
探索性數據分析及其對您業務的重要性
已發表: 2018-02-22大多數關於數據分析的討論都涉及它的“科學”方面。 當然,整個過程背後有很多科學——算法、公式和計算,但你不能把“藝術”從它帶走。 構建整個過程——從計劃分析到理解最終結果——絕非易事,而且不亞於一種藝術形式。 這正是我們今天的主題——探索性數據分析。 在本文中,我們將探討什麼是探索性數據分析,它的常用工具和技術是什麼,以及它如何幫助組織。
目錄
什麼是探索性數據分析?
探索性數據分析是數據分析過程中的重要步驟之一。 在這裡,重點是理解手頭的數據——比如製定正確的問題來詢問你的數據集,如何操作數據源以獲得所需的答案等等。 這是通過使用視覺方法仔細查看趨勢、模式和異常值來完成的。 
在您開始機器學習或數據建模之前,探索性數據分析是至關重要的一步。 它提供了開發適當模型所需的背景 - 並正確解釋結果。
數據操縱:如何發現數據謊言?
多年來,機器學習一直在興起——這催生了許多強大的機器學習算法。 如此強大,它們幾乎會誘使您跳過探索性數據分析階段。 雖然您可以理解為什麼要利用此類算法並跳過 EDA - 將數據輸入黑匣子並等待結果並不是一個好主意。 一次又一次地觀察到,探索性數據分析提供了許多很容易錯過的關鍵信息——從提出問題到顯示結果的從長遠來看有助於分析的信息。 如果您是初學者並且有興趣了解有關數據科學的更多信息,請查看我們來自頂尖大學的數據科學培訓。
雖然只要我們有數據要分析,EDA 的各個方面就已經存在,探索性數據分析正式由約翰·土耳其在 1970 年代開發——同一位科學家創造了“比特”(Binary Digit 的縮寫)這個詞。 EDA 經常被視為一種哲學,而不是科學,因為它沒有硬性規定。 探索性數據分析的目的對於解決特定任務至關重要,例如:
- 發現缺失和錯誤的數據;
- 映射和理解數據的底層結構;
- 識別數據集中最重要的變量;
- 檢驗與特定模型相關的假設或檢查假設;
- 建立一個簡約的模型(一個可以用最小變量解釋你的數據的模型);
- 估計參數併計算誤差範圍。
探索性數據分析中使用的工具和技術
S-Plus 和 R 是用於執行探索性數據分析的最重要的統計編程語言。 這些語言捆綁了大量工具,可幫助您執行特定的統計功能,例如:
分類和降維技術
分類本質上是用來根據一個共同的參數/變量將不同的數據集組合在一起。 我們說的數據是多維的,對多維的數據集進行分類或聚類並不容易。 因此,為了解決這個問題,執行了 PCA 和 LDA 等降維技術——這些技術可以降低數據集的維度,而不會丟失數據中任何有價值的信息。
辛普森悖論如何影響數據?
單變量可視化
單變量可視化本質上是原始數據集中每個字段的概率分佈——帶有匯總統計。 單變量可視化使用頻率分佈表、條形圖、直方圖或餅圖進行圖形表示。
雙變量可視化
這些使數據科學家能夠評估數據集中變量之間的關係,並幫助您定位正在查看的變量。 雙變量分析的適當圖表取決於相關變量的類型。 例如,如果您正在處理兩個連續變量,散點圖應該是您選擇的圖形。 如果一個是分類的而另一個是連續的,則首選箱線圖,當兩個變量都是分類時,則選擇馬賽克圖。
數據安全業務正在蓬勃發展!
多元可視化
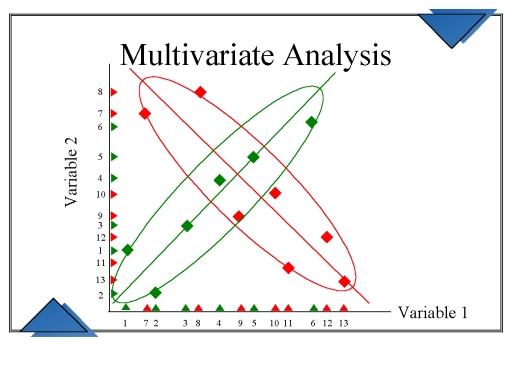
多元可視化有助於理解不同數據字段之間的交互。 它涉及在任何給定時間對多個統計結果變量的觀察和分析。

K-means 聚類
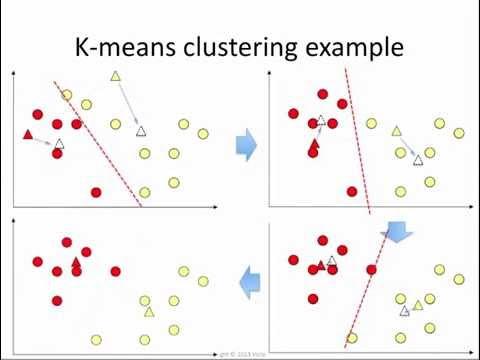
K-means 聚類基本上用於根據最接近的均值為每個聚類創建“中心”。 這是一種不斷創建和重新創建集群的迭代技術——直到形成的集群不再隨迭代而變化。 它可用於查找數據集中的異常值(理想情況下,不是任何集群形式的點將是異常值)。
預測模型
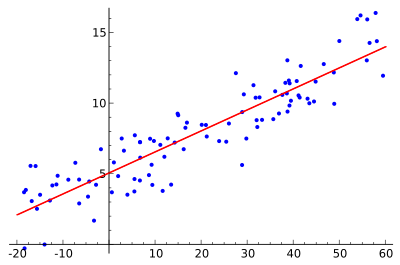
顧名思義,預測建模是一種使用統計數據來預測結果的方法。 儘管大多數預測旨在預測未來會發生什麼,但預測建模也可以應用於任何未知事件,無論它何時可能發生。 例如,即使在犯罪發生後,這種技術也可用於偵查犯罪並識別嫌疑人。 執行預測建模的最常見方法是使用線性回歸(見圖)。
什麼是數據倉庫和數據挖掘
探索性數據分析如何幫助您的業務以及它適用於何處?
探索性數據分析通過幫助科學家了解他們產生的結果是否得到正確解釋以及它們是否適用於所需的業務環境,從而為任何業務提供最大價值。 除了確保技術上合理的結果之外,探索性數據分析還可以通過確認他們提出的問題是否正確來使利益相關者受益。 探索性數據科學通常會出現不可預測的見解——利益相關者或數據科學家通常甚至不會關心調查,但仍然可以證明對業務有高度的信息。
有許多數據連接器可以幫助組織將探索性數據分析直接整合到他們的商業智能軟件中。 您還可以通過在(例如)R 中構建和運行使用 BI 數據並在新信息流入模型時自動更新的統計模型來設置它以允許數據也以另一種方式流動。
探索性數據分析的潛在用例範圍很廣,但歸根結底,這一切都歸結為 - 探索性數據分析就是在對數據做出任何假設或採取任何措施之前了解和理解您的數據數據挖掘。 它可以幫助您避免創建不准確的模型或在錯誤的數據上構建準確的模型。
正確執行此步驟將使任何組織對他們的數據有必要的信心——這最終將使他們能夠開始部署強大的機器學習算法。 但是,忽略這一關鍵步驟可能會導致您在非常不穩定的基礎上構建您的商業智能係統。
將數據分析與業務成果聯繫起來的 12 種方法
綜上所述…
探索性數據分析顯然是整個知識提取過程中的重要步驟之一。 如果你想為你的整體分析過程打下堅實的基礎,你應該全力以赴地專注於 EDA 階段。 老實說,要完成這一步,需要一些統計數據。 如果您覺得自己在這方面落後了,請不要忘記閱讀我們關於數據科學所需的統計基礎的文章。
從世界頂級大學在線學習數據科學課程。 獲得行政 PG 課程、高級證書課程或碩士課程,以加快您的職業生涯。
如果您有興趣學習 python 並想親身體驗各種工具和庫,請查看數據科學中的 Executive PG Program。 哦,您對我們將“探索性數據分析”視為一門藝術而非科學的立場有何看法? 在下面的評論中讓我們知道!
為什麼數據科學家應該使用探索性數據分析來改善您的業務?
探索性數據分析的主要目標是在做出任何假設之前協助數據分析。 它可以幫助檢測明顯的錯誤、更好地理解數據模式、檢測異常值或意外事件,以及發現變量之間有趣的相關性。
數據科學家可以採用探索性分析來確保他們產生的結果是準確的,並且對於任何期望的業務成果和目標都是可接受的。 EDA 還通過確保利益相關者提出適當的問題來幫助他們。 標準偏差、分類變量和置信區間都可以用 EDA 來回答。 在完成 EDA 並提取見解後,其功能可應用於更高級的數據分析或建模,包括機器學習。
EDA 最流行的用例是什麼?
數據科學家在綁定其他類型的建模之前使用 EDA 並不少見。 它通常用於數據分析,以查看數據集以識別異常值、趨勢、模式和錯誤。 例如,EDA 常用於零售業,其中 BI 工具和專家分析數據以揭示銷售趨勢、熱門類別等方面的洞察力,EDA 還用於醫療保健研究,以識別市場或行業的新趨勢,確定壓力在新的流感季節可能會更加流行的流感,驗證患者群體的同質性等。
探索性數據分析有哪些類型?
探索性數據分析的類型是
1. 單變量非圖形:單變量非圖形 EDA 的標準目的是了解樣本分佈/數據並進行總體觀察。
2. 單變量圖形:直方圖、莖葉圖、箱線圖等。
3. 多變量非圖形:這些 EDA 技術使用交叉製表或統計來描述兩個或多個數據變量之間的關係。
4. 多元圖形:在多元數據中使用兩種或多種數據類型之間關係的圖形表示。