
Ikhtisar Apache Storm: Apa itu, Arsitektur & Alasan Menggunakan
Diterbitkan: 2020-03-23Data ada di mana-mana, dan dengan meningkatnya digitalisasi, ada tantangan baru yang muncul setiap hari sehubungan dengan pengelolaan dan pemrosesan data.
Memiliki akses ke data real-time mungkin tampak seperti fitur yang “bagus untuk dimiliki”, tetapi bagi organisasi dengan investasi signifikan di bidang digital, ini hampir merupakan kebutuhan.
Daftar isi
Pemimpin Industri Mana yang Menggunakan Apache Storm?
Seringkali, data yang tidak dianalisis pada waktu tertentu akan segera menjadi mubazir bagi perusahaan. Menganalisis data untuk menemukan pola yang dapat menguntungkan perusahaan adalah suatu keharusan. Pola tidak perlu disimpulkan dalam waktu lama; hanya data relevan yang menentukan waktu nyata, tren saat ini harus diekstraksi.
Mempertimbangkan kebutuhan dan pengembalian menganalisis data waktu nyata, organisasi datang dengan berbagai alat analisis. Salah satu alat tersebut adalah Apache Storm.
Apa itu Apache Storm?
Dirilis oleh Twitter, Apache Storm adalah jaringan sumber terbuka terdistribusi yang memproses sejumlah besar data dari berbagai sumber. Alat ini menganalisisnya dan memperbarui hasilnya ke UI atau tujuan lain yang ditentukan, tanpa menyimpan data apa pun. Baca lebih lanjut tentang Apache Storm.
Apache Storm melakukan pemrosesan waktu nyata untuk potongan data yang tidak terbatas, mirip dengan pola pemrosesan Hadoop untuk kumpulan data.

Awalnya dibuat oleh Nathan Marz di Black Type, sebuah perusahaan analisis sosial, kemudian diakuisisi dan bersumber terbuka oleh Twitter. Ditulis dalam Java dan Clojure, ini terus menjadi standar untuk pemrosesan data real-time di industri.
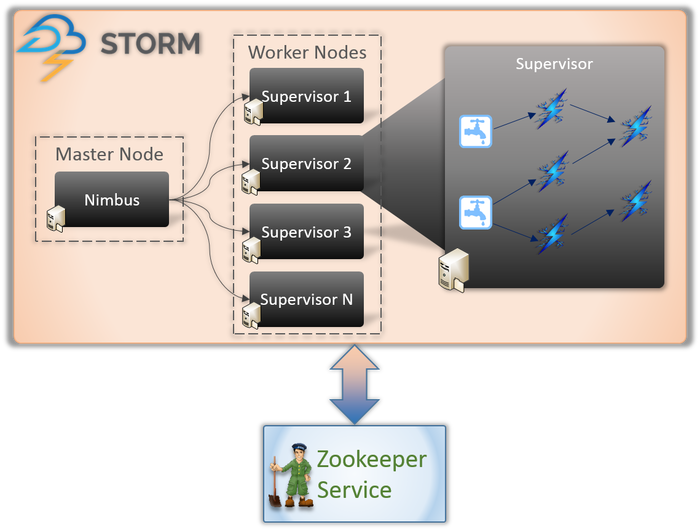
Arsitektur Apache Storm
1. Nimbus (Node Utama)
Nimbus adalah daemon, yaitu program yang berjalan di latar belakang tanpa kontrol dari pengguna interaktif. Ini berjalan untuk Apache Storm, mirip dengan cara kerja Job tracker di Hadoop. Fungsinya mengharuskannya untuk menetapkan kode dan tugas ke mesin dan bahkan memantau kinerjanya.
2. Layanan Supervisor (Node Pekerja)
Node pekerja di Storm menjalankan layanan yang disebut Supervisor. Node ini bertanggung jawab untuk menerima pekerjaan yang diberikan oleh Nimbus ke mesin ini. Selain menangani semua pekerjaan yang diberikan oleh Nimbus, Nimbus memulai atau menghentikan proses sesuai kebutuhan.
Setiap proses ini oleh Supervisor membantu mengeksekusi bagian dari proses untuk menyelesaikan topologi.
3. Topologi
Topologi Storm adalah jaringan yang terdiri dari spouts dan bolts. Setiap node dalam sistem hadir untuk memproses logika dan tautan, dan menunjukkan jalur dari mana data akan lewat.
Setiap kali topologi dikirimkan ke Storm, Nimbus berkonsultasi dengan Supervisor tentang node pekerja.
4. Aliran
Streams adalah urutan tupel yang dibuat dan diproses secara paralel terdistribusi. Tapi apa tupel? Mereka adalah struktur data utama di Storm. Mereka diberi nama daftar nilai yang bervariasi seperti bilangan bulat, byte, floot, array byte, dll.
5. Cerat
Spout adalah pintu masuk untuk semua data dalam tupel. Ini bertanggung jawab untuk berhubungan dengan sumber data yang sebenarnya, menerima data terus menerus, mengubahnya menjadi tupel, dan akhirnya mengirimkannya ke baut untuk diproses.
6. Baut
Baut adalah jantung dari semua pemrosesan logika di Storm. Oleh karena itu, mereka melakukan semua pemrosesan topologi. Baut dapat digunakan untuk berbagai fungsi, termasuk pemfilteran, fungsi, agregasi, dan bahkan menghubungkan ke database.

Pelajari tentang: Arsitektur Apache Spark
Mengapa Apache Badai?
Cara kerja Apache Storm sangat mirip dengan Hadoop. Keduanya merupakan jaringan terdistribusi yang digunakan untuk memproses Big Data. Mereka menawarkan skalabilitas dan banyak digunakan untuk tujuan intelijen bisnis. Jadi, mengapa Storm dan mengapa begitu berbeda?
Berikut adalah alasan utama untuk memilih Storm:
- Storm melakukan pemrosesan aliran waktu nyata, sementara Hadoop sebagian besar melakukan pemrosesan batch.
- Topologi badai berjalan sampai dimatikan oleh pengguna. Proses Hadoop akhirnya selesai secara berurutan.
- Proses badai dapat mengakses ribuan data di sebuah cluster, dalam hitungan detik. Sistem Hadoop Distributed menggunakan kerangka MapReduce untuk menghasilkan sejumlah besar kerangka kerja yang akan memakan waktu beberapa menit atau jam.
Organisasi yang menggunakan Apache Storm
Setelah dikerahkan, Storm tidak hanya mudah dioperasikan tetapi juga mampu memproses data dalam hitungan detik. Mempertimbangkan banyak manfaat Storm, banyak organisasi telah menggunakannya.
1. Twitter
Apache Storm mendukung berbagai fungsi di Twitter. Storm terintegrasi dengan baik dengan infrastruktur Twitter lainnya, yang memiliki sistem basis data seperti Cassandra, Memcached, Mesos, infrastruktur perpesanan, pemantauan, dan sistem peringatan.
2. Infochimps
Infochimps menggunakan Storm sebagai sumber untuk salah satu layanan data cloud – Layanan Pengiriman Data. Ini mempekerjakan Storm untuk menyediakan pengumpulan data yang dapat diperluas secara linier, transportasi, dan pemrosesan in-stream yang rumit dari layanan cloud.
3. Spotify
Tidak diragukan lagi pemimpin dalam platform untuk streaming musik. Dengan 50 juta pengguna di seluruh dunia dan 10 juta pelanggan, ia menawarkan sejumlah besar konten real-time seperti rekomendasi musik, analitik, pembuatan iklan, dll. Apache Storm membantu Spotify dalam menghadirkan fitur-fitur ini secara akurat.
Hal ini juga memungkinkan perusahaan untuk memberikan sistem distribusi toleransi kesalahan dengan latensi rendah dengan mudah.
4. Bahan Bakar Roket
RocketFuel adalah perusahaan yang memanfaatkan kekuatan Artificial Intelligence untuk meningkatkan ROI pemasaran di media digital. Mereka ingin membangun platform di Storm yang dapat melacak tayangan, klik, permintaan tawaran, dll. secara real-time. Platform ini seharusnya bekerja dengan mengkloning alur kerja kritis dari pipeline ETL berbasis Hadoop.
5. Papan flip
Flipboard adalah toko serba ada untuk menjelajahi dan menyimpan semua berita yang menarik minat Anda. Di Flipboard, Apache Storm terintegrasi dengan sistem seperti Hadoop, ElasticSearch, HBase, dan HDFS untuk membuat platform yang sangat dapat diperluas.
Di sini, layanan seperti pencarian konten, analitik waktu nyata, umpan majalah khusus, dll. – semuanya disediakan dengan bantuan Apache Storm.
6. Wego
Wego adalah mesin metasearch perjalanan yang berasal dari Singapura. Di sini, data datang dari seluruh dunia, pada waktu yang berbeda. Dengan bantuan Storm, Wego dapat mencari data real-time, menyelesaikan masalah yang ada, dan memberikan hasil terbaik kepada pengguna akhir.
Baca Juga : Peran Apache Spark di Big Data.

Kesimpulan
Sebelum Storm ditulis, data waktu nyata diproses menggunakan pendekatan antrian dan utas pekerja. Beberapa antrian akan terus menulis data, dan yang lain akan terus membaca dan memprosesnya. Kerangka kerja ini tidak hanya sangat rapuh tetapi juga memakan waktu. Banyak waktu akan dihabiskan untuk menangani kehilangan data, memelihara seluruh kerangka kerja, membuat serial/deserialisasi pesan daripada melakukan pekerjaan yang sebenarnya.
Apache Storm adalah cara cerdas untuk hanya mengirimkan data sebagai Spout dan Bolt dan sisa pemrosesan sebagai Topologi.
Apache Storm adalah kerangka kerja komputasi yang lazim, open-source, dan pemrosesan aliran untuk menganalisis data secara real-time. Banyak organisasi sudah menggunakannya; pada kenyataannya, beberapa mengembangkan perangkat lunak yang lebih baik dan bermanfaat dengannya.
Jika Anda tertarik untuk mengetahui lebih banyak tentang Big Data, lihat Diploma PG kami dalam Spesialisasi Pengembangan Perangkat Lunak dalam program Big Data yang dirancang untuk para profesional yang bekerja dan menyediakan 7+ studi kasus & proyek, mencakup 14 bahasa & alat pemrograman, praktik langsung lokakarya, lebih dari 400 jam pembelajaran yang ketat & bantuan penempatan kerja dengan perusahaan-perusahaan top.
Pelajari Kursus Pengembangan Perangkat Lunak online dari Universitas top dunia. Dapatkan Program PG Eksekutif, Program Sertifikat Tingkat Lanjut, atau Program Magister untuk mempercepat karier Anda.