
Visão geral do Apache Storm: o que é, arquitetura e razões para usar
Publicados: 2020-03-23Os dados são onipresentes e, com o aumento da digitalização, novos desafios surgem todos os dias com relação ao gerenciamento e processamento de dados.
Ter acesso a dados em tempo real pode parecer um recurso “bom de se ter”, mas para uma organização com investimentos significativos na esfera digital, é quase uma necessidade.
Índice
Quais líderes do setor estão usando o Apache Storm?
Muitas vezes, os dados que não são analisados em um determinado momento podem em breve se tornar redundantes para as empresas. Analisar dados para encontrar padrões que possam ser vantajosos para a empresa é um requisito. Os padrões não precisam ser deduzidos por muito tempo; apenas os dados relevantes que ditam as tendências atuais em tempo real devem ser extraídos.
Considerando as necessidades e os retornos da análise de dados em tempo real, as organizações criaram várias ferramentas de análise. Uma dessas ferramentas é o Apache Storm.
O que é Apache Storm?
Lançado pelo Twitter, o Apache Storm é uma rede distribuída de código aberto que processa grandes quantidades de dados de várias fontes. A ferramenta analisa e atualiza os resultados para uma interface do usuário ou qualquer outro destino designado, sem armazenar nenhum dado. Leia mais sobre o Apache Storm.
O Apache Storm faz processamento em tempo real para blocos de dados ilimitados, semelhante ao padrão de processamento do Hadoop para lotes de dados.

Originalmente criado por Nathan Marz na Black Type, uma empresa de análise social, mais tarde foi adquirido e de código aberto pelo Twitter. Escrito em Java e Clojure, continua a ser o padrão para processamento de dados em tempo real na indústria.
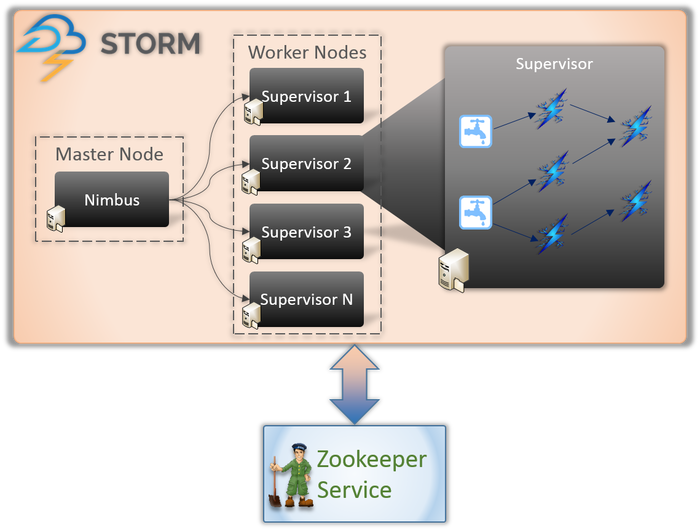
Arquitetura Apache Storm
1. Nimbus (Nó Mestre)
Nimbus é um daemon, ou seja, um programa que roda em segundo plano sem o controle de um usuário interativo. Ele é executado para o Apache Storm, semelhante ao funcionamento do Job tracker no Hadoop. Sua função exige atribuir códigos e tarefas às máquinas e até monitorar seus desempenhos.
2. Serviço de Supervisor (Nó do Trabalhador)
Os nós do trabalhador no Storm executam um serviço chamado Supervisor. Esses nós são responsáveis por receber o trabalho atribuído pela Nimbus a essas máquinas. Além de tratar de todo o trabalho atribuído pela Nimbus, ela inicia ou para o processo de acordo com a necessidade.
Cada um desses processos por Supervisores ajuda a executar uma parte do processo para completar a topologia.
3. Topologia
Storm Topology é uma rede que consiste em spouts e bolts. Cada nó do sistema está presente para processar lógicas e links e demonstrar os caminhos de onde os dados passarão.
Sempre que uma topologia é submetida ao Storm, a Nimbus consulta os Supervisores sobre os nós do trabalhador.
4. Fluxo
Streams são uma sequência de tuplas que são criadas e processadas de forma paralela distribuída. Mas o que são tuplas? Eles são as principais estruturas de dados no Storm. Eles são listas nomeadas de valores variados como inteiros, bytes, floots, arrays de bytes, etc.
5. Bico
Um Spout é uma porta de entrada para todos os dados em tuplas. Ele é responsável por entrar em contato com a fonte de dados real, receber os dados continuamente, transformá-los em tuplas e, finalmente, enviá-los para bolts para serem processados.
6. Parafusos
Os parafusos estão no centro de todo o processamento lógico no Storm. Portanto, eles realizam todo o processamento da topologia. Bolts podem ser usados para uma variedade de funções, incluindo filtragem, funções, agregações e até mesmo conexão com bancos de dados.

Saiba mais sobre: Arquitetura Apache Spark
Por que Apache Storm?
O funcionamento do Apache Storm é bastante semelhante ao do Hadoop. Ambas são redes distribuídas usadas para processamento de Big Data. Eles oferecem escalabilidade e são amplamente utilizados para fins de business intelligence. Então, por que Storm e por que é tão diferente?
Aqui estão as principais razões para escolher o Storm:
- O Storm faz processamento de fluxo em tempo real, enquanto o Hadoop faz principalmente processamento em lote.
- A topologia Storm é executada até ser encerrada pelo usuário. Os processos do Hadoop são concluídos eventualmente em ordem sequencial.
- Os processos do Storm podem acessar milhares de dados em um cluster, em segundos. O sistema Hadoop Distributed usa a estrutura MapReduce para produzir uma grande quantidade de estruturas que levarão minutos ou horas.
Organizações que usam o Apache Storm
Uma vez implantado, o Storm não é apenas fácil de operar, mas também é capaz de processar dados em segundos. Considerando os amplos benefícios do Storm, muitas organizações o utilizaram.
1. Twitter
O Apache Storm potencializa uma série de funções no Twitter. O Storm se integra bem com o restante da infraestrutura do Twitter, que possui sistemas de banco de dados como Cassandra, Memcached, Mesos, infraestrutura de mensagens, monitoramento e sistemas de alerta.
2. Infochimpanzés
A Infochimps usa o Storm como fonte para um de seus serviços de dados em nuvem – Data Delivery Services. Ele emprega o Storm para fornecer uma coleta de dados expansível linearmente, transporte e processamento in-stream complicado de serviços em nuvem.
3. Spotify
É sem dúvida o líder em plataformas para streaming de música. Com 50 milhões de usuários em todo o mundo e 10 milhões de assinantes, oferece uma enorme variedade de conteúdo em tempo real, como recomendações de músicas, análises, criações de anúncios, etc. O Apache Storm ajuda o Spotify a fornecer esses recursos com precisão.
Também permitiu que a empresa entregasse facilmente sistemas de distribuição tolerantes a falhas de baixa latência.
4. Combustível de Foguete
A RocketFuel é uma empresa que aproveita o poder da Inteligência Artificial para aumentar o ROI de marketing em mídia digital. Eles estão procurando construir uma plataforma no Storm que possa rastrear impressões, cliques, solicitações de lances etc. em tempo real. Essa plataforma deve funcionar clonando fluxos de trabalho críticos do pipeline ETL baseado em Hadoop.
5. Prancheta
O Flipboard é um balcão único para navegar e salvar todas as notícias que lhe interessam. No Flipboard, o Apache Storm é integrado a sistemas como Hadoop, ElasticSearch, HBase e HDFS para criar plataformas extremamente expansíveis.
Aqui, serviços como pesquisa de conteúdo, análise em tempo real, feed de revista personalizado, etc. – são todos fornecidos com a ajuda do Apache Storm.
6. Vamos
Wego é um mecanismo de metabusca de viagens que se originou em Cingapura. Aqui, os dados vêm de todo o mundo, em horários diferentes. Com a ajuda do Storm, o Wego é capaz de pesquisar dados em tempo real, resolver quaisquer problemas coexistentes e fornecer os melhores resultados ao usuário final.
Leia também: Papel do Apache spark no Big Data.

Conclusão
Antes do Storm ser escrito, os dados em tempo real eram processados usando filas e abordagens de thread de trabalho. Algumas filas estarão continuamente gravando dados e outras estarão constantemente lendo e processando-os. Essa estrutura não era apenas extremamente frágil, mas também demorada. Muito tempo seria gasto cuidando da perda de dados, mantendo toda a estrutura, serializando/desserializando mensagens em vez de realizar o trabalho real.
O Apache Storm é uma maneira inteligente de apenas enviar os dados como Spout e Bolt e o restante do processamento como Topologia.
O Apache Storm é uma estrutura de computação predominante, de código aberto e de processamento de fluxo para análise de dados em tempo real. Muitas organizações já o estão usando; na verdade, alguns estão desenvolvendo software melhor e útil com ele.
Se você estiver interessado em saber mais sobre Big Data, confira nosso programa PG Diploma in Software Development Specialization in Big Data, projetado para profissionais que trabalham e fornece mais de 7 estudos de caso e projetos, abrange 14 linguagens e ferramentas de programação, práticas práticas workshops, mais de 400 horas de aprendizado rigoroso e assistência para colocação de emprego com as principais empresas.
Aprenda cursos de desenvolvimento de software online das melhores universidades do mundo. Ganhe Programas PG Executivos, Programas de Certificado Avançado ou Programas de Mestrado para acelerar sua carreira.