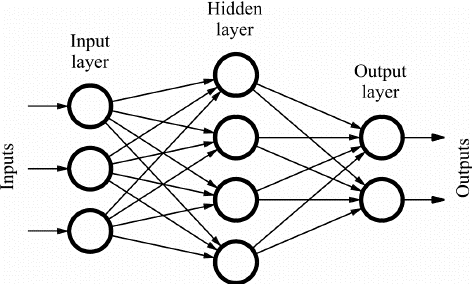
Bildquelle
Mehrschichtiges Perzeptron
Der Hauptnachteil der Feed-Forward-Netzwerke war ihre Unfähigkeit, mit Backpropagation zu lernen. Mehrschichtige Perzeptrons sind die neuronalen Netze, die mehrere verborgene Schichten und Aktivierungsfunktionen enthalten. Das Lernen findet überwacht statt, wobei die Gewichte mittels Gradient Descent aktualisiert werden.
Mehrschichtiges Perzeptron ist bidirektional, dh Vorwärtsausbreitung der Eingaben und Rückwärtsausbreitung der Gewichtungsaktualisierungen. Die Aktivierungsfunktionen können in Bezug auf die Art des Ziels geändert werden. Softmax wird normalerweise für die Mehrklassenklassifizierung verwendet, Sigmoid für die binäre Klassifizierung und so weiter. Diese werden auch als dichte Netze bezeichnet, da alle Neuronen einer Schicht mit allen Neuronen der nächsten Schicht verbunden sind.
Sie werden in Deep-Learning-basierten Anwendungen verwendet, sind jedoch aufgrund ihrer komplexen Struktur im Allgemeinen langsam.
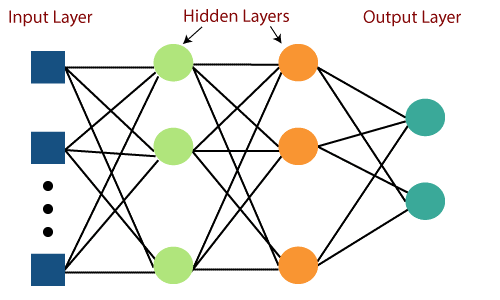
Bildquelle
Radiale Basisnetzwerke
Radiale Basisnetzwerke (RBN) verwenden eine völlig andere Methode, um die Ziele vorherzusagen. Es besteht aus einer Eingabeschicht, einer Schicht mit RBF-Neuronen und einer Ausgabe. Die RBF-Neuronen speichern die tatsächlichen Klassen für jede der Trainingsdateninstanzen. Die RBN unterscheiden sich vom üblichen Multilayer-Perzeptron aufgrund der als Aktivierungsfunktion verwendeten Radialfunktion.

Wenn die neuen Daten in das neuronale Netz eingespeist werden, vergleichen die RBF-Neuronen die euklidische Distanz der Merkmalswerte mit den tatsächlichen Klassen, die in den Neuronen gespeichert sind. Dies ähnelt dem Herausfinden, zu welchem Cluster die jeweilige Instanz gehört. Die Klasse, in der der Abstand minimal ist, wird als die vorhergesagte Klasse zugewiesen.
Die RBNs werden hauptsächlich in Funktionsnäherungsanwendungen wie Power Restoration-Systemen verwendet.
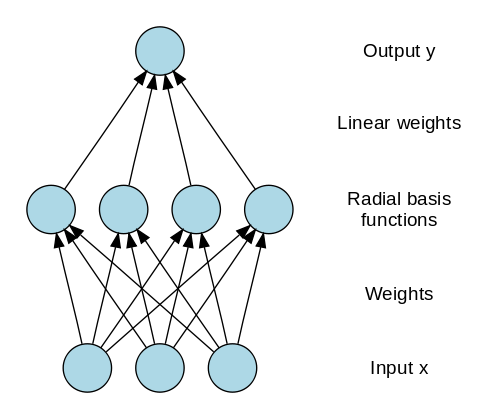
Bildquelle
Lesen Sie auch : Neuronale Netzwerkanwendungen in der realen Welt
Faltungsneuronale Netze
Wenn es um die Bildklassifizierung geht, sind Convolution Neural Networks (CNN) die am häufigsten verwendeten neuronalen Netze. CNN enthalten mehrere Faltungsschichten, die für die Extraktion wichtiger Merkmale aus dem Bild verantwortlich sind. Die früheren Schichten sind für Details auf niedriger Ebene verantwortlich, und die späteren Schichten sind für Merkmale auf höherer Ebene verantwortlich.
Die Faltungsoperation verwendet eine benutzerdefinierte Matrix, auch als Filter bezeichnet, um das Eingabebild zu falten und Karten zu erstellen. Diese Filter werden zufällig initialisiert und dann über Backpropagation aktualisiert. Ein Beispiel für einen solchen Filter ist der Canny Edge Detector, der verwendet wird, um die Kanten in jedem Bild zu finden.
Nach der Faltungsschicht gibt es eine Pooling-Schicht, die für die Aggregation der aus der Faltungsschicht erzeugten Karten verantwortlich ist. Es kann Max Pooling, Min Pooling usw. sein. Zur Regularisierung enthalten CNNs auch eine Option zum Hinzufügen von Dropout-Layern, die bestimmte Neuronen fallen lassen oder inaktiv machen, um Überanpassung und schnellere Konvergenz zu reduzieren.
CNNs verwenden ReLU (Rectified Linear Unit) als Aktivierungsfunktionen in den verborgenen Schichten. Als letzte Schicht haben die CNNs eine vollständig verbundene dichte Schicht und die Aktivierungsfunktion meistens als Softmax für die Klassifizierung und hauptsächlich als ReLU für die Regression.
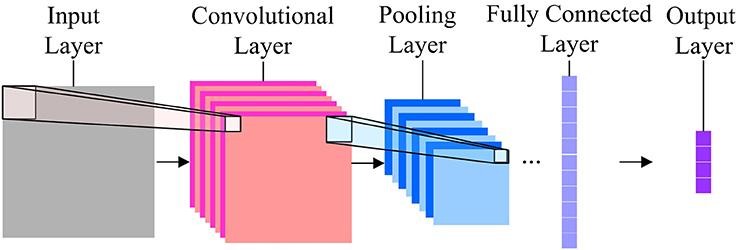
Bildquelle
Wiederkehrende neuronale Netze
Rekurrente neuronale Netze kommen zum Einsatz, wenn Vorhersagen mit sequentiellen Daten erforderlich sind. Sequentielle Daten können eine Folge von Bildern, Wörtern usw. sein. Die RNN haben eine ähnliche Struktur wie die eines Feed-Forward-Netzwerks, außer dass die Schichten auch eine zeitverzögerte Eingabe der vorherigen Instanzvorhersage erhalten. Diese Instanzvorhersage wird in der RNN-Zelle gespeichert, die eine zweite Eingabe für jede Vorhersage ist.
Der Hauptnachteil von RNN ist jedoch das Problem des verschwindenden Gradienten, das es sehr schwierig macht, sich an die Gewichte früherer Schichten zu erinnern.
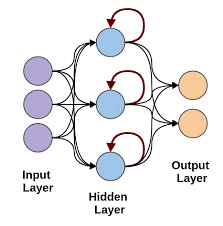
Bildquelle
Lange Kurzzeitgedächtnisnetzwerke
Neuronale LSTM-Netzwerke überwinden das Problem des verschwindenden Gradienten in RNNs, indem sie eine spezielle Speicherzelle hinzufügen, die Informationen über lange Zeiträume speichern kann. LSTM verwendet Gatter, um zu definieren, welche Ausgabe verwendet oder vergessen werden soll. Es verwendet 3 Gates: Input-Gate, Output-Gate und ein Forget-Gate. Das Eingangstor steuert, welche Daten im Speicher gehalten werden sollen. Das Ausgangsgatter steuert die Daten, die an die nächste Schicht gegeben werden, und das Vergessensgatter steuert, wann die nicht benötigten Daten ausgegeben/vergessen werden.
LSTMs werden in verschiedenen Anwendungen verwendet, wie zum Beispiel:
- Gestenerkennung
- Spracherkennung
- Textvorhersage
Bevor du gehst
Neuronale Netzwerke können innerhalb kürzester Zeit sehr komplex werden, wenn Sie dem Netzwerk immer wieder Schichten hinzufügen. Es gibt Zeiten, in denen wir die immense Forschung auf diesem Gebiet nutzen können, indem wir vortrainierte Netzwerke für unseren Gebrauch nutzen.
Dies wird Transferlernen genannt. In diesem Tutorial haben wir die meisten grundlegenden neuronalen Netze und ihre Funktionsweise behandelt. Probieren Sie diese unbedingt mit den Deep-Learning-Frameworks wie Keras und Tensorflow aus.
Wenn Sie mehr über neuronale Netze, maschinelles Lernen und KI erfahren möchten, sehen Sie sich das PG-Diplom in maschinellem Lernen und KI von IIIT-B & upGrad an, das für Berufstätige konzipiert ist und mehr als 450 Stunden strenge Schulungen und mehr als 30 Fallstudien bietet & Aufgaben, IIIT-B-Alumni-Status, mehr als 5 praktische, praktische Abschlussprojekte und Arbeitsunterstützung bei Top-Unternehmen.
Was sind neuronale Netze?
Neuronale Netze sind probabilistische Modelle, die verwendet werden können, um eine nichtlineare Klassifizierung und Regression durchzuführen, was bedeutet, dass eine Abbildung vom Eingaberaum zum Ausgaberaum approximiert wird. Das Interessante an neuronalen Netzen ist, dass sie mit vielen Daten trainiert und zur Modellierung komplexer nichtlinearer Verhaltensweisen verwendet werden können. Sie können mit vielen Beispielen trainiert werden und sie können verwendet werden, um Muster ohne Anleitung zu finden. Daher werden neuronale Netze in vielen Anwendungen verwendet, bei denen es Zufälligkeit und Komplexität gibt.
Welche 3 Hauptkategorien von neuronalen Netzen gibt es?
Ein neuronales Netzwerk ist ein rechnerischer Ansatz zum Lernen, analog zum Gehirn. Es gibt drei Hauptkategorien von neuronalen Netzwerken. Klassifikation, Sequenzlernen und Funktionsnäherung sind die drei Hauptkategorien neuronaler Netze. Es gibt viele Arten von neuronalen Netzwerken wie Perceptron, Hopfield, selbstorganisierende Karten, Boltzmann-Maschinen, Deep-Belief-Netzwerke, Auto-Encoder, Convolutional Neural Networks, Restricted Boltzmann Machines, Continuous Valued Neural Networks, Recurrent Neural Networks und Functional Link Networks.
Welche Grenzen haben neuronale Netze?
Neuronale Netze können Probleme lösen, die eine große Anzahl von Eingaben und eine große Anzahl von Ausgaben haben. Aber es gibt auch Grenzen für neuronale Netze. Neuronale Netze werden meist zur Klassifikation verwendet. Sie schneiden bei der Regression sehr schlecht ab. Und das ist ein ganz wichtiger Punkt: Neuronale Netze brauchen viele Trainingsdaten. Wenn der Datensatz klein ist, können neuronale Netze die zugrunde liegenden Regeln nicht lernen. Eine weitere Einschränkung für neuronale Netze besteht darin, dass sie Black Boxes sind. Sie sind nicht transparent. Die interne Struktur eines neuronalen Netzes ist nicht leicht zu verstehen.