
梯度下降算法:方法、變體和最佳實踐
已發表: 2020-07-28優化是機器學習的一個組成部分。 幾乎所有機器學習算法都將優化功能作為關鍵部分。 正如這個詞所暗示的,機器學習中的優化是找到問題陳述的最佳解決方案。
在本文中,您將了解使用最廣泛的優化算法之一,梯度下降。 梯度下降算法可以與任何機器學習算法一起使用,並且易於理解和實現。 那麼,梯度下降究竟是什麼? 在本文結束時,您將對梯度下降算法以及如何使用它來更新模型的參數有一個更清晰的了解。
目錄
梯度下降
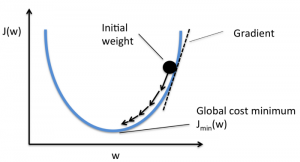
在深入了解梯度下降算法之前,您應該知道什麼是成本函數。 成本函數是用於衡量給定數據集的模型性能的函數。 它找到您的預測值和預期值之間的差異,從而量化誤差範圍。
目標是降低成本函數,使模型準確。 為了實現這一目標,您需要在模型的訓練過程中找到所需的參數。 梯度下降是一種這樣的優化算法,用於找到函數的係數以降低成本函數。 成本函數最小的點稱為全局最小值。
資源
梯度下降算法背後的直覺
假設你有一個大碗,類似於裝水果的東西。這個碗是成本函數的圖。 碗底是成本函數最小的最佳係數。 使用不同的值作為係數來計算成本函數。 重複此步驟,直到找到最佳係數。

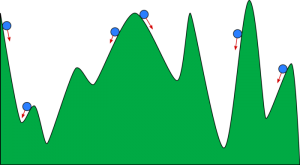
你可以把梯度下降想像成一個滾下山谷的球。 谷是這裡成本函數的圖。 您希望球到達谷底,谷底代表最小的成本函數。 根據球的起始位置,它可能停留在山谷的許多底部。 然而,這些底部可能不是最低點,被稱為局部最小值。
資源
閱讀:促進機器學習:什麼是、功能、類型和特徵
梯度下降算法 - 方法論
梯度下降的計算從函數係數的初始值被設置為 0 或一個小的隨機值開始。
係數 = 0(或小值)
- 成本函數是通過將該係數的值放入函數中來計算的。
成本函數 = f(係數)
- 我們從微積分的概念中知道,函數的導數是函數的斜率。 計算斜率將幫助您確定移動係數值的方向。 方向應該使您在下一次迭代中獲得較低的成本(錯誤)。
del = 導數(成本函數)

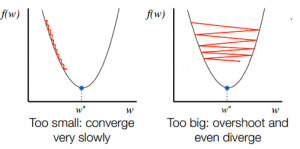
- 在知道斜坡的下坡方向後,您相應地更新係數值。 可以選擇學習率 (alpha) 來控制這些係數在每次迭代中的變化程度。 你需要確保這個學習率既不太高也不太低。
係數 = 係數 - (alpha * del)
- 重複此過程,直到成本函數變為 0 或非常接近 0。
f(係數) = 0 (或接近 0)
學習率的選擇很重要。 選擇一個非常高的學習率可能會超過全局最小值。 相反,非常低的學習率可以幫助你達到全局最小值,但收斂速度非常慢,需要多次迭代。
資源
梯度下降算法的變體
批量梯度下降
批量梯度下降是梯度下降算法最常用的變體之一。 成本函數是在每次迭代的整個訓練數據集上計算的。 一批稱為算法的一次迭代,這種形式稱為批梯度下降。
隨機梯度下降
在某些情況下,訓練集可能非常大。 在這些情況下,批量梯度下降將需要很長時間來計算,因為一次迭代需要對訓練集中的每個實例進行預測。 在數據集很大的情況下,您可以使用隨機梯度下降。 在隨機梯度下降中,係數會針對每個訓練實例更新,而不是在實例批次結束時更新。
小批量梯度下降
批量梯度下降和隨機梯度下降都有其優點和缺點。 然而,使用批量梯度下降和隨機梯度下降的混合是有用的。 在小批量梯度下降中,既不會使用整個數據集,也不會一次使用單個實例。 您考慮了一組訓練示例。 該組中的示例數量少於整個數據集,該組稱為小批量。
梯度下降算法的最佳實踐
- 繪製成本與時間的關係圖:繪製相對於時間的成本有助於您可視化每次迭代後成本是否下降。 如果您看到成本保持不變,請嘗試更新學習率。
- 學習率:學習率很低,常選為0.01或0.001。 您需要嘗試看看哪種值最適合您。
- 重新縮放輸入:如果將所有輸入變量重新縮放到相同的範圍,例如 [0, 1] 或 [-1, 1],梯度下降算法將更快地最小化成本函數。
- 更少的通過次數:通常,隨機梯度下降算法不需要超過 10 次通過即可找到最佳係數。
查看: 25 個機器學習面試問題和答案
包起來
您將了解梯度下降在優化機器學習算法中的作用。 要記住的一個重要因素是為您的梯度下降算法選擇正確的學習率以獲得最佳預測。
upGrad 提供機器學習和人工智能的PG 文憑和機器學習和人工智能的理學碩士,可以指導您建立職業生涯。 這些課程將解釋機器學習的必要性以及收集該領域知識的進一步步驟,涵蓋從梯度下降算法到神經網絡的各種概念。