
ภาพรวม Apache Storm: สถาปัตยกรรมและเหตุผลคืออะไร
เผยแพร่แล้ว: 2020-03-23ข้อมูลมีอยู่ทุกหนทุกแห่ง และด้วยการแปลงเป็นดิจิทัลที่เพิ่มขึ้น จึงมีความท้าทายใหม่ ๆ เกิดขึ้นทุกวันในส่วนที่เกี่ยวกับการจัดการและการประมวลผลข้อมูล
การเข้าถึงข้อมูลแบบเรียลไทม์อาจดูเหมือนเป็นคุณลักษณะที่ "ดีที่จะมี" แต่สำหรับองค์กรที่มีการลงทุนจำนวนมากในด้านดิจิทัล เกือบจะมีความจำเป็น
สารบัญ
ผู้นำอุตสาหกรรมรายใดที่ใช้ Apache Storm?
บ่อยครั้ง ข้อมูลที่ไม่ได้วิเคราะห์ในช่วงเวลาที่กำหนดอาจกลายเป็นความซ้ำซ้อนสำหรับบริษัทในเร็วๆ นี้ การวิเคราะห์ข้อมูลเพื่อค้นหารูปแบบที่เป็นประโยชน์ต่อบริษัทถือเป็นข้อกำหนด รูปแบบไม่จำเป็นต้องอนุมานเป็นเวลานาน ควรดึงเฉพาะข้อมูลที่เกี่ยวข้องซึ่งบอกทิศทางแบบเรียลไทม์และแนวโน้มปัจจุบันเท่านั้น
เมื่อพิจารณาถึงความต้องการและผลตอบแทนของการวิเคราะห์ข้อมูลตามเวลาจริง องค์กรต่างๆ จึงมีเครื่องมือวิเคราะห์ต่างๆ หนึ่งในเครื่องมือดังกล่าวคือ Apache Storm
Apache Storm คืออะไร?
เผยแพร่โดย Twitter Apache Storm เป็นเครือข่ายโอเพ่นซอร์สแบบกระจายที่ประมวลผลข้อมูลชิ้นใหญ่จากแหล่งต่างๆ เครื่องมือจะวิเคราะห์และอัปเดตผลลัพธ์เป็น UI หรือปลายทางที่กำหนดอื่นๆ โดยไม่ต้องจัดเก็บข้อมูลใดๆ อ่านเพิ่มเติมเกี่ยวกับ Apache Storm
Apache Storm ทำการประมวลผลตามเวลาจริงสำหรับกลุ่มข้อมูลที่ไม่มีขอบเขต คล้ายกับรูปแบบการประมวลผลของ Hadoop สำหรับชุดข้อมูล

สร้างขึ้นโดย Nathan Marz ที่ Black Type ซึ่งเป็นบริษัทวิเคราะห์โซเชียล ซึ่งต่อมาถูกซื้อกิจการและเปิดแหล่งที่มาโดย Twitter เขียนด้วยภาษา Java และ Clojure โดยยังคงเป็นมาตรฐานสำหรับการประมวลผลข้อมูลแบบเรียลไทม์ในอุตสาหกรรม
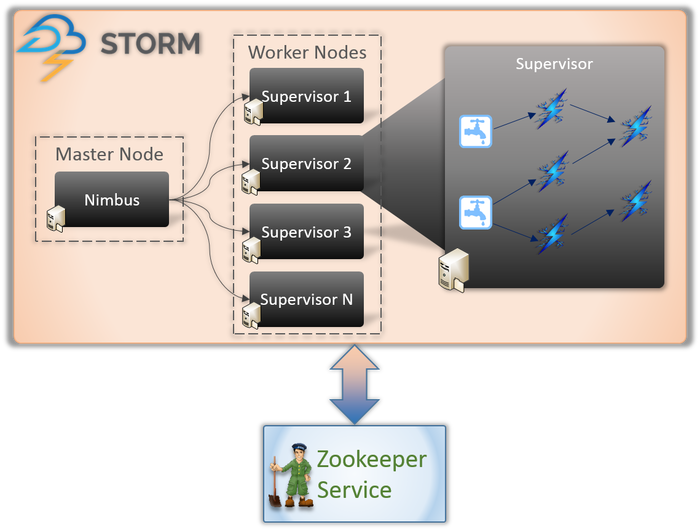
สถาปัตยกรรม Apache Storm
1. Nimbus (มาสเตอร์โหนด)
Nimbus เป็น daemon นั่นคือโปรแกรมที่ทำงานในพื้นหลังโดยไม่มีการควบคุมของผู้ใช้แบบโต้ตอบ มันทำงานสำหรับ Apache Storm ซึ่งคล้ายกับการทำงานของตัวติดตามงานใน Hadoop หน้าที่ของมันต้องการให้กำหนดรหัสและงานให้กับเครื่องและแม้กระทั่งตรวจสอบประสิทธิภาพการทำงาน
2. บริการหัวหน้างาน (โหนดคนงาน)
โหนดผู้ปฏิบัติงานใน Storm เรียกใช้บริการที่เรียกว่า Supervisor โหนดเหล่านี้มีหน้าที่รับงานที่ Nimbus มอบหมายให้กับเครื่องเหล่านี้ นอกเหนือจากการจัดการงานทั้งหมดที่ได้รับมอบหมายจาก Nimbus แล้ว จะเริ่มหรือหยุดกระบวนการตามความต้องการ
แต่ละกระบวนการเหล่านี้โดยหัวหน้างานจะช่วยดำเนินการส่วนหนึ่งของกระบวนการเพื่อทำให้โทโพโลยีสมบูรณ์
3. โทโพโลยี
Storm Topology เป็นเครือข่ายที่ประกอบด้วยรางน้ำและสลักเกลียว ทุกโหนดในระบบมีอยู่เพื่อประมวลผลลอจิกและลิงก์ และแสดงเส้นทางจากตำแหน่งที่ข้อมูลจะผ่านไป
เมื่อใดก็ตามที่ทอพอโลยีถูกส่งไปยัง Storm Nimbus จะปรึกษาหัวหน้างานเกี่ยวกับโหนดของผู้ปฏิบัติงาน
4. สตรีม
สตรีมคือลำดับของทูเพิลที่สร้างและประมวลผลในรูปแบบการกระจายแบบขนาน แต่สิ่งอันดับคืออะไร? เป็นโครงสร้างข้อมูลหลักในสตอร์ม มีการตั้งชื่อรายการของค่าต่างๆ เช่น จำนวนเต็ม ไบต์ โฟลต อาร์เรย์ไบต์ ฯลฯ
5. รางน้ำ
Spout เป็นทางเข้าสำหรับข้อมูลทั้งหมดในทูเพิล มีหน้าที่ติดต่อกับแหล่งข้อมูลจริง รับข้อมูลอย่างต่อเนื่อง แปลงเป็น tuples และส่งไปยังสลักเกลียวเพื่อประมวลผลในที่สุด
6. สลักเกลียว
น็อตเป็นหัวใจสำคัญของการประมวลผลลอจิกทั้งหมดในสตอร์ม ดังนั้นพวกเขาจึงทำการประมวลผลโทโพโลยีทั้งหมด สามารถใช้สลักเกลียวกับฟังก์ชันต่างๆ ได้ รวมถึงการกรอง ฟังก์ชัน การรวม และแม้กระทั่งการเชื่อมต่อกับฐานข้อมูล

เรียนรู้เกี่ยวกับ: สถาปัตยกรรม Apache Spark
ทำไมต้อง Apache Storm?
การทำงานของ Apache Storm ค่อนข้างคล้ายกับ Hadoop ทั้งสองเป็นเครือข่ายแบบกระจายที่ใช้สำหรับการประมวลผล Big Data พวกเขาเสนอความสามารถในการปรับขยายและใช้กันอย่างแพร่หลายเพื่อวัตถุประสงค์ด้านข่าวกรองธุรกิจ ทำไม Storm และทำไมมันแตกต่างกันมาก?
นี่คือเหตุผลหลักในการเลือก Storm:
- Storm ทำการประมวลผลสตรีมตามเวลาจริง ในขณะที่ Hadoop ทำการประมวลผลเป็นชุดเป็นส่วนใหญ่
- โทโพโลยีสตอร์มทำงานจนกว่าผู้ใช้จะปิดตัวลง กระบวนการ Hadoop จะเสร็จสิ้นตามลำดับขั้นในที่สุด
- กระบวนการสตอร์มสามารถเข้าถึงข้อมูลนับพันบนคลัสเตอร์ได้ภายในไม่กี่วินาที ระบบ Hadoop Distributed ใช้กรอบงาน MapReduce เพื่อสร้างกรอบงานจำนวนมากซึ่งจะใช้เวลาเป็นนาทีหรือหลายชั่วโมง
องค์กรที่ใช้ Apache Storm
เมื่อปรับใช้แล้ว Storm ไม่เพียงแต่ใช้งานง่ายเท่านั้น แต่ยังสามารถประมวลผลข้อมูลได้ในไม่กี่วินาที เมื่อพิจารณาถึงประโยชน์มากมายของ Storm หลายองค์กรได้นำไปใช้
1. ทวิตเตอร์
Apache Storm เพิ่มพลังให้กับฟังก์ชันต่างๆ ที่ Twitter Storm ทำงานได้ดีกับโครงสร้างพื้นฐานที่เหลือของ Twitter ซึ่งมีระบบฐานข้อมูล เช่น Cassandra, Memcached, Mesos, โครงสร้างพื้นฐานการส่งข้อความ, ระบบตรวจสอบและแจ้งเตือน
2. อินโฟชิมป์ส
Infochimps ใช้ Storm เป็นแหล่งข้อมูลสำหรับบริการข้อมูลบนคลาวด์ – Data Delivery Services สตอร์มว่าจ้างสตอร์มในการจัดหาการรวบรวมข้อมูล การขนส่ง และการประมวลผลในสตรีมที่ซับซ้อนของบริการคลาวด์
3. Spotify
เป็นผู้นำในแพลตฟอร์มสำหรับการสตรีมเพลงอย่างไม่ต้องสงสัย ด้วยผู้ใช้ 50 ล้านคนทั่วโลกและสมาชิก 10 ล้านคน มีเนื้อหาแบบเรียลไทม์มากมาย เช่น การแนะนำเพลง การวิเคราะห์ การสร้างสรรค์โฆษณา ฯลฯ Apache Storm ช่วย Spotify ในการมอบคุณสมบัติเหล่านี้อย่างแม่นยำ
นอกจากนี้ยังช่วยให้บริษัทสามารถส่งมอบระบบการแจกจ่ายที่ทนทานต่อข้อผิดพลาดที่มีเวลาแฝงต่ำได้อย่างง่ายดาย
4. จรวดเชื้อเพลิง
RocketFuel เป็นบริษัทที่ควบคุมพลังของปัญญาประดิษฐ์เพื่อขยาย ROI ทางการตลาดในสื่อดิจิทัล พวกเขาต้องการสร้างแพลตฟอร์มบน Storm ที่สามารถติดตามการแสดงผล การคลิก คำขอราคาเสนอ ฯลฯ ได้แบบเรียลไทม์ แพลตฟอร์มนี้ควรจะทำงานโดยการโคลนเวิร์กโฟลว์ที่สำคัญของไปป์ไลน์ ETL ที่ใช้ Hadoop
5. Flipboard
Flipboard เป็นร้านค้าครบวงจรสำหรับการเรียกดูและบันทึกข่าวทั้งหมดที่คุณสนใจ ที่ Flipboard Apache Storm ถูกรวมเข้ากับระบบต่างๆ เช่น Hadoop, ElasticSearch, HBase และ HDFS เพื่อสร้างแพลตฟอร์มที่ขยายได้อย่างมาก
ที่นี่ บริการต่างๆ เช่น การค้นหาเนื้อหา การวิเคราะห์ตามเวลาจริง ฟีดนิตยสารที่กำหนดเอง ฯลฯ ทั้งหมดนี้ได้รับความช่วยเหลือจาก Apache Storm
6. Wego
Wego เป็นโปรแกรมค้นหาข้อมูลการเดินทางที่มีต้นกำเนิดในสิงคโปร์ ที่นี่ ข้อมูลมาจากทั่วทุกมุมโลก ในช่วงเวลาที่แตกต่างกัน ด้วยความช่วยเหลือของ Storm ทำให้ Wego สามารถค้นหาข้อมูลแบบเรียลไทม์ แก้ไขปัญหาที่มีอยู่ร่วมกัน และให้ผลลัพธ์ที่ดีที่สุดแก่ผู้ใช้ปลายทาง
อ่านเพิ่มเติม : บทบาทของ Apache จุดประกายใน Big Data

บทสรุป
ก่อนเขียน Storm ข้อมูลแบบเรียลไทม์จะได้รับการประมวลผลโดยใช้คิวและเธรดของผู้ปฏิบัติงาน บางคิวจะเขียนข้อมูลอย่างต่อเนื่อง และบางคิวจะอ่านและประมวลผลข้อมูลอย่างต่อเนื่อง เฟรมเวิร์กนี้ไม่เพียงแต่เปราะบางมาก แต่ยังต้องใช้เวลานานอีกด้วย จะใช้เวลามากในการดูแลข้อมูลสูญหาย ดูแลรักษากรอบงานทั้งหมด จัดลำดับ/ดีซีเรียลไลซ์ข้อความแทนที่จะทำงานจริง
Apache Storm เป็นวิธีที่ชาญฉลาดในการส่งข้อมูลเป็น Spout และ Bolt และการประมวลผลที่เหลือเป็นโทโพโลยี
Apache Storm เป็นเฟรมเวิร์กการคำนวณการประมวลผลแบบโอเพนซอร์สที่แพร่หลายสำหรับการวิเคราะห์ข้อมูลแบบเรียลไทม์ หลายองค์กรใช้งานอยู่แล้ว อันที่จริงแล้ว ซอฟต์แวร์บางตัวกำลังพัฒนาซอฟต์แวร์ที่ดีขึ้นและมีประโยชน์ด้วย
หากคุณสนใจที่จะทราบข้อมูลเพิ่มเติมเกี่ยวกับ Big Data โปรดดูที่ PG Diploma in Software Development Specialization in Big Data program ซึ่งออกแบบมาสำหรับมืออาชีพที่ทำงานและมีกรณีศึกษาและโครงการมากกว่า 7 กรณี ครอบคลุมภาษาและเครื่องมือในการเขียนโปรแกรม 14 รายการ เวิร์กช็อป ความช่วยเหลือด้านการเรียนรู้และจัดหางานอย่างเข้มงวดมากกว่า 400 ชั่วโมงกับบริษัทชั้นนำ
เรียนรู้ หลักสูตรการพัฒนาซอฟต์แวร์ ออนไลน์จากมหาวิทยาลัยชั้นนำของโลก รับโปรแกรม PG สำหรับผู้บริหาร โปรแกรมประกาศนียบัตรขั้นสูง หรือโปรแกรมปริญญาโท เพื่อติดตามอาชีพของคุณอย่างรวดเร็ว