
Przegląd Apache Storm: co to jest, architektura i powody, dla których warto korzystać
Opublikowany: 2020-03-23Dane są wszechobecne, a wraz z postępującą cyfryzacją każdego dnia pojawiają się nowe wyzwania w zakresie zarządzania i przetwarzania danych.
Posiadanie dostępu do danych w czasie rzeczywistym może wydawać się po prostu funkcją „przyjemną w posiadaniu”, ale dla organizacji ze znacznymi inwestycjami w sferę cyfrową jest to niemal konieczność.
Spis treści
Którzy liderzy branży używają Apache Storm?
Często dane, które nie są analizowane w danym momencie, mogą wkrótce stać się zbędne dla firm. Wymogiem jest analiza danych w celu znalezienia wzorców, które mogą być korzystne dla firmy. Wzorce nie muszą być wydedukowane przez długi czas; należy wyodrębnić tylko odpowiednie dane, które dyktują w czasie rzeczywistym aktualne trendy.
Biorąc pod uwagę potrzeby i korzyści płynące z analizy danych w czasie rzeczywistym, organizacje wymyśliły różne narzędzia analityczne. Jednym z takich narzędzi jest Apache Storm.
Co to jest Apache Storm?
Wydany przez Twittera Apache Storm to rozproszona sieć o otwartym kodzie źródłowym, która przetwarza duże ilości danych z różnych źródeł. Narzędzie analizuje je i aktualizuje wyniki do interfejsu użytkownika lub dowolnego innego wyznaczonego miejsca docelowego, bez przechowywania jakichkolwiek danych. Przeczytaj więcej o Apache Storm.
Apache Storm przetwarza w czasie rzeczywistym nieograniczone fragmenty danych, podobnie jak w przypadku przetwarzania partii danych w usłudze Hadoop.

Pierwotnie stworzony przez Nathana Marza w Black Type, firmie zajmującej się analizami społecznościowymi, został później przejęty i udostępniony przez Twittera. Napisany w Javie i Clojure, nadal stanowi standard przetwarzania danych w czasie rzeczywistym w branży.
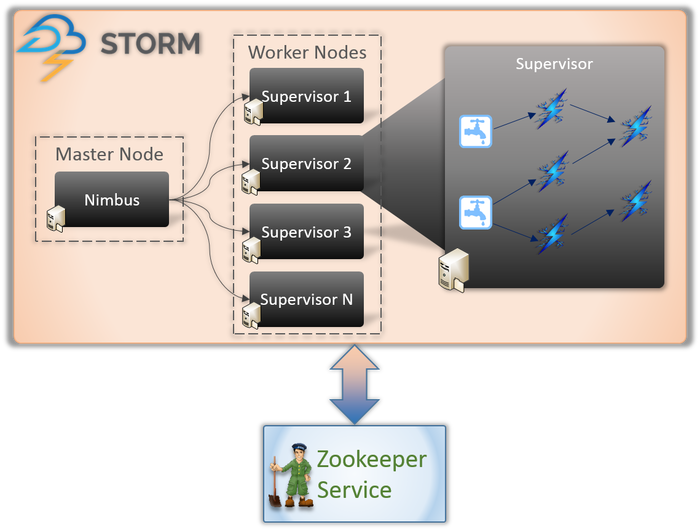
Architektura Apache Storm
1. Nimbus (węzeł główny)
Nimbus to demon, czyli program działający w tle bez kontroli interaktywnego użytkownika. Działa dla Apache Storm, podobnie jak działa Job Tracker w Hadoop. Jego funkcja wymaga przypisywania kodów i zadań do maszyn, a nawet monitorowania ich wydajności.
2. Usługa nadzorcy (węzeł roboczy)
Węzły robocze w Storm uruchamiają usługę o nazwie Supervisor. Węzły te są odpowiedzialne za odbieranie pracy przypisanej przez Nimbus do tych maszyn. Oprócz obsługi całej pracy zleconej przez Nimbus, uruchamia lub zatrzymuje proces zgodnie z wymaganiami.
Każdy z tych procesów przez Nadzorców pomaga wykonać część procesu w celu ukończenia topologii.
3. Topologia
Storm Topology to sieć składająca się z dziobków i śrub. Każdy węzeł w systemie jest obecny, aby przetwarzać logikę i łącza oraz demonstrować ścieżki, z których przechodzą dane.
Za każdym razem, gdy do Storm przesyłana jest topologia, Nimbus konsultuje się z nadzorcami w sprawie węzłów roboczych.
4. Strumień
Strumienie to sekwencja krotek, które są tworzone i przetwarzane w sposób równoległy. Ale czym są krotki? Są to główne struktury danych w Storm. Są to nazwane listy różnych wartości, takich jak liczby całkowite, bajty, floot, tablice bajtowe itp.
5. Wylewka
Spout to wejście do wszystkich danych w krotkach. Odpowiada za kontakt z rzeczywistym źródłem danych, ciągłe odbieranie danych, przekształcanie ich w krotki, a na koniec wysyłanie ich do śrub w celu przetworzenia.
6. Śruby
Bolty są sercem wszystkich procesów logicznych w Storm. Dlatego wykonują całe przetwarzanie topologii. Bolts mogą być używane do różnych funkcji, w tym filtrowania, funkcji, agregacji, a nawet łączenia się z bazami danych.

Dowiedz się więcej o: Architektura Apache Spark
Dlaczego Apache Storm?
Działanie Apache Storm jest bardzo podobne do działania Hadoopa. Obie są sieciami rozproszonymi wykorzystywanymi do przetwarzania Big Data. Oferują skalowalność i są szeroko stosowane do celów analizy biznesowej. Dlaczego więc Storm i dlaczego jest tak inny?
Oto kluczowe powody, dla których warto wybrać Storm:
- Storm przetwarza strumieniowo w czasie rzeczywistym, podczas gdy Hadoop wykonuje głównie przetwarzanie wsadowe.
- Topologia Storm działa do momentu wyłączenia przez użytkownika. Procesy Hadoop są ostatecznie realizowane w kolejności sekwencyjnej.
- Procesy Storm mogą w ciągu kilku sekund uzyskać dostęp do tysięcy danych w klastrze. System Hadoop Distributed wykorzystuje platformę MapReduce do tworzenia ogromnej liczby struktur, które potrwają minuty lub godziny.
Organizacje korzystające z Apache Storm
Po wdrożeniu Storm jest nie tylko łatwy w obsłudze, ale także może przetwarzać dane w kilka sekund. Biorąc pod uwagę szerokie zalety Storm, wiele organizacji wykorzystało go.
1. Twitter
Apache Storm obsługuje szereg funkcji na Twitterze. Storm dobrze integruje się z resztą infrastruktury Twittera, która ma systemy baz danych, takie jak Cassandra, Memcached, Mesos, infrastrukturę przesyłania wiadomości, systemy monitorowania i ostrzegania.
2. Szympansy
Infochimps wykorzystuje Storm jako źródło jednej ze swoich usług danych w chmurze – Data Delivery Services. Wykorzystuje Storm, aby zapewnić liniowo rozszerzalne gromadzenie danych, transport i skomplikowane przetwarzanie strumieniowe usług w chmurze.
3. Spotify
Jest bez wątpienia liderem platform do strumieniowego przesyłania muzyki. Dzięki 50 milionom użytkowników na całym świecie i 10 milionom subskrybentów oferuje ogromną gamę treści w czasie rzeczywistym, takich jak rekomendacje muzyczne, analizy, kreacje reklam itp. Apache Storm pomaga Spotify w dokładnym dostarczaniu tych funkcji.
Umożliwiło to również firmie łatwe dostarczanie odpornych na awarie systemów dystrybucyjnych o niskim opóźnieniu.
4. Paliwo rakietowe
RocketFuel to firma, która wykorzystuje moc sztucznej inteligencji do zwiększania zwrotu z inwestycji w marketing w mediach cyfrowych. Chcą zbudować platformę na Storm, która będzie mogła śledzić wyświetlenia, kliknięcia, zapytania ofertowe itp. w czasie rzeczywistym. Ta platforma ma działać poprzez klonowanie krytycznych przepływów pracy potoku ETL opartego na Hadoop.
5. Flipboard
Flipboard to punkt kompleksowej obsługi do przeglądania i zapisywania wszystkich interesujących Cię wiadomości. W Flipboard Apache Storm jest zintegrowany z systemami, takimi jak Hadoop, ElasticSearch, HBase i HDFS, aby tworzyć niezwykle rozszerzalne platformy.
W tym przypadku usługi takie jak wyszukiwanie treści, analityka w czasie rzeczywistym, niestandardowe źródła informacji o czasopismach itp. są świadczone za pomocą Apache Storm.
6. Wego
Wego to wyszukiwarka podróży, która powstała w Singapurze. Tutaj dane pochodzą z całego świata w różnym czasie. Z pomocą Storm, Wego jest w stanie wyszukiwać dane w czasie rzeczywistym, rozwiązywać współistniejące problemy i dostarczać najlepsze wyniki użytkownikowi końcowemu.
Przeczytaj także: Rola iskry Apache w Big Data.

Wniosek
Przed napisaniem Storm dane w czasie rzeczywistym były przetwarzane przy użyciu kolejek i podejść do wątków roboczych. Niektóre kolejki będą stale zapisywać dane, a inne będą je stale odczytywać i przetwarzać. Te ramy były nie tylko wyjątkowo kruche, ale także czasochłonne. Dużo czasu poświęciłoby się na utratę danych, utrzymanie całej struktury, serializowanie/deserializowanie wiadomości zamiast wykonywania rzeczywistej pracy.
Apache Storm to sprytny sposób na przesłanie danych jako Spout i Bolt, a resztę przetwarzania jako Topology.
Apache Storm to rozpowszechniona platforma obliczeniowa typu open source i przetwarzania strumieniowego do analizy danych w czasie rzeczywistym. Wiele organizacji już z niego korzysta; w rzeczywistości niektórzy opracowują za jego pomocą lepsze i przydatne oprogramowanie.
Jeśli chcesz dowiedzieć się więcej o Big Data, sprawdź nasz program PG Diploma in Software Development Specialization in Big Data, który jest przeznaczony dla pracujących profesjonalistów i zawiera ponad 7 studiów przypadków i projektów, obejmuje 14 języków programowania i narzędzi, praktyczne praktyczne warsztaty, ponad 400 godzin rygorystycznej pomocy w nauce i pośrednictwie pracy w najlepszych firmach.
Ucz się kursów rozwoju oprogramowania online z najlepszych światowych uniwersytetów. Zdobywaj programy Executive PG, Advanced Certificate Programs lub Masters Programs, aby przyspieszyć swoją karierę.