
Descripción general de Apache Storm: qué es, arquitectura y razones para usar
Publicado: 2020-03-23Los datos son omnipresentes y, con el aumento de la digitalización, surgen nuevos desafíos todos los días con respecto a la gestión y el procesamiento de datos.
Tener acceso a datos en tiempo real puede parecer una característica "agradable de tener", pero para una organización con importantes inversiones en la esfera digital, es casi una necesidad.
Tabla de contenido
¿Qué líderes de la industria utilizan Apache Storm?
A menudo, los datos que no se analizan en un momento dado pronto pueden volverse redundantes para las empresas. El análisis de datos para encontrar patrones que puedan ser ventajosos para la empresa es un requisito. No es necesario deducir patrones durante mucho tiempo; solo se deben extraer los datos relevantes que dictan las tendencias actuales en tiempo real.
Teniendo en cuenta las necesidades y los beneficios de analizar datos en tiempo real, las organizaciones crearon varias herramientas de análisis. Una de esas herramientas es Apache Storm.
¿Qué es Apache Storm?
Lanzado por Twitter, Apache Storm es una red distribuida de código abierto que procesa grandes cantidades de datos de varias fuentes. La herramienta lo analiza y actualiza los resultados a una interfaz de usuario o cualquier otro destino designado, sin almacenar ningún dato. Lea más sobre Apache Storm.
Apache Storm realiza un procesamiento en tiempo real para fragmentos ilimitados de datos, similar al patrón de procesamiento de lotes de datos de Hadoop.

Originalmente creado por Nathan Marz en Black Type, una empresa de análisis social, luego fue adquirido y abierto por Twitter. Escrito en Java y Clojure, continúa siendo el estándar para el procesamiento de datos en tiempo real en la industria.
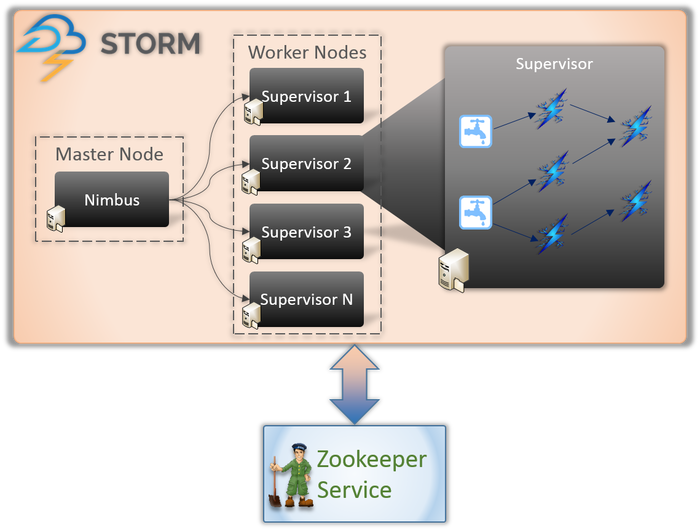
Arquitectura Apache Storm
1. Nimbus (nodo maestro)
Nimbus es un demonio, es decir, un programa que se ejecuta en segundo plano sin el control de un usuario interactivo. Se ejecuta para Apache Storm, similar al funcionamiento del rastreador de trabajos en Hadoop. Su función lo obliga a asignar códigos y tareas a las máquinas e incluso monitorear su desempeño.
2. Servicio de supervisor (nodo trabajador)
Los nodos trabajadores en Storm ejecutan un servicio llamado Supervisor. Estos nodos son los encargados de recibir el trabajo asignado por Nimbus a estas máquinas. Además de manejar todo el trabajo asignado por Nimbus, inicia o detiene el proceso según el requerimiento.
Cada uno de estos procesos de los supervisores ayuda a ejecutar una parte del proceso para completar la topología.
3. Topología
Storm Topology es una red que consta de picos y pernos. Cada nodo en el sistema está presente para procesar lógicas y enlaces, y demostrar las rutas desde donde pasarán los datos.
Cada vez que se envía una topología a Storm, Nimbus consulta a los supervisores sobre los nodos trabajadores.
4. Corriente
Los flujos son una secuencia de tuplas que se crean y procesan de forma distribuida en paralelo. Pero, ¿qué son las tuplas? Son las principales estructuras de datos en Storm. Son listas nombradas de valores variados como enteros, bytes, flotantes, matrices de bytes, etc.
5. Boquilla
Un Spout es una entrada para todos los datos en tuplas. Es responsable de ponerse en contacto con la fuente de datos real, recibir los datos continuamente, transformarlos en tuplas y finalmente enviarlos a los pernos para su procesamiento.
6. Pernos
Los pernos están en el corazón de todo el procesamiento lógico en Storm. Por lo tanto, realizan todo el procesamiento de la topología. Los pernos se pueden usar para una variedad de funciones, incluido el filtrado, las funciones, las agregaciones e incluso la conexión a bases de datos.

Más información sobre: Arquitectura de Apache Spark
¿Por qué Apache Storm?
El funcionamiento de Apache Storm es bastante similar al de Hadoop. Ambas son redes distribuidas utilizadas para el procesamiento de Big Data. Ofrecen escalabilidad y se utilizan ampliamente con fines de inteligencia empresarial. Entonces, ¿por qué Storm y por qué es tan diferente?
Estas son las razones clave para elegir Storm:
- Storm realiza el procesamiento de secuencias en tiempo real, mientras que Hadoop realiza principalmente el procesamiento por lotes.
- La topología Storm se ejecuta hasta que el usuario la apaga. Los procesos de Hadoop se completan eventualmente en orden secuencial.
- Los procesos Storm pueden acceder a miles de datos en un clúster, en segundos. El sistema distribuido de Hadoop utiliza el marco MapReduce para producir una gran cantidad de marcos que llevarán minutos u horas.
Organizaciones que usan Apache Storm
Una vez implementado, Storm no solo es fácil de operar, sino que también puede procesar datos en segundos. Teniendo en cuenta los amplios beneficios de Storm, muchas organizaciones lo han puesto en uso.
1. Gorjeo
Apache Storm impulsa una variedad de funciones en Twitter. Storm se integra bien con el resto de la infraestructura de Twitter, que tiene sistemas de bases de datos como Cassandra, Memcached, Mesos, la infraestructura de mensajería, los sistemas de monitoreo y alerta.
2. Infochimpancés
Infochimps utiliza Storm como fuente para uno de sus servicios de datos en la nube: Servicios de entrega de datos. Emplea Storm para proporcionar una recopilación de datos, transporte y procesamiento in-stream complicado de servicios en la nube linealmente ampliable.
3. Spotify
Es sin duda el líder en plataformas de música en streaming. Con 50 millones de usuarios en todo el mundo y 10 millones de suscriptores, ofrece una gran variedad de contenido en tiempo real, como recomendaciones de música, análisis, creación de anuncios, etc. Apache Storm ayuda a Spotify a ofrecer estas funciones con precisión.
También ha permitido a la empresa ofrecer fácilmente sistemas de distribución tolerantes a fallas y de baja latencia.
4. Combustible de cohetes
RocketFuel es una empresa que aprovecha el poder de la Inteligencia Artificial para aumentar el ROI de marketing en medios digitales. Están buscando construir una plataforma en Storm que pueda rastrear impresiones, clics, solicitudes de ofertas, etc. en tiempo real. Se supone que esta plataforma funciona mediante la clonación de flujos de trabajo críticos de la canalización ETL basada en Hadoop.
5. Flipboard
Flipboard es una ventanilla única para buscar y guardar todas las noticias que le interesan. En Flipboard, Apache Storm está integrado con sistemas como Hadoop, ElasticSearch, HBase y HDFS para crear plataformas extremadamente ampliables.
Aquí, los servicios como búsqueda de contenido, análisis en tiempo real, alimentación de revistas personalizadas, etc., se proporcionan con la ayuda de Apache Storm.
6. Vamos
Wego es un metabuscador de viajes que se originó en Singapur. Aquí, los datos provienen de todo el mundo, en diferentes momentos. Con la ayuda de Storm, Wego puede buscar datos en tiempo real, resolver cualquier problema coexistente y brindar los mejores resultados al usuario final.
Lea también: Rol de Apache Spark en Big Data.

Conclusión
Antes de que se escribiera Storm, los datos en tiempo real se procesaban mediante colas y enfoques de subprocesos de trabajo. Algunas colas escribirán datos continuamente y otras los leerán y procesarán constantemente. Este marco no solo era extremadamente frágil sino que también requería mucho tiempo. Se gastaría mucho tiempo ocupándose de la pérdida de datos, manteniendo todo el marco, serializando/deserializando mensajes en lugar de realizar el trabajo real.
Apache Storm es una forma inteligente de enviar los datos como Spout y Bolt y el resto del procesamiento como Topología.
Apache Storm es un marco de computación predominante, de código abierto y de procesamiento de flujo para el análisis de datos en tiempo real. Muchas organizaciones ya lo están utilizando; de hecho, algunos están desarrollando software mejor y más útil con él.
Si está interesado en saber más sobre Big Data, consulte nuestro programa PG Diploma in Software Development Specialization in Big Data, que está diseñado para profesionales que trabajan y proporciona más de 7 estudios de casos y proyectos, cubre 14 lenguajes y herramientas de programación, prácticas talleres, más de 400 horas de aprendizaje riguroso y asistencia para la colocación laboral con las mejores empresas.
Aprenda cursos de desarrollo de software en línea de las mejores universidades del mundo. Obtenga Programas PG Ejecutivos, Programas de Certificado Avanzado o Programas de Maestría para acelerar su carrera.