
探索的データ分析とそのビジネスにとっての重要性
公開: 2018-02-22データ分析に関する議論のほとんどは、その「科学」の側面を扱っています。 確かに、プロセス全体の背後には多くの科学があります–アルゴリズム、式、計算ですが、それから「芸術」を取り除くことはできません。 分析の計画から最終結果の理解までの完全なプロセスを構築することは、平均的な偉業ではなく、芸術の形に他なりません。 それこそが、その日のトピックである探索的データ分析に当てはまるものです。 この記事では、探索的データ分析とは何か、そのための一般的なツールと手法は何か、そしてそれが組織にどのように役立つかを見ていきます。
目次
探索的データ分析とは何ですか?
探索的データ分析は、データ分析プロセスの重要なステップの1つです。 ここでは、手元にあるデータの意味を理解することに焦点を当てています。たとえば、データセットに尋ねる正しい質問の作成、データソースを操作して必要な回答を得る方法などです。 これは、視覚的な方法を使用して、傾向、パターン、および外れ値を詳細に調べることによって行われます。 
探索的データ分析は、機械学習やデータのモデリングに進む前の重要なステップです。 適切なモデルを開発し、結果を正しく解釈するために必要なコンテキストを提供します。
データ操作:データの嘘をどのように見つけることができますか?
何年にもわたって、機械学習は増加してきました–そしてそれは多くの強力な機械学習アルゴリズムを生み出しました。 非常に強力であるため、探索的データ分析フェーズをスキップするように誘惑されます。 このようなアルゴリズムを利用してEDAをスキップする理由は理解できますが、データをブラックボックスにフィードして結果を待つのはあまり良い考えではありません。 探索的データ分析は、見逃しがちな多くの重要な情報を提供することが何度も観察されています。これらの情報は、質問のフレーミングから結果の表示まで、長期的に分析に役立ちます。 初心者でデータサイエンスについて詳しく知りたい場合は、一流大学のデータサイエンストレーニングをご覧ください。
EDAの側面は、分析するデータがある限り存在していましたが、探索的データ分析は1970年代に、「ビット」(Binary Digitの略)という言葉を生み出した同じ科学者であるジョンテューカーによって正式に開発されました。 EDAにアプローチするための厳格なルールがないため、EDAは科学よりも哲学として見られ、説明されることがよくあります。 探索的データ分析の目的は、次のような特定のタスクに取り組むために不可欠です。
- 欠落しているデータや誤ったデータを見つける。
- データの基本構造のマッピングと理解。
- データセット内の最も重要な変数を特定します。
- 仮説をテストするか、特定のモデルに関連する仮定を確認します。
- 倹約的なモデル(最小変数を使用してデータを説明できるモデル)を確立する。
- パラメータを推定し、許容誤差を計算します。
探索的データ分析で使用されるツールと手法
S-PlusとRは、探索的データ分析の実行に使用される最も重要な統計プログラミング言語です。 これらの言語には、次のような特定の統計機能を実行するのに役立つ多数のツールがバンドルされています。
分類と次元削減の手法
分類は基本的に、共通のパラメーター/変数に基づいて異なるデータセットをグループ化するために使用されます。 私たちが話しているデータは多次元であり、多次元データセットで分類やクラスタリングを実行するのは簡単ではありません。 したがって、これを支援するために、PCAやLDAなどの次元削減手法が実行されます。これらはデータからの貴重な情報を失うことなくデータセットの次元を削減します。
シンプソンのパラドックスはデータにどのように影響しますか?
単変量の視覚化
単変量の視覚化は、基本的に、生のデータセット内のすべてのフィールドの確率分布であり、要約統計量が含まれます。 単変量の視覚化では、度数分布表、棒グラフ、ヒストグラム、または円グラフをグラフ表示に使用します。
二変量の視覚化
これらにより、データサイエンティストはデータセット内の変数間の関係を評価でき、見ている変数をターゲットにするのに役立ちます。 二変量解析の適切なグラフは、問題の変数のタイプによって異なります。 たとえば、2つの連続変数を扱っている場合は、散布図を選択する必要があります。 一方がカテゴリでもう一方が連続である場合は箱ひげ図が優先され、両方の変数がカテゴリである場合はモザイクプロットが選択されます。
データセキュリティのビジネスは活況を呈しています!
多変量の視覚化
多変量視覚化は、異なるデータフィールド間の相互作用を理解するのに役立ちます。 これには、任意の時点での複数の統計結果変数の観察と分析が含まれます。

K-meansクラスタリング
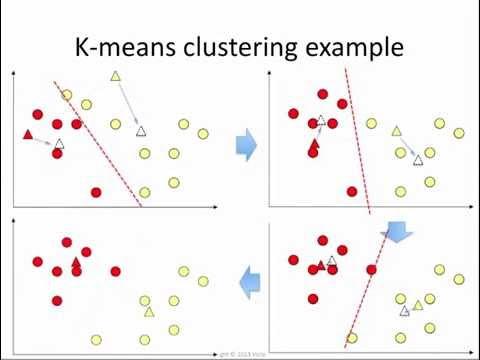
K-meansクラスタリングは、基本的に、最も近い平均に基づいて各クラスターの「中心」を作成するために使用されます。 これは、形成されたクラスターが反復によって変化しなくなるまで、クラスターの作成と再作成を継続する反復手法です。 データセット内の外れ値を見つけるために使用できます(クラスターの形式にならないポイントは、理想的には外れ値になります)。
予測モデル
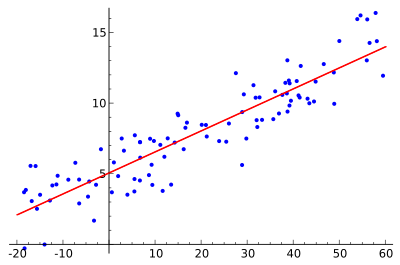
名前が示すように、予測モデリングは、統計を使用して結果を予測する方法です。 ほとんどの予測は、将来何が起こるかを予測することを目的としていますが、予測モデリングは、発生する可能性が高い時期に関係なく、未知のイベントにも適用できます。 たとえば、この手法を使用して、犯罪が発生した後でも、犯罪を検出し、容疑者を特定することができます。 予測モデリングを実行する最も一般的な方法は、線形回帰を使用することです(画像を参照)。
データウェアハウジングとデータマイニングの概要
探索的データ分析はビジネスにどのように役立ち、どこに適合しますか?
探索的データ分析は、科学者が生成した結果が正しく解釈されているかどうか、およびそれらが必要なビジネスコンテキストに適用されているかどうかを科学者が理解できるようにすることで、あらゆるビジネスに最大の価値を提供します。 探索的データ分析は、技術的に適切な結果を保証するだけでなく、質問が正しいかどうかを確認することで、利害関係者にもメリットをもたらします。 探索的データサイエンスは、多くの場合、予測できない洞察をもたらします。これは、利害関係者やデータサイエンティストが一般的に調査することすら気にしないものですが、それでもビジネスについて非常に有益であることが証明できます。
組織が探索的データ分析をビジネスインテリジェンスソフトウェアに直接組み込むのに役立つデータコネクタがいくつかあります。 また、BIデータを使用し、新しい情報がモデルに流入すると自動的に更新される統計モデルを(たとえば)Rで構築して実行することにより、データが逆方向に流れるように設定することもできます。
探索的データ分析の潜在的なユースケースは多岐にわたりますが、最終的にはすべてこれに要約されます。探索的データ分析とは、データについての仮定を立てる前に、またはその方向に何らかの措置を講じる前に、データを理解して理解することです。データマイニングの。 不正確なモデルを作成したり、間違ったデータに正確なモデルを構築したりすることを回避するのに役立ちます。
この手順を正しく実行すると、組織はデータに必要な自信を持てるようになり、最終的には強力な機械学習アルゴリズムの導入を開始できるようになります。 ただし、この重要なステップを無視すると、非常に不安定な基盤の上にビジネスインテリジェンスシステムを構築することになります。
データ分析をビジネス成果に結び付ける12の方法
結論は…
探索的データ分析は、知識抽出の全プロセスにおける重要なステップの1つであることは明らかです。 分析プロセス全体の強力な基盤を確立したい場合は、すべての力を集中して、EDAフェーズに集中する必要があります。 正直なところ、このステップを実行するには、少しの統計が必要です。 その面で遅れを感じている場合は、データサイエンスに必要な統計の基礎に関する記事を読むことを忘れないでください。
世界のトップ大学からオンラインでデータサイエンスコースを学びましょう。 エグゼクティブPGプログラム、高度な証明書プログラム、または修士プログラムを取得して、キャリアを早急に進めましょう。
Pythonの学習に興味があり、さまざまなツールやライブラリを手に入れたい場合は、データサイエンスのエグゼクティブPGプログラムをご覧ください。 ああ、そして「探索的データ分析」を科学よりも芸術として考えるという私たちの立場についてどう思いますか? 以下のコメントでお知らせください!
データサイエンティストがビジネスを改善するために探索的データ分析を使用する必要があるのはなぜですか?
探索的データ分析の主な目標は、仮定を行う前にデータの分析を支援することです。 これは、明らかなエラーの検出、データパターンのより良い理解、外れ値または予期しないイベントの検出、および変数間の興味深い相関関係の発見に役立ちます。
データサイエンティストは、探索的分析を使用して、生成する結果が正確であり、望ましいビジネスの結果と目標に対して受け入れられることを確認できます。 EDAはまた、利害関係者が適切な質問をしていることを確認することにより、利害関係者を支援します。 標準偏差、カテゴリ変数、および信頼区間はすべてEDAで回答できます。 EDAの完了と洞察の抽出に続いて、その機能を機械学習を含むより高度なデータ分析またはモデリングに適用できます。
EDAの最も一般的なユースケースは何ですか?
データサイエンティストが他のタイプのモデリングを結び付ける前にEDAを使用することは珍しいことではありません。 データ分析でデータセットを調べて、外れ値、傾向、パターン、エラーを特定するためによく使用されます。 たとえば、EDAは小売業で一般的に使用されており、BIツールと専門家がデータを分析して販売動向や上位カテゴリなどの洞察を明らかにします。また、EDAはヘルスケア研究でも使用され、市場や業界の新しい傾向を特定して、新しいインフルエンザシーズンに流行する可能性のあるインフルエンザ、患者集団の均一性の検証など。
探索的データ分析の種類は何ですか?
探索的データ分析の種類は次のとおりです。
1.単変量非グラフィカル:単変量非グラフィカルEDAの標準的な目的は、サンプルの分布/データを理解し、母集団を観察することです。
2.単変量グラフィカル:ヒストグラム、幹葉図、箱ひげ図など。
3.多変量非グラフィカル:これらのEDA手法は、クロス集計表または統計を使用して、2つ以上のデータ変数間の関係を示します。
4.多変量グラフィカル:2つ以上のタイプのデータ間の関係のグラフィカル表現が多変量データで使用されます。