
Explorative Datenanalyse und ihre Bedeutung für Ihr Unternehmen
Veröffentlicht: 2018-02-22Die meisten Diskussionen über Datenanalyse befassen sich mit dem „wissenschaftlichen“ Aspekt davon. Sicher steckt viel Wissenschaft hinter dem ganzen Prozess – den Algorithmen, Formeln und Berechnungen, aber man kann ihm die „Kunst“ nicht nehmen. Die Strukturierung des gesamten Prozesses – von der Planung der Analyse bis hin zur Sinngebung des Endergebnisses – ist keine leichte Aufgabe und nicht weniger als eine Kunstform. Genau das gehört zu unserem Tagesthema – Explorative Datenanalyse. In diesem Artikel sehen wir uns an, was explorative Datenanalyse ist, was die gängigen Tools und Techniken dafür sind und wie sie einer Organisation helfen.
Inhaltsverzeichnis
Was ist explorative Datenanalyse?
Die explorative Datenanalyse ist einer der wichtigsten Schritte im Datenanalyseprozess. Hier liegt der Schwerpunkt darauf, die vorhandenen Daten zu verstehen – Dinge wie die Formulierung der richtigen Fragen, die Sie an Ihren Datensatz stellen müssen, wie Sie die Datenquellen manipulieren, um die erforderlichen Antworten zu erhalten, und andere. Dazu werden Trends, Muster und Ausreißer mit einer visuellen Methode ausführlich betrachtet. 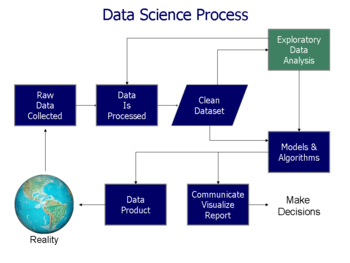
Die explorative Datenanalyse ist ein entscheidender Schritt, bevor Sie zum maschinellen Lernen oder zur Modellierung Ihrer Daten übergehen. Es liefert den notwendigen Kontext, um ein geeignetes Modell zu entwickeln – und die Ergebnisse richtig zu interpretieren.
Datenmanipulation: Wie erkennt man Datenlügen?
Im Laufe der Jahre hat maschinelles Lernen zugenommen – und das hat eine Reihe leistungsstarker Algorithmen für maschinelles Lernen hervorgebracht. So mächtig, dass sie Sie fast dazu verleiten, die Phase der explorativen Datenanalyse zu überspringen. Obwohl es verständlich ist, warum Sie solche Algorithmen nutzen und die EDA überspringen möchten, ist es keine sehr gute Idee, Daten einfach in eine Blackbox einzuspeisen und auf die Ergebnisse zu warten. Es wurde immer wieder beobachtet, dass die explorative Datenanalyse viele wichtige Informationen liefert, die sehr leicht zu übersehen sind – Informationen, die der Analyse langfristig helfen, von der Formulierung von Fragen bis zur Anzeige von Ergebnissen. Wenn Sie Anfänger sind und mehr über Data Science erfahren möchten, sehen Sie sich unsere Data Science-Schulungen von Top-Universitäten an.
Während die Aspekte von EDA existieren, seit wir Daten zu analysieren haben, wurde die explorative Datenanalyse offiziell bereits in den 1970er Jahren von John Turkey entwickelt – dem gleichen Wissenschaftler, der das Wort „Bit“ (kurz für Binary Digit) geprägt hat. EDA wird oft mehr als Philosophie denn als Wissenschaft gesehen und beschrieben, weil es keine festen Regeln gibt, wie man sich ihr nähert. Der Zweck der explorativen Datenanalyse ist wesentlich, um bestimmte Aufgaben zu bewältigen, wie zum Beispiel:
- Erkennen fehlender und fehlerhafter Daten;
- Abbildung und Verständnis der zugrunde liegenden Struktur Ihrer Daten;
- Identifizieren der wichtigsten Variablen in Ihrem Datensatz;
- Testen einer Hypothese oder Überprüfen von Annahmen in Bezug auf ein bestimmtes Modell;
- Erstellung eines sparsamen Modells (eines, das Ihre Daten mit minimalen Variablen erklären kann);
- Schätzen von Parametern und Berechnen der Fehlermargen.
Tools und Techniken, die in der explorativen Datenanalyse verwendet werden
S-Plus und R sind die wichtigsten statistischen Programmiersprachen, die zur Durchführung der explorativen Datenanalyse verwendet werden. Diese Sprachen werden mit einer Fülle von Tools geliefert, die Ihnen helfen, bestimmte statistische Funktionen auszuführen, wie z.
Klassifikations- und Dimensionsreduktionstechniken
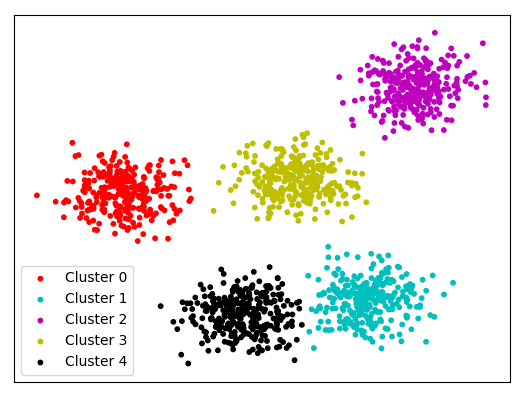
Die Klassifizierung wird im Wesentlichen verwendet, um verschiedene Datensätze auf der Grundlage eines gemeinsamen Parameters/einer gemeinsamen Variable zusammenzufassen. Die Daten, über die wir sprechen, sind mehrdimensional, und es ist nicht einfach, eine Klassifizierung oder ein Clustering für einen mehrdimensionalen Datensatz durchzuführen. Um dies zu unterstützen, werden daher Dimensionalitätsreduktionstechniken wie PCA und LDA durchgeführt – diese reduzieren die Dimensionalität des Datensatzes, ohne wertvolle Informationen aus Ihren Daten zu verlieren.
Wie wirkt sich das Simpson-Paradoxon auf Daten aus?
Univariate Visualisierung
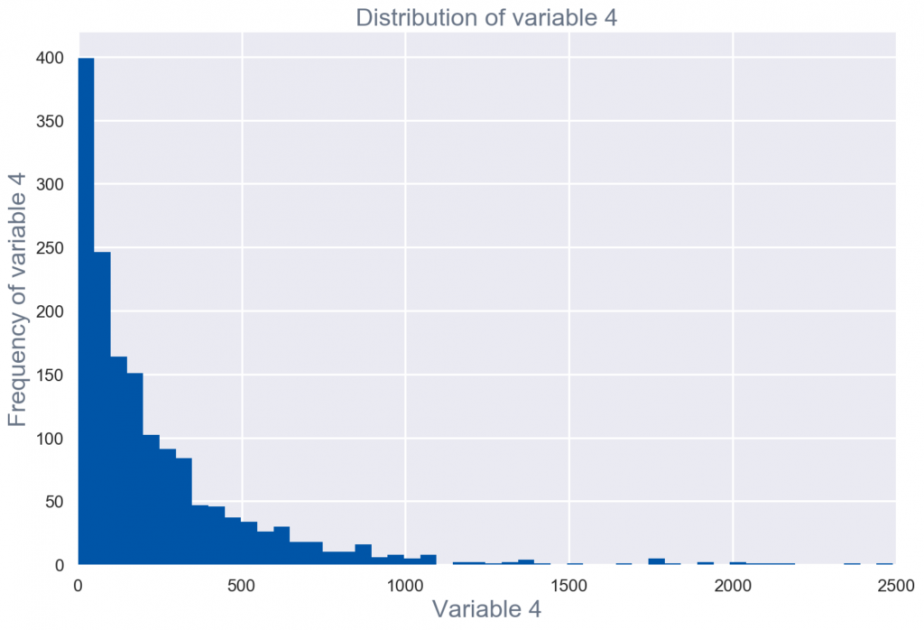
Univariate Visualisierungen sind im Wesentlichen Wahrscheinlichkeitsverteilungen jedes einzelnen Felds im Rohdatensatz – mit zusammenfassenden Statistiken. Univariate Visualisierungen verwenden für die grafische Darstellung Häufigkeitsverteilungstabellen, Balkendiagramme, Histogramme oder Tortendiagramme.
Bivariate Visualisierungen
Diese ermöglichen es den Data Scientists, die Beziehung zwischen Variablen in Ihrem Datensatz zu bewerten – und helfen Ihnen, die Variable, die Sie betrachten, gezielt zu bestimmen. Geeignete Grafiken für die bivariate Analyse hängen von der Art der betreffenden Variablen ab. Wenn Sie es beispielsweise mit zwei kontinuierlichen Variablen zu tun haben, sollte ein Streudiagramm das Diagramm Ihrer Wahl sein. Wenn eine kategorial und die andere kontinuierlich ist, wird ein Boxplot bevorzugt, und wenn beide Variablen kategorial sind, wird ein Mosaikplot gewählt.
Das Geschäft mit der Datensicherheit boomt!
Multivariate Visualisierungen
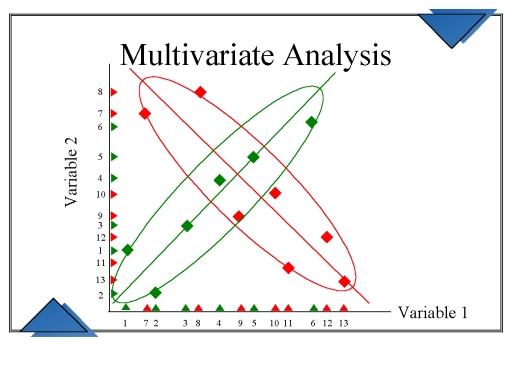
Multivariate Visualisierungen helfen dabei, die Wechselwirkungen zwischen verschiedenen Datenfeldern zu verstehen. Es beinhaltet die Beobachtung und Analyse von mehr als einer statistischen Ergebnisvariablen zu einem bestimmten Zeitpunkt.

K-bedeutet Clustering
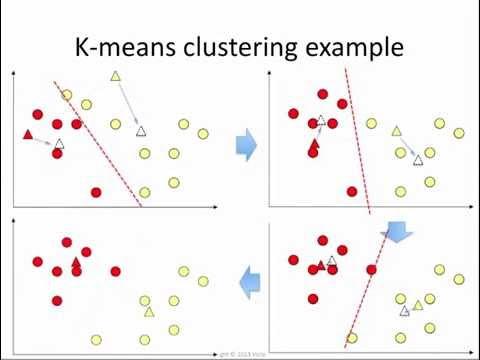
K-Means-Clustering wird im Wesentlichen verwendet, um „Zentren“ für jeden Cluster basierend auf dem nächsten Mittelwert zu erstellen. Es ist eine iterative Technik, die Cluster erstellt und neu erstellt – bis sich die gebildeten Cluster nicht mehr durch Iterationen ändern. Es kann verwendet werden, um Ausreißer in einem Datensatz zu finden (Punkte, die keine Form von Clustern darstellen, sind idealerweise Ausreißer).
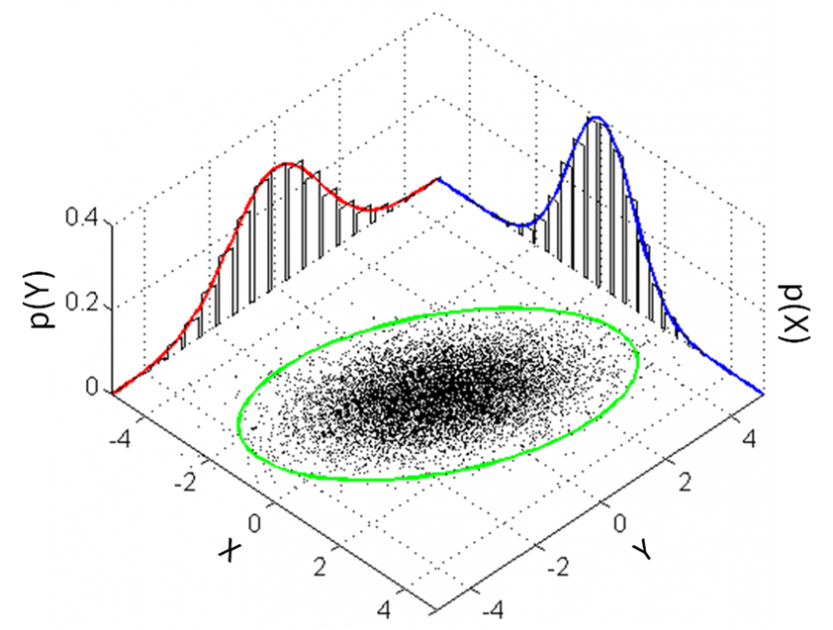
Vorhersagemodelle
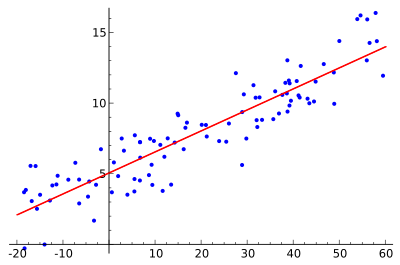
Wie der Name schon sagt, ist die Vorhersagemodellierung eine Methode, die Statistiken verwendet, um Ergebnisse vorherzusagen. Obwohl die meisten Vorhersagen darauf abzielen, vorherzusagen, was in der Zukunft passieren wird, kann die Vorhersagemodellierung auch auf jedes unbekannte Ereignis angewendet werden, unabhängig davon, wann es wahrscheinlich eintritt. Diese Technik kann zum Beispiel verwendet werden, um Verbrechen aufzudecken und Verdächtige zu identifizieren, selbst nachdem das Verbrechen passiert ist. Die gebräuchlichste Methode zur Durchführung von Vorhersagemodellen ist die Verwendung der linearen Regression (siehe Abbildung).
Das Was ist was von Data Warehousing und Data Mining
Wie hilft die explorative Datenanalyse Ihrem Unternehmen und wo passt sie hinein?
Die explorative Datenanalyse ist für jedes Unternehmen von größtem Wert, indem sie Wissenschaftlern hilft zu verstehen, ob die von ihnen produzierten Ergebnisse richtig interpretiert werden und ob sie auf die erforderlichen Geschäftskontexte zutreffen. Neben der Sicherstellung technisch fundierter Ergebnisse profitiert die explorative Datenanalyse auch von Stakeholdern, indem sie bestätigt, ob die von ihnen gestellten Fragen richtig sind oder nicht. Explorative Data Science liefert oft unvorhersehbare Erkenntnisse – solche, die die Stakeholder oder Data Scientists im Allgemeinen nicht einmal untersuchen möchten, die sich aber dennoch als sehr aufschlussreich für das Geschäft erweisen können.
Es gibt eine Reihe von Datenkonnektoren , mit denen Unternehmen die explorative Datenanalyse direkt in ihre Business-Intelligence-Software integrieren können. Sie können dies auch so einrichten, dass Daten auch in die andere Richtung fließen können, indem Sie statistische Modelle (z. B.) in R erstellen und ausführen, die BI-Daten verwenden und automatisch aktualisiert werden, wenn neue Informationen in das Modell einfließen.
Die möglichen Anwendungsfälle der explorativen Datenanalyse sind vielfältig, aber letztendlich läuft alles darauf hinaus – bei der explorativen Datenanalyse geht es darum, Ihre Daten kennenzulernen und zu verstehen, bevor Sie Annahmen darüber treffen oder Schritte in die Richtung unternehmen des Data-Mining. Es hilft Ihnen, das Erstellen ungenauer Modelle oder das Erstellen genauer Modelle auf der Grundlage falscher Daten zu vermeiden.
Die richtige Ausführung dieses Schritts gibt jeder Organisation das nötige Vertrauen in ihre Daten – was es ihnen schließlich ermöglicht, mit der Bereitstellung leistungsstarker Algorithmen für maschinelles Lernen zu beginnen. Das Ignorieren dieses entscheidenden Schritts kann jedoch dazu führen, dass Sie Ihr Business Intelligence System auf einem sehr wackeligen Fundament aufbauen.
12 Möglichkeiten, Datenanalysen mit Geschäftsergebnissen zu verbinden
Abschließend…
Die explorative Datenanalyse ist ganz klar einer der wichtigen Schritte während des gesamten Prozesses der Wissensextraktion. Wenn Sie ein starkes Fundament für Ihren gesamten Analyseprozess schaffen wollen, sollten Sie sich mit aller Kraft und Kraft auf die EDA-Phase konzentrieren. Um ehrlich zu sein, ist ein bisschen Statistik erforderlich, um diesen Schritt zu meistern. Wenn Sie das Gefühl haben, dass Sie an dieser Front hinterherhinken, vergessen Sie nicht, unseren Artikel über die Grundlagen der Statistik für Data Science zu lesen.
Lernen Sie Data Science-Kurse online von den besten Universitäten der Welt. Verdienen Sie Executive PG-Programme, Advanced Certificate-Programme oder Master-Programme, um Ihre Karriere zu beschleunigen.
Wenn Sie daran interessiert sind, Python zu lernen und sich mit verschiedenen Tools und Bibliotheken vertraut machen möchten, sehen Sie sich das Executive PG Program in Data Science an. Oh, und was denkst du über unseren Standpunkt, „Explorative Datenanalyse“ eher als Kunst denn als Wissenschaft zu betrachten? Lass es uns in den Kommentaren unten wissen!
Warum sollte ein Data Scientist die explorative Datenanalyse nutzen, um Ihr Unternehmen zu verbessern?
Das Hauptziel der explorativen Datenanalyse besteht darin, die Analyse von Daten zu unterstützen, bevor Annahmen getroffen werden. Es kann bei der Erkennung offensichtlicher Fehler, einem besseren Verständnis von Datenmustern, der Erkennung von Ausreißern oder unerwarteten Ereignissen und der Entdeckung interessanter Korrelationen zwischen Variablen helfen.
Data Scientists können explorative Analysen einsetzen, um sicherzustellen, dass die von ihnen produzierten Ergebnisse genau und für alle gewünschten Geschäftsergebnisse und -ziele akzeptabel sind. Die EDA unterstützt auch Interessengruppen, indem sie sicherstellt, dass sie die richtigen Fragen stellen. Standardabweichungen, kategoriale Variablen und Konfidenzintervalle können alle mit EDA beantwortet werden. Nach dem Abschluss von EDA und der Gewinnung von Erkenntnissen können seine Funktionen für eine fortgeschrittenere Datenanalyse oder Modellierung, einschließlich maschinellem Lernen, angewendet werden.
Was sind die beliebtesten Anwendungsfälle für EDA?
Es ist nicht ungewöhnlich, dass Datenwissenschaftler EDA verwenden, bevor sie andere Arten der Modellierung anbinden. Es wird häufig in der Datenanalyse verwendet, um Datensätze zu untersuchen, um Ausreißer, Trends, Muster und Fehler zu identifizieren. Beispielsweise wird EDA häufig im Einzelhandel verwendet, wo BI-Tools und Experten Daten analysieren, um Einblicke in Verkaufstrends, Top-Kategorien usw. zu gewinnen. EDA wird auch in der Gesundheitsforschung verwendet, um neue Trends auf einem Markt oder in einer Branche zu identifizieren und Belastungen zu bestimmen Grippe, die in der neuen Grippesaison häufiger auftreten könnte, Überprüfung der Homogenität der Patientenpopulation usw.
Welche Arten der explorativen Datenanalyse gibt es?
Die Arten der explorativen Datenanalyse sind
1. Univariate nichtgrafische: Der Standardzweck der univariaten nichtgrafischen EDA besteht darin, die Stichprobenverteilung/-daten zu verstehen und Populationsbeobachtungen durchzuführen.
2. Univariate Grafik: Histogramme, Stem-and-Leaf-Plots, Box-Plots usw.
3. Multivariat Nicht-grafisch: Diese EDA-Techniken verwenden Kreuztabellen oder Statistiken, um die Beziehung zwischen zwei oder mehr Datenvariablen darzustellen.
4. Multivariate Grafik: Grafische Darstellungen von Beziehungen zwischen zwei oder mehr Datentypen werden in multivariaten Daten verwendet.