
Überblick über Apache Storm: Was ist, Architektur und Gründe für die Verwendung
Veröffentlicht: 2020-03-23Daten sind allgegenwärtig und mit zunehmender Digitalisierung ergeben sich täglich neue Herausforderungen an die Verwaltung und Verarbeitung von Daten.
Der Zugriff auf Echtzeitdaten mag nur wie eine „nice-to-have“-Funktion erscheinen, aber für ein Unternehmen mit erheblichen Investitionen in den digitalen Bereich ist dies fast eine Notwendigkeit.
Inhaltsverzeichnis
Welche Branchenführer verwenden Apache Storm?
Daten, die zu einem bestimmten Zeitpunkt nicht analysiert werden, werden für Unternehmen oft bald überflüssig. Die Analyse von Daten, um Muster zu finden, die für das Unternehmen von Vorteil sein können, ist eine Anforderung. Muster müssen nicht über lange Zeit abgeleitet werden; nur die relevanten Daten, die aktuelle Trends in Echtzeit vorschreiben, sollten extrahiert werden.
Unter Berücksichtigung der Anforderungen und Erträge der Analyse von Echtzeitdaten haben Unternehmen verschiedene Analysetools entwickelt. Ein solches Tool ist Apache Storm.
Was ist Apache Storm?
Apache Storm wurde von Twitter veröffentlicht und ist ein verteiltes Open-Source-Netzwerk, das große Datenmengen aus verschiedenen Quellen verarbeitet. Das Tool analysiert es und aktualisiert die Ergebnisse auf einer Benutzeroberfläche oder einem anderen festgelegten Ziel, ohne Daten zu speichern. Lesen Sie mehr über Apache Storm.
Apache Storm führt eine Echtzeitverarbeitung für unbegrenzte Datenblöcke durch, ähnlich dem Muster der Hadoop-Verarbeitung für Datenstapel.

Ursprünglich von Nathan Marz bei Black Type, einem Unternehmen für soziale Analysen, erstellt, wurde es später von Twitter übernommen und als Open Source bereitgestellt. Geschrieben in Java und Clojure, ist es weiterhin der Standard für die Echtzeit-Datenverarbeitung in der Industrie.
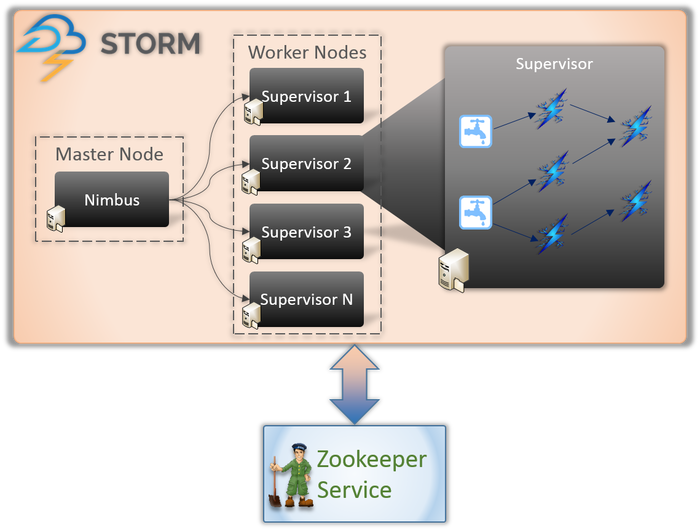
Apache Storm-Architektur
1. Nimbus (Masterknoten)
Nimbus ist ein Daemon, dh ein Programm, das ohne die Kontrolle eines interaktiven Benutzers im Hintergrund läuft. Es läuft für Apache Storm, ähnlich wie der Job-Tracker in Hadoop. Seine Funktion erfordert es, Maschinen Codes und Aufgaben zuzuweisen und sogar ihre Leistung zu überwachen.
2. Supervisor-Dienst (Worker-Knoten)
Die Workerknoten in Storm führen einen Dienst namens Supervisor aus. Diese Knoten sind dafür verantwortlich, die von Nimbus diesen Maschinen zugewiesene Arbeit zu empfangen. Neben der Erledigung aller von Nimbus zugewiesenen Arbeiten startet oder stoppt es den Prozess je nach Bedarf.
Jeder dieser Prozesse durch Supervisoren hilft bei der Ausführung eines Teils des Prozesses, um die Topologie zu vervollständigen.
3. Topologie
Storm Topology ist ein Netzwerk, das aus Spouts und Bolts besteht. Jeder Knoten im System ist vorhanden, um Logiken und Verknüpfungen zu verarbeiten und die Pfade zu demonstrieren, von denen aus die Daten weitergeleitet werden.
Immer wenn eine Topologie an den Storm übermittelt wird, konsultiert Nimbus die Supervisoren bezüglich Worker-Knoten.
4. Streamen
Streams sind eine Folge von Tupeln, die parallel verteilt erstellt und verarbeitet werden. Aber was sind Tupel? Sie sind die Hauptdatenstrukturen in Storm. Sie sind benannte Listen mit unterschiedlichen Werten wie Ganzzahlen, Bytes, Floots, Byte-Arrays usw.
5. Auslauf
Ein Spout ist ein Eingang für alle Daten in Tupeln. Es ist dafür verantwortlich, mit der eigentlichen Datenquelle in Kontakt zu treten, die Daten kontinuierlich zu empfangen, sie in Tupel umzuwandeln und sie schließlich zur Verarbeitung an Bolts zu senden.
6. Schrauben
Bolts sind das Herzstück der gesamten Logikverarbeitung in Storm. Daher führen sie die gesamte Verarbeitung der Topologie durch. Bolts können für eine Vielzahl von Funktionen verwendet werden, einschließlich Filtern, Funktionen, Aggregationen und sogar zum Herstellen einer Verbindung zu Datenbanken.

Erfahren Sie mehr über: Apache Spark-Architektur
Warum Apache Storm?
Die Funktionsweise von Apache Storm ist der von Hadoop sehr ähnlich. Beides sind verteilte Netzwerke, die zur Verarbeitung von Big Data verwendet werden. Sie bieten Skalierbarkeit und werden häufig für Business-Intelligence-Zwecke verwendet. Also, warum Storm und warum ist es so anders?
Hier sind die Hauptgründe für die Wahl von Storm:
- Storm führt Echtzeit-Stream-Verarbeitung durch, während Hadoop hauptsächlich Stapelverarbeitung durchführt.
- Die Storm-Topologie wird ausgeführt, bis sie vom Benutzer heruntergefahren wird. Hadoop-Prozesse werden schließlich in sequentieller Reihenfolge abgeschlossen.
- Storm-Prozesse können innerhalb von Sekunden auf Tausende von Daten in einem Cluster zugreifen. Das verteilte Hadoop-System verwendet das MapReduce-Framework, um eine große Menge an Frameworks zu erstellen, die Minuten oder Stunden dauern.
Organisationen, die Apache Storm verwenden
Einmal bereitgestellt, ist Storm nicht nur einfach zu bedienen, sondern auch in der Lage, Daten in Sekundenschnelle zu verarbeiten. In Anbetracht der zahlreichen Vorteile von Storm haben viele Organisationen es eingesetzt.
1. Twittern
Apache Storm unterstützt eine Reihe von Funktionen bei Twitter. Storm lässt sich gut in die übrige Infrastruktur von Twitter integrieren, die über Datenbanksysteme wie Cassandra, Memcached, Mesos, die Messaging-Infrastruktur, Überwachungs- und Warnsysteme verfügt.
2. Infochimps
Infochimps verwendet Storm als Quelle für einen seiner Cloud-Datendienste – Data Delivery Services. Es verwendet Storm, um eine linear erweiterbare Datenerfassung, -übertragung und komplizierte In-Stream-Verarbeitung von Cloud-Diensten bereitzustellen.
3. Spotify
Es ist zweifellos der führende Anbieter von Plattformen für das Streamen von Musik. Mit 50 Millionen Benutzern auf der ganzen Welt und 10 Millionen Abonnenten bietet es eine riesige Auswahl an Echtzeit-Inhalten wie Musikempfehlungen, Analysen, Anzeigenerstellung usw. Apache Storm unterstützt Spotify bei der genauen Bereitstellung dieser Funktionen.
Es hat es dem Unternehmen auch ermöglicht, problemlos fehlertolerante Verteilungssysteme mit geringer Latenz bereitzustellen.
4. Raketentreibstoff
RocketFuel ist ein Unternehmen, das die Kraft der künstlichen Intelligenz nutzt, um den Marketing-ROI in digitalen Medien zu steigern. Sie möchten eine Plattform auf Storm aufbauen, die Impressionen, Klicks, Gebotsanfragen usw. in Echtzeit verfolgen kann. Diese Plattform soll funktionieren, indem kritische Workflows der Hadoop-basierten ETL-Pipeline geklont werden.
5. Flipboard
Flipboard ist ein One-Stop-Shop zum Durchsuchen und Speichern aller Nachrichten, die Sie interessieren. Bei Flipboard ist Apache Storm in Systeme wie Hadoop, ElasticSearch, HBase und HDFS integriert, um extrem erweiterbare Plattformen zu schaffen.
Hier werden Dienste wie Inhaltssuche, Echtzeitanalysen, benutzerdefinierter Magazin-Feed usw. mit Hilfe von Apache Storm bereitgestellt.
6. Weg
Wego ist eine Reise-Metasuchmaschine, die ihren Ursprung in Singapur hat. Hier kommen Daten aus der ganzen Welt zu unterschiedlichen Zeitpunkten. Mithilfe von Storm ist Wego in der Lage, nach Echtzeitdaten zu suchen, gleichzeitig bestehende Probleme zu lösen und dem Endbenutzer die besten Ergebnisse zu liefern.
Lesen Sie auch: Rolle von Apache Spark in Big Data.

Fazit
Bevor Storm geschrieben wurde, wurden Echtzeitdaten mithilfe von Warteschlangen und Worker-Thread-Ansätzen verarbeitet. Einige Warteschlangen schreiben kontinuierlich Daten, andere lesen und verarbeiten sie ständig. Dieses Gerüst war nicht nur extrem fragil, sondern auch zeitintensiv. Es würde viel Zeit darauf verwendet, sich um Datenverlust zu kümmern, das gesamte Framework zu warten, Nachrichten zu serialisieren/deserialisieren, anstatt die eigentliche Arbeit auszuführen.
Apache Storm ist eine clevere Möglichkeit, die Daten einfach als Spout und Bolt und den Rest der Verarbeitung als Topology zu übermitteln.
Apache Storm ist ein weit verbreitetes Open-Source- und Stream-Verarbeitungs-Berechnungsframework für die Echtzeitanalyse von Daten. Viele Organisationen nutzen es bereits; Tatsächlich entwickeln einige damit bessere und hilfreichere Software.
Wenn Sie mehr über Big Data erfahren möchten, schauen Sie sich unser PG Diploma in Software Development Specialization in Big Data-Programm an, das für Berufstätige konzipiert ist und mehr als 7 Fallstudien und Projekte bietet, 14 Programmiersprachen und Tools abdeckt und praktische praktische Übungen enthält Workshops, mehr als 400 Stunden gründliches Lernen und Unterstützung bei der Stellenvermittlung bei Top-Unternehmen.
Lernen Sie Softwareentwicklungskurse online von den besten Universitäten der Welt. Verdienen Sie Executive PG-Programme, Advanced Certificate-Programme oder Master-Programme, um Ihre Karriere zu beschleunigen.