
L'analyse exploratoire des données et son importance pour votre entreprise
Publié: 2018-02-22La plupart des discussions sur l'analyse des données traitent de l'aspect « scientifique » de celle-ci. Certes, il y a beaucoup de science derrière tout le processus – les algorithmes, les formules et les calculs, mais vous ne pouvez pas en retirer « l'art ». Structurer l'ensemble du processus - de la planification de l'analyse à la compréhension du résultat final - n'est pas une mince affaire, et n'est rien de moins qu'une forme d'art. C'est exactement ce qui relève de notre sujet du jour - l'analyse exploratoire des données. Dans cet article, nous examinerons ce qu'est l'analyse exploratoire des données, quels sont les outils et techniques courants pour cela, et comment cela aide-t-il une organisation.
Table des matières
Qu'est-ce que l'analyse exploratoire des données ?
L'analyse exploratoire des données est l'une des étapes importantes du processus d'analyse des données. Ici, l'accent est mis sur la compréhension des données en main - des choses comme formuler les bonnes questions à poser à votre ensemble de données, comment manipuler les sources de données pour obtenir les réponses requises, etc. Cela se fait en jetant un regard élaboré sur les tendances, les modèles et les valeurs aberrantes à l'aide d'une méthode visuelle. 
L'analyse exploratoire des données est une étape cruciale avant de passer à l'apprentissage automatique ou à la modélisation de vos données. Il fournit le contexte nécessaire pour développer un modèle approprié et interpréter correctement les résultats.
Manipulation de données : comment détecter les mensonges de données ?
Au fil des ans, l'apprentissage automatique a pris de l'ampleur, ce qui a donné naissance à un certain nombre d'algorithmes d'apprentissage automatique puissants. Si puissants qu'ils vous incitent presque à ignorer la phase d'analyse exploratoire des données. Bien qu'il soit compréhensible que vous vouliez profiter de tels algorithmes et ignorer l'EDA, ce n'est pas une très bonne idée de simplement introduire des données dans une boîte noire et d'attendre les résultats. Il a été observé à maintes reprises que l'analyse exploratoire des données fournit de nombreuses informations essentielles qu'il est très facile de manquer - des informations qui aident l'analyse à long terme, de la formulation des questions à l'affichage des résultats. Si vous êtes débutant et que vous souhaitez en savoir plus sur la science des données, consultez notre formation en science des données dispensée par les meilleures universités.
Alors que les aspects de l'EDA existent depuis que nous avons des données à analyser, l'analyse exploratoire des données a été officiellement développée dans les années 1970 par John Turkey - le même scientifique qui a inventé le mot "Bit" (abréviation de Binary Digit). L'EDA est souvent considérée et décrite comme une philosophie plus qu'une science, car il n'y a pas de règles strictes pour l'aborder. L'objectif de l'analyse exploratoire des données est essentiel pour s'attaquer à des tâches spécifiques telles que :
- Repérer les données manquantes et erronées ;
- Cartographier et comprendre la structure sous-jacente de vos données ;
- Identifier les variables les plus importantes de votre ensemble de données ;
- Tester une hypothèse ou vérifier des hypothèses liées à un modèle spécifique ;
- Établir un modèle parcimonieux (qui peut expliquer vos données en utilisant des variables minimales) ;
- Estimation des paramètres et détermination des marges d'erreur.
Outils et techniques utilisés dans l'analyse exploratoire des données
S-Plus et R sont les langages de programmation statistique les plus importants utilisés pour effectuer une analyse exploratoire des données. Ces langages sont livrés avec une pléthore d'outils qui vous aident à exécuter des fonctions statistiques spécifiques telles que :
Techniques de classification et de réduction de dimension
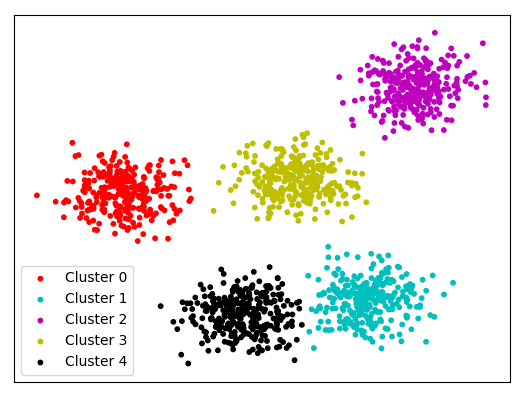
La classification est essentiellement utilisée pour regrouper différents ensembles de données sur la base d'un paramètre/variable commun. Les données dont nous parlons sont multidimensionnelles et il n'est pas facile d'effectuer une classification ou un regroupement sur un ensemble de données multidimensionnel. Par conséquent, pour aider à cela, des techniques de réduction de la dimensionnalité telles que PCA et LDA sont exécutées - elles réduisent la dimensionnalité de l'ensemble de données sans perdre aucune information précieuse de vos données.
Comment le paradoxe de Simpson affecte-t-il les données ?
Visualisation univariée
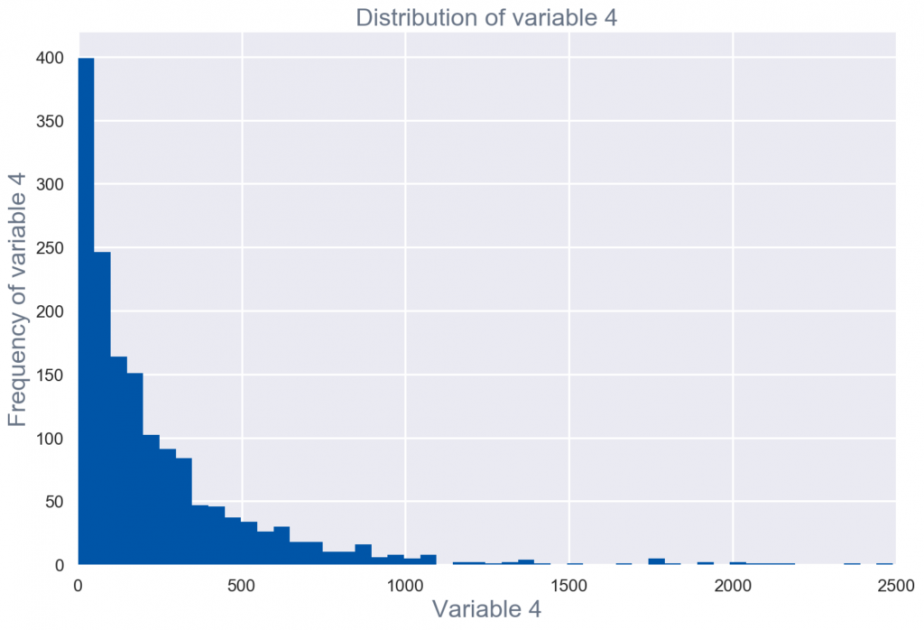
Les visualisations univariées sont essentiellement des distributions de probabilité de chaque champ de l'ensemble de données brutes - avec des statistiques récapitulatives. Les visualisations univariées utilisent des tables de distribution de fréquences, des graphiques à barres, des histogrammes ou des graphiques à secteurs pour la représentation graphique.
Visualisations bivariées
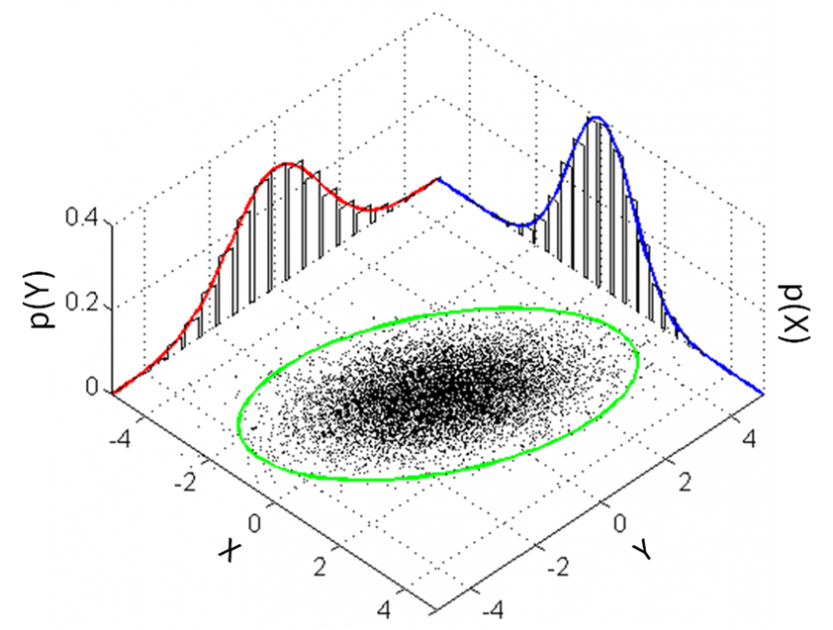
Ceux-ci permettent aux scientifiques des données d'évaluer la relation entre les variables de votre ensemble de données et vous aident à cibler la variable que vous examinez. Les graphiques appropriés pour l'analyse bivariée dépendent du type de variable en question. Par exemple, si vous avez affaire à deux variables continues, un nuage de points devrait être le graphique de votre choix. Si l'une est catégorique et l'autre est continue, une boîte à moustaches est préférée et lorsque les deux variables sont catégorielles, un diagramme en mosaïque est choisi.
Le business de la sécurité des données est en plein essor !
Visualisations multivariées
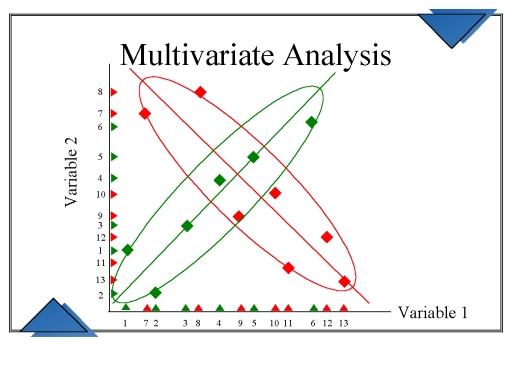
Les visualisations multivariées aident à comprendre les interactions entre les différents champs de données. Cela implique l'observation et l'analyse de plus d'une variable de résultat statistique à un moment donné.

K-means clustering
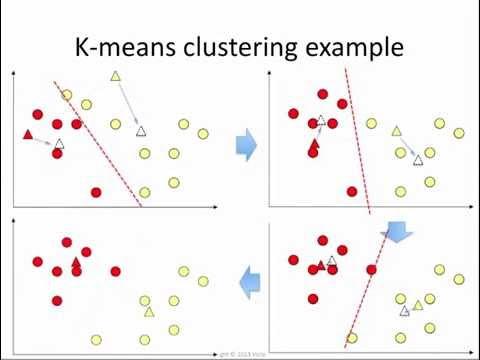
Le clustering K-means est essentiellement utilisé pour créer des "centres" pour chaque cluster en fonction de la moyenne la plus proche. Il s'agit d'une technique itérative qui continue de créer et de recréer des clusters - jusqu'à ce que les clusters formés cessent de changer avec les itérations. Il peut être utilisé pour trouver des valeurs aberrantes dans un ensemble de données (les points qui ne seront pas une forme de clusters seront idéalement des valeurs aberrantes).
Modèles prédictifs
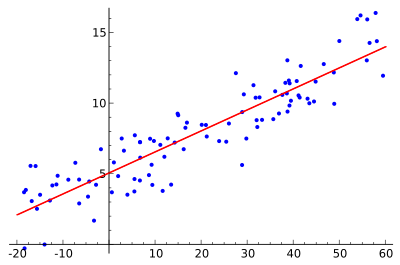
Comme son nom l'indique, la modélisation prédictive est une méthode qui utilise des statistiques pour prédire les résultats. Bien que la plupart des prédictions visent à prédire ce qui se passera dans le futur, la modélisation prédictive peut également être appliquée à tout événement inconnu, quel que soit le moment où il est susceptible de se produire. Par exemple, cette technique peut être utilisée pour détecter un crime et identifier des suspects même après que le crime a été commis. La manière la plus courante d'effectuer une modélisation prédictive consiste à utiliser la régression linéaire (voir l'image).
Qu'est-ce que l'entreposage de données et l'exploration de données ?
Comment l'analyse exploratoire des données aide-t-elle votre entreprise et où se situe-t-elle ?
L'analyse exploratoire des données offre la plus grande valeur à toute entreprise en aidant les scientifiques à comprendre si les résultats qu'ils ont produits sont correctement interprétés et s'ils s'appliquent aux contextes commerciaux requis. En plus de garantir des résultats techniquement fiables, l'analyse exploratoire des données profite également aux parties prenantes en confirmant si les questions qu'elles posent sont correctes ou non. La science des données exploratoire se présente souvent avec des informations imprévisibles - celles que les parties prenantes ou les scientifiques des données ne se soucieraient même pas d'étudier en général, mais qui peuvent néanmoins s'avérer très informatives sur l'entreprise.
Il existe un certain nombre de connecteurs de données qui aident les organisations à intégrer l'analyse exploratoire des données directement dans leur logiciel de Business Intelligence. Vous pouvez également configurer cela pour permettre aux données de circuler également dans l'autre sens, en créant et en exécutant des modèles statistiques dans (par exemple) R qui utilisent des données BI et se mettent automatiquement à jour à mesure que de nouvelles informations circulent dans le modèle.
Les cas d'utilisation potentiels de l'analyse exploratoire des données sont très variés, mais en fin de compte, tout se résume à ceci : l'analyse exploratoire des données consiste à apprendre à connaître et à comprendre vos données avant de faire des hypothèses à leur sujet ou de prendre des mesures dans la direction. de l'exploration de données. Cela vous aide à éviter de créer des modèles inexacts ou de construire des modèles précis sur de mauvaises données.
Une bonne exécution de cette étape donnera à toute organisation la confiance nécessaire dans ses données, ce qui lui permettra éventuellement de commencer à déployer de puissants algorithmes d'apprentissage automatique. Cependant, ignorer cette étape cruciale peut vous amener à construire votre système de Business Intelligence sur des bases très fragiles.
12 façons de connecter l'analyse de données aux résultats commerciaux
En conclusion…
L'analyse exploratoire des données est très clairement l'une des étapes importantes de tout le processus d'extraction des connaissances. Si vous souhaitez établir une base solide pour votre processus d'analyse global, vous devez vous concentrer de toutes vos forces sur la phase EDA. En toute honnêteté, un peu de statistiques est nécessaire pour réussir cette étape. Si vous sentez que vous êtes à la traîne sur ce front, n'oubliez pas de lire notre article sur les bases des statistiques nécessaires à la science des données.
Apprenez des cours de science des données en ligne dans les meilleures universités du monde. Gagnez des programmes Executive PG, des programmes de certificat avancés ou des programmes de maîtrise pour accélérer votre carrière.
Si vous êtes intéressé à apprendre python et que vous voulez vous salir les mains sur divers outils et bibliothèques, consultez le programme Executive PG in Data Science. Oh, et que pensez-vous de notre position de considérer « l'analyse exploratoire des données » comme un art plus qu'une science ? Faites-nous savoir dans les commentaires ci-dessous!
Pourquoi un Data Scientist devrait-il utiliser l'analyse exploratoire des données pour améliorer votre entreprise ?
L'objectif principal de l'analyse exploratoire des données est d'aider à l'analyse des données avant de formuler des hypothèses. Cela peut aider à la détection d'erreurs évidentes, à une meilleure compréhension des modèles de données, à la détection de valeurs aberrantes ou d'événements inattendus et à la découverte de corrélations intéressantes entre les variables.
Les scientifiques des données peuvent utiliser une analyse exploratoire pour s'assurer que les résultats qu'ils produisent sont exacts et acceptables pour tous les résultats et objectifs commerciaux souhaités. L'EDA assiste également les parties prenantes en s'assurant qu'elles posent les bonnes questions. Les écarts-types, les variables catégorielles et les intervalles de confiance peuvent tous être résolus avec EDA. Après l'achèvement de l'EDA et l'extraction des informations, ses fonctionnalités peuvent être appliquées à une analyse ou à une modélisation de données plus avancée, y compris l'apprentissage automatique.
Quels sont les cas d'utilisation les plus populaires pour EDA ?
Il n'est pas rare que les scientifiques des données utilisent l'EDA avant de lier d'autres types de modélisation. Il est souvent utilisé dans l'analyse de données pour examiner des ensembles de données afin d'identifier les valeurs aberrantes, les tendances, les modèles et les erreurs. Par exemple, l'EDA est couramment utilisé dans le commerce de détail où les outils de BI et les experts analysent les données pour découvrir des informations sur les tendances des ventes, les principales catégories, etc., l'EDA est également utilisé dans la recherche sur les soins de santé pour identifier les nouvelles tendances sur un marché ou une industrie, en déterminant grippe qui pourrait être plus répandue lors de la nouvelle saison grippale, vérification de l'homogénéité de la population de patients, etc.
Quels sont les types d'analyse exploratoire des données ?
Les types d'analyse exploratoire des données sont
1. Non graphique univarié : L'objectif standard de l'EDA non graphique univarié est de comprendre la distribution/les données de l'échantillon et de faire des observations de population.
2. Graphique univarié : Histogrammes, Stem-and-leaf plots, Box Plots, etc.
3. Non graphique multivarié : ces techniques EDA utilisent des tableaux croisés ou des statistiques pour décrire la relation entre deux ou plusieurs variables de données.
4. Graphique multivarié : Les représentations graphiques des relations entre deux ou plusieurs types de données sont utilisées dans les données multivariées.