
Algorytm opadania gradientu: metodologia, warianty i najlepsze praktyki
Opublikowany: 2020-07-28Optymalizacja jest integralną częścią uczenia maszynowego. Prawie wszystkie algorytmy uczenia maszynowego mają funkcję optymalizacji jako kluczowy segment. Jak sugeruje to słowo, optymalizacja w uczeniu maszynowym polega na znalezieniu optymalnego rozwiązania problemu.
W tym artykule przeczytasz o jednym z najczęściej używanych algorytmów optymalizacyjnych, opadaniu gradientowym. Algorytm gradientu może być używany z dowolnym algorytmem uczenia maszynowego i jest łatwy do zrozumienia i wdrożenia. Czym dokładnie jest zejście gradientowe? Pod koniec tego artykułu lepiej zrozumiesz algorytm opadania gradientu i sposób, w jaki można go wykorzystać do aktualizacji parametrów modelu.
Spis treści
Zejście gradientowe
Zanim zagłębisz się w algorytm gradientu, powinieneś wiedzieć, czym jest funkcja kosztu. Funkcja kosztu to funkcja służąca do mierzenia wydajności modelu dla danego zestawu danych. Znajduje różnicę między wartością przewidywaną a wartością oczekiwaną, określając w ten sposób margines błędu.
Celem jest zmniejszenie funkcji kosztu, aby model był dokładny. Aby osiągnąć ten cel, musisz znaleźć wymagane parametry podczas uczenia swojego modelu. Spadek gradientu jest jednym z takich algorytmów optymalizacji stosowanych do znajdowania współczynników funkcji w celu zmniejszenia funkcji kosztu. Punkt, w którym funkcja kosztu jest minimalna, jest znany jako minima globalne.
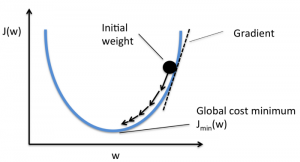
Źródło
Intuicja stojąca za algorytmem Gradient Descent
Załóżmy, że masz dużą miskę podobną do tej, w której masz owoce. Ta miska jest wykresem funkcji kosztu. Dno miski to najlepszy współczynnik, dla którego funkcja kosztu jest minimalna. Różne wartości są używane jako współczynniki do obliczania funkcji kosztu. Ten krok jest powtarzany aż do znalezienia najlepszych współczynników.

Możesz sobie wyobrazić zejście w dół jako kulę toczącą się w dolinie. Dolina jest tu działką pod funkcję kosztową. Chcesz, aby piłka dotarła do dna doliny, gdzie dno doliny reprezentuje funkcję o najniższym koszcie. W zależności od pozycji startowej kula może spoczywać na wielu dnach doliny. Jednak te dna mogą nie być najniższymi punktami i są znane jako lokalne minima.
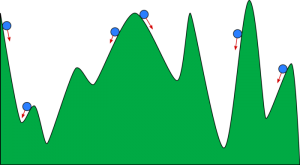
Źródło
Przeczytaj: Wzmacnianie uczenia maszynowego: co to jest, funkcje, typy i cechy
Algorytm opadania gradientu — metodologia
Obliczanie opadania gradientu rozpoczyna się od ustawienia początkowych wartości współczynników funkcji na 0 lub małą wartość losową.
współczynnik = 0 (lub mała wartość)
- Funkcja kosztu jest obliczana poprzez umieszczenie tej wartości współczynnika w funkcji.
Funkcja kosztu = f(współczynnik)
- Z pojęcia rachunku różniczkowego wiemy, że pochodną funkcji jest nachylenie funkcji. Obliczenie nachylenia pomoże Ci określić kierunek przesunięcia wartości współczynników. Kierunek powinien być taki, aby w następnej iteracji uzyskać niższy koszt (błąd).
del = pochodna (funkcja kosztu)
- Znając kierunek zjazdu ze stoku, odpowiednio aktualizujesz wartości współczynników. Szybkość uczenia się (alfa) można wybrać, aby kontrolować, jak bardzo te współczynniki będą się zmieniać w każdej iteracji. Musisz upewnić się, że ten wskaźnik uczenia się nie jest ani zbyt wysoki, ani zbyt niski.
współczynnik = współczynnik – (alfa * del)

- Ten proces jest powtarzany, aż funkcja kosztu osiągnie wartość 0 lub bardzo blisko 0.
f(współczynnik) = 0 (lub blisko 0)
Ważny jest wybór tempa uczenia się. Wybór bardzo wysokiego współczynnika uczenia się może przekroczyć globalne minima. Wręcz przeciwnie, bardzo niski wskaźnik uczenia się może pomóc w osiągnięciu globalnych minimów, ale konwergencja jest bardzo powolna i wymaga wielu iteracji.
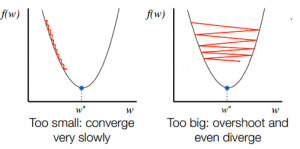
Źródło
Warianty algorytmu opadania gradientu
Gradient wsadowy
Gradient wsadowy jest jednym z najczęściej używanych wariantów algorytmu gradientowego. Funkcja kosztu jest obliczana w całym uczącym zbiorze danych dla każdej iteracji. Jedna partia jest określana jako jedna iteracja algorytmu, a ta forma jest znana jako opadanie gradientu partii.
Stochastyczne zejście gradientowe
W niektórych przypadkach zestaw treningowy może być bardzo duży. W takich przypadkach obliczanie gradientu wsadowego zajmie dużo czasu, ponieważ jedna iteracja wymaga prognozy dla każdego wystąpienia w zestawie uczącym. Stochastycznego spadku gradientu można użyć w tych warunkach, w których zbiór danych jest ogromny. W stochastycznym zejściu gradientowym współczynniki są aktualizowane dla każdej instancji szkoleniowej, a nie na końcu partii instancji.
Mini-partia Gradient Descent
Zarówno zejście gradientu partii, jak i zejście gradientu stochastycznego mają swoje zalety i wady. Jednak przydatne może być użycie mieszaniny opadania gradientu wsadowego i spadku gradientu stochastycznego. W przypadku opadania gradientowego mini-partii nie jest używany cały zestaw danych ani nie jest używana pojedyncza instancja na raz. Bierzesz pod uwagę grupę przykładów treningowych. Liczba przykładów w tej grupie jest mniejsza niż cały zestaw danych, a ta grupa jest znana jako mini-partia.
Najlepsze praktyki dotyczące algorytmu opadania gradientu
- Koszt mapy w funkcji czasu: wykreślanie kosztów w zależności od czasu pomaga zwizualizować, czy po każdej iteracji koszt maleje, czy nie. Jeśli widzisz, że koszt pozostaje niezmieniony, spróbuj zaktualizować współczynnik uczenia się.
- Szybkość uczenia się: Szybkość uczenia się jest bardzo niska i często jest wybierana jako 0,01 lub 0,001. Musisz spróbować i zobaczyć, która wartość jest dla Ciebie najlepsza.
- Przeskaluj dane wejściowe: Algorytm spadku gradientu szybciej zminimalizuje funkcję kosztu, jeśli wszystkie zmienne wejściowe zostaną przeskalowane do tego samego zakresu, na przykład [0, 1] lub [-1, 1].
- Mniej przebiegów: Zwykle algorytm stochastycznego spadku gradientu nie wymaga więcej niż 10 przebiegów, aby znaleźć najlepsze współczynniki.
Sprawdź: 25 pytań i odpowiedzi dotyczących uczenia maszynowego
Zawijanie
Poznasz rolę gradientu w optymalizacji algorytmu uczenia maszynowego. Jednym z ważnych czynników, o których należy pamiętać, jest wybór odpowiedniej szybkości uczenia się dla algorytmu opadania gradientu w celu optymalnego przewidywania.
upGrad zapewnia dyplom PG w dziedzinie uczenia maszynowego i sztucznej inteligencji oraz tytuł magistra w dziedzinie uczenia maszynowego i sztucznej inteligencji , które mogą poprowadzić Cię w kierunku budowania kariery. Kursy te wyjaśnią potrzebę uczenia maszynowego i dalszych kroków w celu gromadzenia wiedzy w tej dziedzinie, obejmującej różne koncepcje, od algorytmów gradientu po sieci neuronowe.