
Apache Storm 概述:什么是、架构和使用理由
已发表: 2020-03-23数据无处不在,随着数字化程度的提高,数据管理和处理每天都面临着新的挑战。
访问实时数据似乎只是一个“必备”功能,但对于在数字领域进行大量投资的组织来说,这几乎是必需品。
目录
哪些行业领导者正在使用 Apache Storm?
通常,在给定时间未分析的数据可能很快就会成为公司的多余数据。 分析数据以找到对公司有利的模式是一项要求。 模式不需要经过长时间的推演; 应该只提取指示实时、当前趋势的相关数据。
考虑到分析实时数据的需求和回报,组织提出了各种分析工具。 一种这样的工具是 Apache Storm。
什么是阿帕奇风暴?
由 Twitter 发布的 Apache Storm 是一个分布式开源网络,可以处理来自各种来源的大量数据。 该工具对其进行分析并将结果更新到 UI 或任何其他指定目标,而不存储任何数据。 阅读有关 Apache Storm 的更多信息。
Apache Storm 对无界数据块进行实时处理,类似于 Hadoop 处理数据批处理的模式。

它最初由社交分析公司 Black Type 的 Nathan Marz 创建,后来被 Twitter 收购并开源。 它用 Java 和 Clojure 编写,仍然是业界实时数据处理的标准。
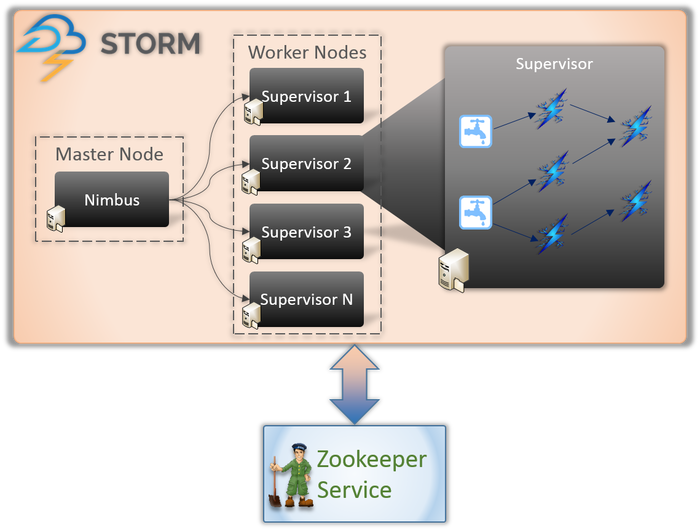
阿帕奇风暴架构
1. Nimbus(主节点)
Nimbus 是一个守护进程,即在后台运行的程序,不受交互式用户的控制。 它为 Apache Storm 运行,类似于 Hadoop 中 Job tracker 的工作方式。 它的功能要求它为机器分配代码和任务,甚至监控它们的性能。
2.主管服务(工作节点)
Storm 中的工作节点运行一个名为 Supervisor 的服务。 这些节点负责接收 Nimbus 分配给这些机器的工作。 除了处理 Nimbus 分配的所有工作外,它还根据需要启动或停止该过程。
主管的这些过程中的每一个都有助于执行过程的一部分以完成拓扑。
3. 拓扑
Storm Topology 是一个由 spout 和 bolts 组成的网络。 系统中的每个节点都存在以处理逻辑和链接,并展示数据将通过的路径。
每当向 Storm 提交拓扑时,Nimbus 都会向 Supervisor 咨询工作节点。
4.流
流是一系列以并行分布式方式创建和处理的元组。 但什么是元组? 它们是 Storm 中的主要数据结构。 它们被命名为不同值的列表,如整数、字节、浮点数、字节数组等。

5. 喷口
Spout 是元组中所有数据的入口。 它负责与实际数据源取得联系,不断接收数据,将其转换为元组,最后发送到bolts进行处理。
6. 螺栓
Bolts 是 Storm 中所有逻辑处理的核心。 因此,它们执行拓扑的所有处理。 Bolts 可用于多种功能,包括过滤、函数、聚合,甚至连接数据库。
了解: Apache Spark 架构
为什么选择阿帕奇风暴?
Apache Storm 的工作方式与 Hadoop 非常相似。 两者都是用于处理大数据的分布式网络。 它们提供可扩展性并广泛用于商业智能目的。 那么,为什么是 Storm,为什么它如此不同?
以下是选择 Storm 的主要原因:
- Storm 做实时流处理,而 Hadoop 主要做批处理。
- Storm 拓扑一直运行到用户关闭为止。 Hadoop 进程最终按顺序完成。
- Storm 进程可以在几秒钟内访问集群上的数千个数据。 Hadoop 分布式系统使用 MapReduce 框架生成大量框架,这些框架需要几分钟或几小时。
使用 Apache Storm 的组织
部署后,Storm 不仅易于操作,而且能够在几秒钟内处理数据。 考虑到 Storm 的诸多好处,许多组织已经开始使用它。
1. 推特
Apache Storm 为 Twitter 的一系列功能提供支持。 Storm 与 Twitter 的其他基础架构很好地集成在一起,后者拥有 Cassandra、Memcached、Mesos 等数据库系统、消息传递基础架构、监控和警报系统。
2. 信息猩猩
Infochimps 使用 Storm 作为其云数据服务之一——数据交付服务的来源。 它使用 Storm 来提供可线性扩展的数据收集、传输和云服务的复杂流内处理。
3. Spotify
它无疑是流媒体音乐平台的领导者。 它在全球拥有 5000 万用户和 1000 万订阅者,提供大量实时内容,如音乐推荐、分析、广告创作等。Apache Storm 帮助 Spotify 准确地提供这些功能。
它还使公司能够轻松交付低延迟容错分配系统。
4.火箭燃料
RocketFuel 是一家利用人工智能的力量来扩大数字媒体营销投资回报率的公司。 他们希望在 Storm 上构建一个平台,可以实时跟踪展示次数、点击次数、出价请求等。 该平台应该通过克隆基于 Hadoop 的 ETL 管道的关键工作流来工作。
5. 活动板
Flipboard 是浏览和保存所有您感兴趣的新闻的一站式商店。 在 Flipboard,Apache Storm 与 Hadoop、ElasticSearch、HBase 和 HDFS 等系统集成,以创建极其可扩展的平台。
在这里,内容搜索、实时分析、自定义杂志订阅等服务都是在 Apache Storm 的帮助下提供的。
6. 威高
Wego 是一个起源于新加坡的旅游元搜索引擎。 在这里,数据来自世界各地,时间不同。 在 Storm 的帮助下,Wego 能够搜索实时数据,解决任何共存的问题,并为最终用户提供最佳结果。
另请阅读:Apache spark 在大数据中的作用。

结论
在编写 Storm 之前,使用队列和工作线程方法处理实时数据。 一些队列会不断地写入数据,而另一些队列会不断地读取和处理它。 这个框架不仅非常脆弱,而且时间很长。 很多时间会花在处理数据丢失、维护整个框架、序列化/反序列化消息而不是执行实际工作上。
Apache Storm 是一种巧妙的方式,只需将数据作为 Spout 和 Bolt 提交,其余处理作为拓扑提交。
Apache Storm 是一种流行的开源流处理计算框架,用于实时分析数据。 许多组织已经在使用它; 事实上,有些人正在用它开发更好和有用的软件。
如果您有兴趣了解有关大数据的更多信息,请查看我们的 PG 大数据软件开发专业文凭课程,该课程专为在职专业人士设计,提供 7 多个案例研究和项目,涵盖 14 种编程语言和工具,实用的动手操作研讨会,超过 400 小时的严格学习和顶级公司的就业帮助。
从世界顶级大学在线学习软件开发课程。 获得行政 PG 课程、高级证书课程或硕士课程,以加快您的职业生涯。