
7 types de réseaux de neurones en intelligence artificielle expliqués
Publié: 2020-12-29Les réseaux de neurones sont un sous-ensemble de techniques d'apprentissage automatique qui apprennent les données et les modèles d'une manière différente en utilisant les neurones et les couches cachées. Les réseaux de neurones sont bien plus puissants en raison de leur structure complexe et peuvent être utilisés dans des applications où les algorithmes traditionnels d'apprentissage automatique ne peuvent tout simplement pas suffire.
À la fin de ce didacticiel, vous aurez les connaissances suivantes :
- Une brève histoire des réseaux de neurones
- Que sont les réseaux de neurones
- Types de réseaux de neurones
- Perceptron
- Réseaux d'alimentation en aval
- Perceptron multicouche
- Réseaux Radiaux
- Réseaux de neurones convolutifs
- Réseaux de neurones récurrents
- Réseaux de mémoire longue à court terme
Table des matières
Une brève histoire des réseaux de neurones
Des chercheurs des années 60 ont recherché et formulé des moyens d'imiter le fonctionnement des neurones humains et le fonctionnement du cerveau. Bien qu'il soit extrêmement complexe à décoder, une structure similaire a été proposée qui pourrait être extrêmement efficace pour apprendre des modèles cachés dans Data.
Pendant la majeure partie du 20e siècle, les réseaux de neurones ont été considérés comme incompétents. Ils étaient complexes et leurs performances étaient médiocres. De plus, ils nécessitaient une grande puissance de calcul qui n'était pas disponible à l'époque. Cependant, lorsque l'équipe de Sir Geoffrey Hinton, également surnommé "Le père de l'apprentissage en profondeur", a publié le document de recherche sur la rétropropagation, les choses ont complètement changé. Les réseaux de neurones pouvaient désormais réaliser ce qui n'avait pas été pensé.
Que sont les réseaux de neurones ?
Les réseaux de neurones utilisent l'architecture des neurones humains qui ont plusieurs entrées, une unité de traitement et des sorties simples/multiples. Des poids sont associés à chaque connexion de neurones. En ajustant ces pondérations, un réseau neuronal arrive à une équation qui est utilisée pour prédire les sorties sur de nouvelles données invisibles. Ce processus se fait par rétropropagation et mise à jour des poids.
Types de réseaux de neurones
Différents types de réseaux de neurones sont utilisés pour différentes données et applications. Les différentes architectures de réseaux de neurones sont spécifiquement conçues pour fonctionner sur ces types particuliers de données ou de domaine. Commençons par les plus basiques et allons vers les plus complexes.

Perceptron
Le Perceptron est la forme la plus basique et la plus ancienne des réseaux de neurones. Il se compose d'un seul neurone qui prend l'entrée et lui applique une fonction d'activation pour produire une sortie binaire. Il ne contient aucune couche cachée et ne peut être utilisé que pour des tâches de classification binaire.
Le neurone effectue le traitement de l'addition des valeurs d'entrée avec leurs poids. La somme résultante est ensuite transmise à la fonction d'activation pour produire une sortie binaire.
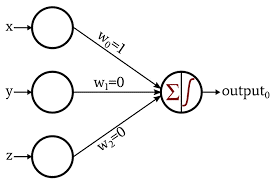
Source des images
Apprenez-en plus à propos de : Apprentissage en profondeur vs réseaux de neurones
Réseau d'alimentation en aval
Les réseaux Feed Forward (FF) sont constitués de plusieurs neurones et de couches cachées qui sont connectées les unes aux autres. Celles-ci sont appelées "feed-forward" car les données circulent uniquement dans le sens aller et il n'y a pas de propagation vers l'arrière. Les couches cachées peuvent ne pas être nécessairement présentes dans le réseau en fonction de l'application.
Plus le nombre de couches plus peut être la personnalisation des poids. Et par conséquent, plus sera la capacité du réseau à apprendre. Les poids ne sont pas mis à jour car il n'y a pas de rétropropagation. La sortie de la multiplication des poids avec les entrées est transmise à la fonction d'activation qui agit comme une valeur de seuil.
Les réseaux FF sont utilisés dans :
- Classification
- Reconnaissance de la parole
- Reconnaissance de visage
- La reconnaissance de formes
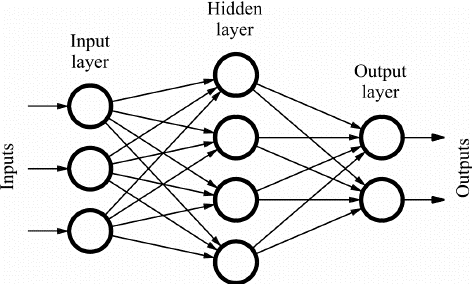
Source des images
Perceptron multicouche
Le principal défaut des réseaux Feed Forward était leur incapacité à apprendre avec la rétropropagation. Les perceptrons multicouches sont les réseaux de neurones qui intègrent plusieurs couches cachées et fonctions d'activation. L'apprentissage se déroule de manière supervisée où les poids sont mis à jour par le biais de Gradient Descent.
Le Perceptron multicouche est bidirectionnel, c'est-à-dire la propagation vers l'avant des entrées et la propagation vers l'arrière des mises à jour de poids. Les fonctions d'activation peuvent être modifiées en fonction du type de cible. Softmax est généralement utilisé pour la classification multi-classes, Sigmoid pour la classification binaire, etc. Ceux-ci sont également appelés réseaux denses car tous les neurones d'une couche sont connectés à tous les neurones de la couche suivante.
Ils sont utilisés dans les applications basées sur le Deep Learning mais sont généralement lents en raison de leur structure complexe.
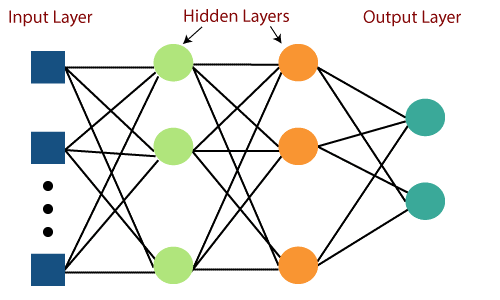
Source des images
Réseaux à base radiale
Les réseaux à base radiale (RBN) utilisent une manière complètement différente de prédire les cibles. Il se compose d'une couche d'entrée, d'une couche avec des neurones RBF et d'une sortie. Les neurones RBF stockent les classes réelles pour chacune des instances de données d'apprentissage. Les RBN sont différents du perceptron multicouche habituel en raison de la fonction radiale utilisée comme fonction d'activation.

Lorsque les nouvelles données sont introduites dans le réseau neuronal, les neurones RBF comparent la distance euclidienne des valeurs de caractéristiques avec les classes réelles stockées dans les neurones. Cela revient à trouver à quel cluster appartient l'instance particulière. La classe où la distance est minimale est attribuée comme classe prédite.
Les RBN sont principalement utilisés dans les applications d'approximation de fonctions telles que les systèmes de restauration de puissance.
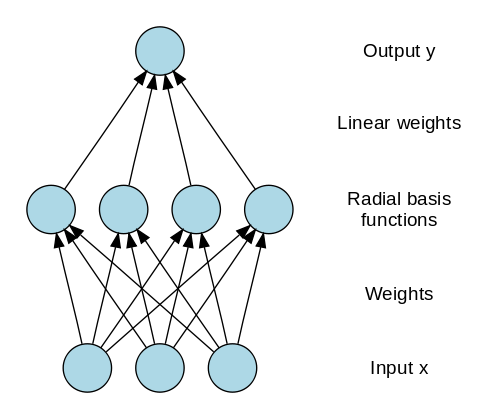
Source des images
A lire aussi : Applications de réseaux de neurones dans le monde réel
Réseaux de neurones convolutifs
En matière de classification d'images, les réseaux de neurones les plus utilisés sont les réseaux de neurones à convolution (CNN). CNN contient plusieurs couches de convolution qui sont responsables de l'extraction des caractéristiques importantes de l'image. Les premières couches sont responsables des détails de bas niveau et les dernières couches sont responsables des fonctionnalités de plus haut niveau.
L'opération de convolution utilise une matrice personnalisée, également appelée filtres, pour convoluer sur l'image d'entrée et produire des cartes. Ces filtres sont initialisés aléatoirement puis mis à jour par rétropropagation. Un exemple d'un tel filtre est le Canny Edge Detector, qui est utilisé pour trouver les bords de n'importe quelle image.
Après la couche de convolution, il y a une couche de regroupement qui est responsable de l'agrégation des cartes produites à partir de la couche de convolution. Il peut s'agir de Max Pooling, Min Pooling, etc. Pour la régularisation, les CNN incluent également une option permettant d'ajouter des couches de suppression qui suppriment ou rendent certains neurones inactifs afin de réduire le surajustement et d'accélérer la convergence.
Les CNN utilisent ReLU (unité linéaire rectifiée) comme fonctions d'activation dans les couches cachées. En tant que dernière couche, les CNN ont une couche dense entièrement connectée et la fonction d'activation principalement en tant que Softmax pour la classification, et principalement ReLU pour la régression.
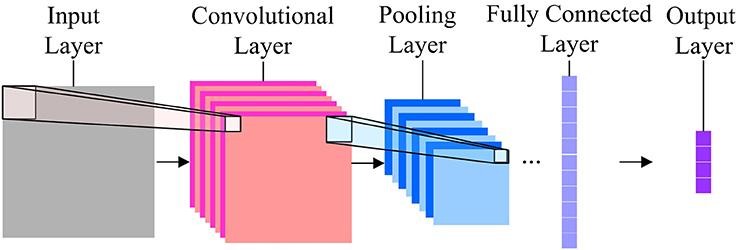
Source des images
Réseaux de neurones récurrents
Les réseaux de neurones récurrents entrent en scène lorsqu'il y a un besoin de prédictions utilisant des données séquentielles. Les données séquentielles peuvent être une séquence d'images, de mots, etc. Le RNN a une structure similaire à celle d'un réseau Feed-Forward, sauf que les couches reçoivent également une entrée temporisée de la prédiction d'instance précédente. Cette prédiction d'instance est stockée dans la cellule RNN qui est une deuxième entrée pour chaque prédiction.
Cependant, le principal inconvénient de RNN est le problème du gradient de disparition qui rend très difficile la mémorisation des poids des couches précédentes.
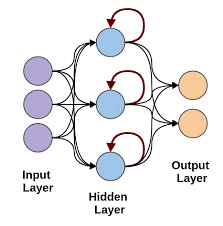
Source des images
Réseaux de mémoire longue à court terme
Les réseaux de neurones LSTM surmontent le problème du gradient de disparition dans les RNN en ajoutant une cellule de mémoire spéciale qui peut stocker des informations pendant de longues périodes. LSTM utilise des portes pour définir quelle sortie doit être utilisée ou oubliée. Il utilise 3 portes : une porte d'entrée, une porte de sortie et une porte oubliée. La porte d'entrée contrôle ce que toutes les données doivent être conservées en mémoire. La porte de sortie contrôle les données transmises à la couche suivante et la porte d'oubli contrôle quand vider/oublier les données non requises.
Les LSTM sont utilisés dans diverses applications telles que :
- Reconnaissance gestuelle
- Reconnaissance de la parole
- Prédiction de texte
Avant que tu partes
Les réseaux de neurones peuvent devenir très complexes en un rien de temps si vous continuez à ajouter des couches dans le réseau. Il y a des moments où nous pouvons tirer parti de l'immense recherche dans ce domaine en utilisant des réseaux pré-formés pour notre usage.
C'est ce qu'on appelle l'apprentissage par transfert. Dans ce didacticiel, nous avons couvert la plupart des réseaux de neurones de base et leur fonctionnement. Assurez-vous de les essayer en utilisant les frameworks Deep Learning comme Keras et Tensorflow.
Si vous souhaitez en savoir plus sur les réseaux de neurones, l'apprentissage automatique et l'IA, consultez le diplôme PG d'IIIT-B & upGrad en apprentissage automatique et en IA, conçu pour les professionnels en activité et offrant plus de 450 heures de formation rigoureuse, plus de 30 études de cas. & affectations, statut IIIT-B Alumni, plus de 5 projets de synthèse pratiques et aide à l'emploi avec les meilleures entreprises.
Que sont les réseaux de neurones ?
Les réseaux de neurones sont des modèles probabilistes qui peuvent être utilisés pour effectuer une classification et une régression non linéaires, c'est-à-dire approximer un mappage de l'espace d'entrée à l'espace de sortie. Ce qui est intéressant avec les réseaux de neurones, c'est qu'ils peuvent être entraînés avec beaucoup de données et qu'ils peuvent être utilisés pour modéliser un comportement non linéaire complexe. Ils peuvent être formés avec de nombreux exemples et ils peuvent être utilisés pour trouver des modèles sans aucune orientation. Ainsi, les réseaux de neurones sont utilisés dans de nombreuses applications où il y a du hasard et de la complexité.
Quelles sont les 3 grandes catégories de réseaux de neurones ?
Un réseau de neurones est une approche informatique de l'apprentissage, analogue au cerveau. Il existe trois grandes catégories de réseaux de neurones. La classification, l'apprentissage de séquences et l'approximation de fonctions sont les trois principales catégories de réseaux de neurones. Il existe de nombreux types de réseaux de neurones comme Perceptron, Hopfield, les cartes auto-organisées, les machines Boltzmann, les réseaux de croyance profonde, les encodeurs automatiques, les réseaux de neurones convolutifs, les machines Boltzmann restreintes, les réseaux de neurones à valeur continue, les réseaux de neurones récurrents et les réseaux de liens fonctionnels.
Quelles sont les limites des réseaux de neurones ?
Les réseaux neuronaux peuvent résoudre des problèmes qui ont un grand nombre d'entrées et un grand nombre de sorties. Mais il y a aussi des limites pour les réseaux de neurones. Les réseaux de neurones sont principalement utilisés pour la classification. Ils fonctionnent très mal pour la régression. Et c'est un point très important : les réseaux de neurones ont besoin de beaucoup de données d'apprentissage. Si l'ensemble de données est petit, les réseaux de neurones ne pourront pas apprendre les règles sous-jacentes. Une autre limitation des réseaux de neurones est qu'ils sont des boîtes noires. Ils ne sont pas transparents. La structure interne d'un réseau de neurones n'est pas facile à comprendre.