
Apache Stormの概要:アーキテクチャと使用理由
公開: 2020-03-23データは至る所に存在し、デジタル化が進むにつれて、データの管理と処理に関して毎日新たな課題が発生しています。
リアルタイムデータにアクセスできることは、「便利な」機能のように思えるかもしれませんが、デジタル分野に多額の投資を行っている組織にとっては、ほとんど必要です。
目次
どの業界リーダーがApacheStormを使用していますか?
多くの場合、特定の時間に分析されていないデータは、企業にとってすぐに冗長になる可能性があります。 データを分析して、会社にとって有利なパターンを見つけることが必要です。 パターンは、長期間にわたって推測する必要はありません。 リアルタイムの現在の傾向を示す関連データのみを抽出する必要があります。
リアルタイムデータの分析のニーズとリターンを考慮して、組織はさまざまな分析ツールを考案しました。 そのようなツールの1つがApacheStormです。
Apache Stormとは何ですか?
TwitterによってリリースされたApacheStormは、さまざまなソースからの大量のデータを処理する分散型のオープンソースネットワークです。 ツールはそれを分析し、データを保存せずに結果をUIまたはその他の指定された宛先に更新します。 ApacheStormについてもっと読む。
Apache Stormは、データバッチに対するHadoopの処理のパターンと同様に、データの無制限のチャンクに対してリアルタイム処理を実行します。

もともとはソーシャル分析会社であるBlackTypeのNathanMarzによって作成されましたが、後にTwitterによって買収され、オープンソースになりました。 JavaとClojureで記述されており、業界のリアルタイムデータ処理の標準であり続けています。
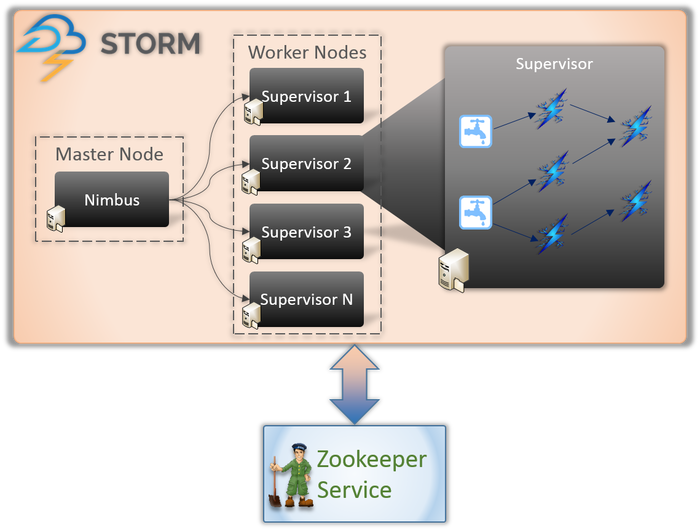
ApacheStormアーキテクチャ
1.ニンバス(マスターノード)
Nimbusはデーモン、つまりインタラクティブユーザーの制御なしにバックグラウンドで実行されるプログラムです。 これは、Hadoopのジョブトラッカーの動作と同様に、ApacheStormで実行されます。 その機能では、コードとタスクをマシンに割り当て、さらにはそれらのパフォーマンスを監視する必要があります。
2.スーパーバイザーサービス(ワーカーノード)
Stormのワーカーノードは、Supervisorと呼ばれるサービスを実行します。 これらのノードは、Nimbusによってこれらのマシンに割り当てられた作業を受け取る責任があります。 Nimbusによって割り当てられたすべての作業を処理する以外に、要件に応じてプロセスを開始または停止します。
スーパーバイザーによるこれらの各プロセスは、トポロジーを完了するためのプロセスの一部を実行するのに役立ちます。
3.トポロジ
ストームトポロジは、注ぎ口とボルトで構成されるネットワークです。 システム内のすべてのノードは、ロジックとリンクを処理し、データが渡される場所からのパスを示すために存在します。
トポロジがStormに送信されるたびに、Nimbusはワーカーノードについてスーパーバイザーに相談します。
4.ストリーム
ストリームは、並列分散方式で作成および処理される一連のタプルです。 しかし、タプルとは何ですか? これらはStormの主要なデータ構造です。 それらは、整数、バイト、フルート、バイト配列などのさまざまな値の名前付きリストです。
5.注ぎ口
スパウトは、タプル内のすべてのデータの入り口です。 実際のデータソースと連絡を取り、データを継続的に受信し、タプルに変換し、最後にボルトに送信して処理する責任があります。

6.ボルト
ボルトは、Stormのすべてのロジック処理の中心です。 したがって、トポロジのすべての処理を実行します。 ボルトは、フィルタリング、関数、集計、さらにはデータベースへの接続など、さまざまな関数に使用できます。
学ぶ: ApacheSparkアーキテクチャ
なぜApacheStormなのか?
Apache Stormの動作は、Hadoopの動作と非常によく似ています。 どちらもビッグデータの処理に使用される分散ネットワークです。 これらはスケーラビリティを提供し、ビジネスインテリジェンスの目的で広く使用されています。 それで、なぜストームとそれはなぜそんなに違うのですか?
Stormを選択する主な理由は次のとおりです。
- Stormはリアルタイムのストリーム処理を行いますが、Hadoopは主にバッチ処理を行います。
- ストームトポロジは、ユーザーによってシャットダウンされるまで実行されます。 Hadoopプロセスは、最終的に順番に完了します。
- ストームプロセスは、数秒以内にクラスター上の何千ものデータにアクセスできます。 Hadoop分散システムは、MapReduceフレームワークを使用して、数分または数時間かかる膨大な量のフレームワークを生成します。
ApacheStormを使用する組織
Stormを導入すると、操作が簡単になるだけでなく、データを数秒で処理できるようになります。 Stormの十分な利点を考慮して、多くの組織がStormを使用しています。
1.ツイッター
Apache Stormは、Twitterのさまざまな機能を強化します。 Stormは、Cassandra、Memcached、Mesos、メッセージングインフラストラクチャ、監視、アラートシステムなどのデータベースシステムを備えたTwitterの他のインフラストラクチャとうまく統合されます。
2.インフォチンプ
Infochimpsは、クラウドデータサービスの1つであるデータ配信サービスのソースとしてStormを使用しています。 Stormを使用して、線形に拡張可能なデータ収集、転送、およびクラウドサービスの複雑なインストリーム処理を提供します。
3.Spotify
それは間違いなく音楽をストリーミングするためのプラットフォームのリーダーです。 世界中に5,000万人のユーザーと1,000万人の加入者を抱え、音楽のおすすめ、分析、広告の作成など、膨大な数のリアルタイムコンテンツを提供しています。ApacheStormは、Spotifyがこれらの機能を正確に提供するのを支援します。
また、同社は低遅延のフォールトトレラントな配電システムを簡単に提供できるようになりました。
4. RocketFuel
RocketFuelは、人工知能の力を利用して、デジタルメディアのマーケティングROIを拡大する会社です。 彼らは、インプレッション、クリック、入札リクエストなどをリアルタイムで追跡できるプラットフォームをStorm上に構築しようとしています。 このプラットフォームは、HadoopベースのETLパイプラインの重要なワークフローのクローンを作成することで機能するはずです。
5. Flipboard
Flipboardは、興味のあるすべてのニュースを閲覧して保存するためのワンストップショップです。 Flipboardでは、Apache StormをHadoop、ElasticSearch、HBase、HDFSなどのシステムと統合して、非常に拡張可能なプラットフォームを作成します。
ここでは、コンテンツ検索、リアルタイム分析、カスタムマガジンフィードなどのサービスはすべて、ApacheStormの助けを借りて提供されます。
6.ウェゴ
Wegoは、シンガポールで生まれた旅行メタ検索エンジンです。 ここでは、データは世界中からさまざまなタイミングで取得されます。 Stormの助けを借りて、Wegoはリアルタイムのデータを検索し、共存する問題を解決し、エンドユーザーに最良の結果を提供することができます。
また読む:ビッグデータにおけるApacheSparkの役割。

結論
Stormが作成される前は、リアルタイムデータはキューとワーカースレッドアプローチを使用して処理されていました。 一部のキューは継続的にデータを書き込み、他のキューは常にデータを読み取って処理します。 このフレームワークは非常に壊れやすいだけでなく、時間もかかりました。 実際の作業を実行するのではなく、データ損失の処理、フレームワーク全体の保守、メッセージのシリアル化/逆シリアル化に多くの時間が費やされます。
Apache Stormは、データをSpout and Boltとして送信し、残りの処理をトポロジとして送信するための賢い方法です。
Apache Stormは、データをリアルタイムで分析するための、普及しているオープンソースのストリーム処理計算フレームワークです。 多くの組織がすでにそれを使用しています。 実際、それを使ってより良くて役立つソフトウェアを開発している人もいます。
ビッグデータについて詳しく知りたい場合は、ビッグデータプログラムのソフトウェア開発スペシャライゼーションのPGディプロマをチェックしてください。このプログラムは、働く専門家向けに設計されており、7つ以上のケーススタディとプロジェクトを提供し、14のプログラミング言語とツール、実践的なハンズオンをカバーしています。ワークショップ、トップ企業との400時間以上の厳格な学習と就職支援。
世界のトップ大学からオンラインでソフトウェア開発コースを学びましょう。 エグゼクティブPGプログラム、高度な証明書プログラム、または修士プログラムを取得して、キャリアを早急に進めましょう。