
Présentation d'Apache Storm : qu'est-ce que c'est, architecture et raisons de l'utiliser
Publié: 2020-03-23Les données sont omniprésentes et, avec la numérisation croissante, de nouveaux défis se présentent chaque jour en ce qui concerne la gestion et le traitement des données.
Avoir accès à des données en temps réel peut sembler être une fonctionnalité "agréable à avoir", mais pour une organisation ayant des investissements importants dans la sphère numérique, c'est presque une nécessité.
Table des matières
Quels leaders de l'industrie utilisent Apache Storm ?
Souvent, les données qui ne sont pas analysées à un moment donné peuvent rapidement devenir redondantes pour les entreprises. L'analyse des données pour trouver des modèles qui peuvent être avantageux pour l'entreprise est une exigence. Les modèles n'ont pas besoin d'être déduits sur une longue période; seules les données pertinentes qui dictent les tendances actuelles en temps réel doivent être extraites.
Compte tenu des besoins et des rendements de l'analyse des données en temps réel, les organisations ont proposé divers outils d'analyse. Un de ces outils est Apache Storm.
Qu'est-ce qu'Apache Storm ?
Publié par Twitter, Apache Storm est un réseau open source distribué qui traite de gros volumes de données provenant de diverses sources. L'outil l'analyse et met à jour les résultats vers une interface utilisateur ou toute autre destination désignée, sans stocker aucune donnée. En savoir plus sur Apache Storm.
Apache Storm effectue un traitement en temps réel pour des blocs de données illimités, similaire au modèle de traitement de Hadoop pour les lots de données.

Créé à l'origine par Nathan Marz chez Black Type, une société d'analyse sociale, il a ensuite été acquis et open source par Twitter. Écrit en Java et Clojure, il continue d'être la norme pour le traitement de données en temps réel dans l'industrie.
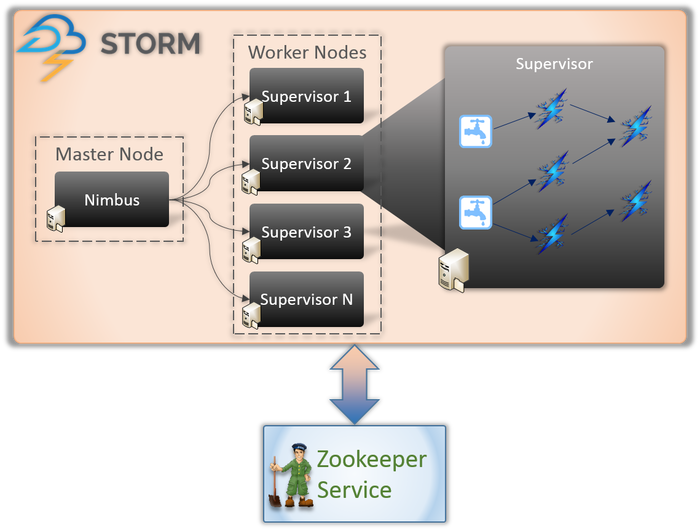
Architecture Apache Storm
1. Nimbus (nœud maître)
Nimbus est un démon, c'est-à-dire un programme qui s'exécute en arrière-plan sans le contrôle d'un utilisateur interactif. Il fonctionne pour Apache Storm, similaire au fonctionnement de Job tracker dans Hadoop. Sa fonction l'oblige à attribuer des codes et des tâches aux machines et même à surveiller leurs performances.
2. Service de superviseur (nœud de travail)
Les nœuds de travail dans Storm exécutent un service appelé Supervisor. Ces nœuds sont chargés de recevoir le travail assigné par Nimbus à ces machines. En plus de gérer tout le travail assigné par Nimbus, il démarre ou arrête le processus en fonction des besoins.
Chacun de ces processus par les superviseurs aide à exécuter une partie du processus pour compléter la topologie.
3. Topologie
Storm Topology est un réseau composé de becs et de boulons. Chaque nœud du système est présent pour traiter les logiques et les liens, et montrer les chemins d'où les données passeront.
Chaque fois qu'une topologie est soumise au Storm, Nimbus consulte les superviseurs sur les nœuds de travail.
4. Diffusez
Les flux sont une séquence de tuples créés et traités de manière distribuée en parallèle. Mais que sont les tuples ? Ce sont les principales structures de données dans Storm. Ce sont des listes nommées de valeurs variées comme des entiers, des octets, des flottants, des tableaux d'octets, etc.
5. Bec
Un Spout est une porte d'entrée pour toutes les données dans les tuples. Il est chargé d'entrer en contact avec la source de données réelle, de recevoir les données en continu, de les transformer en tuples et enfin de les envoyer aux boulons pour qu'ils soient traités.
6. Boulons
Les boulons sont au cœur de tout le traitement logique de Storm. Par conséquent, ils effectuent tout le traitement de la topologie. Les boulons peuvent être utilisés pour une variété de fonctions, y compris le filtrage, les fonctions, les agrégations et même la connexion aux bases de données.
En savoir plus sur : Architecture Apache Spark

Pourquoi Apache Storm ?
Le fonctionnement d'Apache Storm est assez similaire à celui d'Hadoop. Les deux sont des réseaux distribués utilisés pour le traitement du Big Data. Ils offrent une évolutivité et sont largement utilisés à des fins de business intelligence. Alors, pourquoi Storm et pourquoi est-ce si différent ?
Voici les principales raisons de choisir Storm :
- Storm effectue un traitement de flux en temps réel, tandis que Hadoop effectue principalement un traitement par lots.
- La topologie Storm s'exécute jusqu'à son arrêt par l'utilisateur. Les processus Hadoop sont finalement terminés dans un ordre séquentiel.
- Les processus Storm peuvent accéder à des milliers de données sur un cluster, en quelques secondes. Le système Hadoop Distributed utilise le framework MapReduce pour produire une grande quantité de frameworks qui prendront des minutes ou des heures.
Organisations qui utilisent Apache Storm
Une fois déployé, Storm est non seulement facile à utiliser, mais il est également capable de traiter les données en quelques secondes. Compte tenu des nombreux avantages de Storm, de nombreuses organisations l'ont utilisé.
1. Gazouillement
Apache Storm alimente une gamme de fonctions sur Twitter. Storm s'intègre bien au reste de l'infrastructure de Twitter, qui dispose de systèmes de base de données tels que Cassandra, Memcached, Mesos, l'infrastructure de messagerie, les systèmes de surveillance et d'alerte.
2. Infochimpanzés
Infochimps utilise Storm comme source pour l'un de ses services de données cloud - Data Delivery Services. Il utilise Storm pour fournir une collecte de données extensible de manière linéaire, un transport et un traitement en continu complexe des services cloud.
3. Spotify
C'est sans aucun doute le leader des plateformes de streaming musical. Avec 50 millions d'utilisateurs dans le monde et 10 millions d'abonnés, il offre une vaste gamme de contenus en temps réel tels que des recommandations musicales, des analyses, des créations d'annonces, etc. Apache Storm aide Spotify à fournir ces fonctionnalités avec précision.
Cela a également permis à l'entreprise de fournir facilement des systèmes de distribution à faible latence et tolérants aux pannes.
4. RocketFuel
RocketFuel est une entreprise qui exploite la puissance de l'intelligence artificielle pour augmenter le retour sur investissement du marketing dans les médias numériques. Ils cherchent à créer une plate-forme sur Storm qui peut suivre les impressions, les clics, les demandes d'enchères, etc. en temps réel. Cette plate-forme est censée fonctionner en clonant les flux de travail critiques du pipeline ETL basé sur Hadoop.
5. Flipboard
Flipboard est un guichet unique pour parcourir et enregistrer toutes les actualités qui vous intéressent. Chez Flipboard, Apache Storm est intégré à des systèmes tels que Hadoop, ElasticSearch, HBase et HDFS pour créer des plates-formes extrêmement extensibles.
Ici, des services tels que la recherche de contenu, l'analyse en temps réel, le flux de magazines personnalisés, etc. sont tous fournis avec l'aide d'Apache Storm.
6. Wego
Wego est un métamoteur de recherche de voyages originaire de Singapour. Ici, les données viennent du monde entier, à des moments différents. Avec l'aide de Storm, Wego est capable de rechercher des données en temps réel, de résoudre tous les problèmes coexistants et de fournir les meilleurs résultats à l'utilisateur final.
A lire aussi : Rôle d'Apache spark dans le Big Data.

Conclusion
Avant l'écriture de Storm, les données en temps réel étaient traitées à l'aide de files d'attente et d'approches de thread de travail. Certaines files d'attente écriront en permanence des données, tandis que d'autres les liront et les traiteront en permanence. Ce cadre était non seulement extrêmement fragile, mais aussi très chronophage. Beaucoup de temps serait consacré à la perte de données, à la maintenance de l'ensemble du cadre, à la sérialisation/désérialisation des messages plutôt qu'à l'exécution du travail proprement dit.
Apache Storm est un moyen intelligent de simplement soumettre les données en tant que Spout et Bolt et le reste du traitement en tant que Topology.
Apache Storm est un cadre de calcul répandu, open source et de traitement de flux pour l'analyse en temps réel des données. De nombreuses organisations l'utilisent déjà ; en fait, certains développent des logiciels meilleurs et utiles avec lui.
Si vous souhaitez en savoir plus sur le Big Data, consultez notre programme PG Diploma in Software Development Specialization in Big Data qui est conçu pour les professionnels en activité et fournit plus de 7 études de cas et projets, couvre 14 langages et outils de programmation, pratique pratique ateliers, plus de 400 heures d'apprentissage rigoureux et d'aide au placement dans les meilleures entreprises.
Apprenez des cours de développement de logiciels en ligne dans les meilleures universités du monde. Gagnez des programmes Executive PG, des programmes de certificat avancés ou des programmes de maîtrise pour accélérer votre carrière.