
Структуры данных и алгоритм в Python: все, что вам нужно знать
Опубликовано: 2020-05-06Структуры данных и алгоритмы в Python — две из самых фундаментальных концепций информатики. Они являются незаменимыми инструментами для любого программиста. Структуры данных в Python связаны с организацией и хранением данных в памяти, пока программа их обрабатывает. С другой стороны, алгоритмы Python относятся к подробному набору инструкций, которые помогают в обработке данных для определенной цели.
С другой стороны, можно сказать, что разные структуры данных логически используются алгоритмами для решения конкретной задачи анализа данных. Будь то реальная проблема или типичный вопрос, связанный с кодированием, понимание структур данных и алгоритмов в Python имеет решающее значение, если вы хотите найти точное решение. В этой статье вы найдете подробное обсуждение различных алгоритмов и структур данных Python. Если вам интересно узнать больше о Python, ознакомьтесь с нашими курсами по науке о данных .
Подробнее: Шесть наиболее часто используемых структур данных в R
Оглавление
Что такое структуры данных в Python?
Структуры данных — это способ организации и хранения данных; они объясняют взаимосвязь между данными и различными логическими операциями, которые можно выполнять над данными. Существует множество способов классификации структур данных. Один из способов — разделить их на примитивные и непримитивные типы данных.
В то время как примитивные типы данных включают целые числа, числа с плавающей запятой, строки и логические значения, непримитивными типами данных являются массив, список, кортежи, словарь, наборы и файлы. Некоторые из этих непримитивных типов данных, такие как список, кортежи, словари и наборы, встроены в Python. В Python есть еще одна категория структур данных, определяемая пользователем; то есть пользователи определяют их. К ним относятся Stack, Queue, Linked List, Tree, Graph и HashMap.
Примитивные структуры данных
Это основные структуры данных в Python, содержащие чистые и простые значения данных, которые служат строительными блоками для манипулирования данными. Давайте поговорим о четырех примитивных типах переменных в Python:
- Целые числа — этот тип данных используется для представления числовых данных, то есть положительных или отрицательных целых чисел без десятичной точки. Скажем, -1, 3 или 6.
- Float — Float означает «действительное число с плавающей запятой». Он используется для представления рациональных чисел, обычно содержащих десятичную точку, например 2,0 или 5,77. Поскольку Python — это язык программирования с динамической типизацией, тип данных, которые хранит объект, является изменяемым, и нет необходимости явно указывать тип вашей переменной.
- Строка — этот тип данных обозначает набор алфавитов, слов или буквенно-цифровых символов. Он создается путем включения ряда символов в пару двойных или одинарных кавычек. Чтобы объединить две или более строк, к ним можно применить операцию «+». Повторение, сращивание, использование заглавных букв и извлечение — вот некоторые из других операций со строками в Python. Пример: «синий», «красный» и т. д.
- Boolean — этот тип данных полезен в сравнениях и условных выражениях и может принимать значения TRUE или FALSE.
Узнайте больше: Фреймы данных в Python
Встроенные непримитивные структуры данных
В отличие от примитивных структур данных, непримитивные типы данных хранят не только значения, но и набор значений в разных форматах. Давайте посмотрим на непримитивные структуры данных в Python:
- Списки — это наиболее универсальная структура данных в Python, которая записывается в виде списка элементов, разделенных запятыми, заключенных в квадратные скобки. Список может состоять как из разнородных, так и из однородных элементов. Некоторые из методов, применимых к списку, — это index(), append(), extend(), insert(), remove(), pop() и т. д. Списки изменяемы; то есть их содержимое можно изменить, сохранив при этом идентичность.
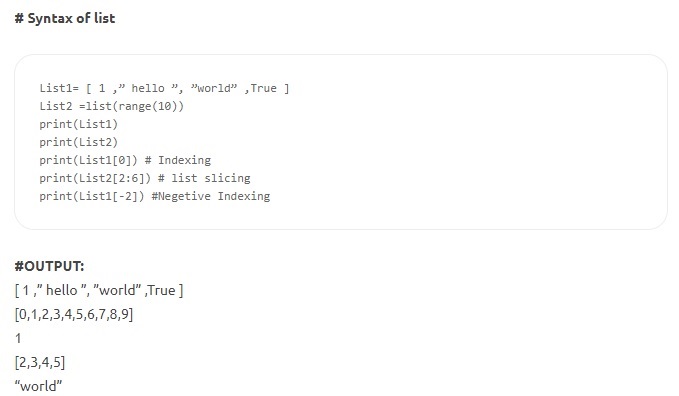
Источник
- Кортежи — кортежи похожи на списки, но неизменяемы. Кроме того, в отличие от списков, кортежи объявляются в круглых скобках, а не в квадратных. Функция неизменяемости означает, что после определения элемента в кортеже его нельзя удалить, переназначить или отредактировать. Это гарантирует, что объявленные значения структуры данных не будут изменены или переопределены.
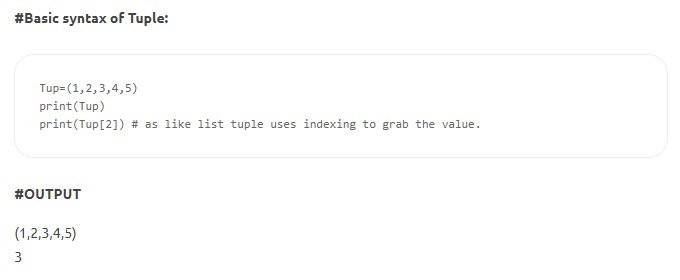
Источник
- Словари . Словари состоят из пар ключ-значение. «Ключ» идентифицирует элемент, а «значение» хранит значение элемента. Двоеточие отделяет ключ от его значения. Элементы разделяются запятыми, а все содержимое заключено в фигурные скобки. Хотя ключи неизменяемы (числа, строки или кортежи), значения могут быть любого типа.
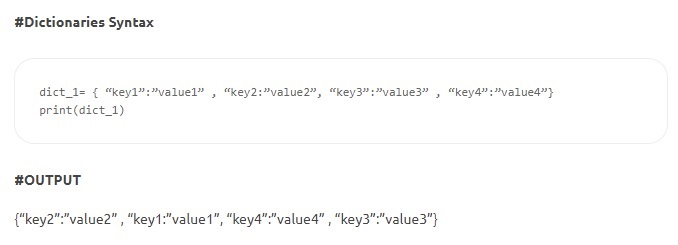
Источник
- Наборы . Наборы представляют собой неупорядоченный набор уникальных элементов. Как и списки, наборы изменяемы и записываются в квадратных скобках, но два значения не могут быть одинаковыми. Некоторые методы Set включают count(), index(), any(), all() и т. д.
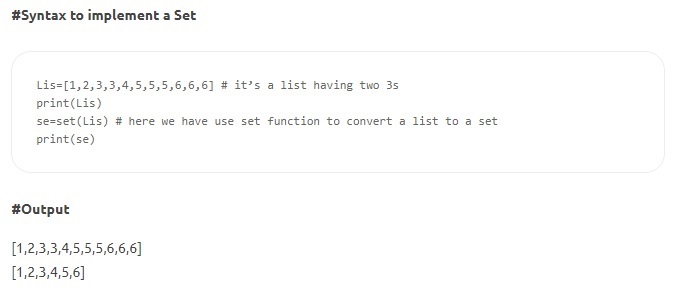
Источник
- Списки против массивов . В Python нет встроенной концепции массивов. Массивы можно импортировать с помощью пакета NumPy перед их инициализацией. Чтобы узнать больше о NumPy, вы можете ознакомиться с нашим руководством по Python NumPy . Списки и массивы в основном похожи, за исключением одного отличия: в то время как массивы представляют собой наборы только однородных элементов, списки включают как однородные, так и разнородные элементы.
Оформить заказ: типы бинарного дерева
Пользовательские структуры данных в Python
Следующим в нашем обсуждении структур данных и алгоритмов в Python является краткий обзор различных определяемых пользователем структур данных:
- Стеки. Стеки — это линейные структуры данных в Python. Хранение элементов в стеках основано на принципах «первым пришел — последним вышел» (FILO) или «последним пришел — первым ушел» (LIFO). В стеках добавление нового элемента на одном конце сопровождается удалением элемента на том же конце. Операции push и pop используются для вставки и удаления соответственно. Другими функциями, связанными со стеком, являются empty(), size() и top(). Стеки могут быть реализованы с использованием модулей и структур данных из библиотеки Python — list, collections.deque и queue.LifoQueue.
- Очереди . Как и стеки, очереди представляют собой линейные структуры данных. Однако товары хранятся по принципу «первым пришел – первым обслужен» (FIFO). В очереди элемент, добавленный последним, удаляется первым. Операции, связанные с Queue, включают Enqueue (добавление элементов), Dequeue (удаление элементов), Front и Rear. Как и стеки, очереди могут быть реализованы с использованием модулей и структур данных из библиотеки Python — списка, collections.deque и очереди.
- Дерево . Деревья представляют собой нелинейные структуры данных в Python и состоят из узлов, соединенных ребрами. Свойства дерева таковы, что один узел назначается корневым узлом, отличным от корня, каждый другой узел имеет связанный родительский узел, и каждый узел может иметь произвольное количество дочерних узлов. Структура данных двоичного дерева — это структура, элементы которой имеют не более двух дочерних элементов.
- Связанный список . Ряд элементов данных, соединенных вместе с помощью ссылок, в Python называется связанным списком. Это также линейная структура данных. Каждый элемент данных в связанном списке связан с другим с помощью указателя. Поскольку библиотека Python не содержит связанных списков, они реализованы с использованием концепции узлов. Связанные списки имеют преимущество перед массивами в динамическом размере и простоте вставки/удаления элементов.
- График — график в Python графически представляет набор объектов, некоторые пары объектов соединены ссылками. Вершины представляют объекты, которые связаны между собой, а связи, соединяющие вершины, называются ребрами. Тип данных словаря Python можно использовать для представления графиков. По сути, «ключи» словаря представляют собой вершины, а «значения» указывают соединения или ребра между вершинами.
- HashMaps/Hash Tables — в этом типе структуры данных хэш-функция генерирует адрес или значение индекса элемента данных. Значение индекса служит ключом к значению данных, обеспечивая более быстрый доступ к данным. Как и в случае типа данных словаря, в хеш-таблицах есть пары ключ-значение, но ключ генерируется функцией хеширования.
Что такое алгоритмы в Python?
Алгоритмы Python — это набор инструкций, которые выполняются для получения решения данной проблемы. Поскольку алгоритмы не зависят от языка, они могут быть реализованы на нескольких языках программирования. Нет стандартных правил, регулирующих написание алгоритмов. Они зависят от ресурсов и проблем, но имеют некоторые общие конструкции кода, такие как управление потоком (if-else) и циклы (do, while, for). В следующих разделах мы кратко обсудим алгоритмы обхода дерева, сортировки, поиска и графов.

Алгоритмы обхода дерева
Обход — это процесс посещения всех узлов Дерева, начиная с корневого узла. Дерево можно обойти тремя различными способами:
- Обход по порядку включает сначала посещение левого поддерева, затем корня, а затем правого поддерева.
- При обходе в прямом порядке первым посещается корневой узел, за ним следует левое поддерево и, наконец, правое поддерево.
- В алгоритме обхода в обратном порядке сначала посещается левое поддерево, затем правое поддерево, причем корневой узел посещается последним.
Узнайте больше: Как создать идеальное дерево решений
Алгоритмы сортировки
Алгоритмы сортировки обозначают способы упорядочивания данных в определенном формате. Сортировка обеспечивает высокую оптимизацию поиска данных и представление данных в удобочитаемом формате. Давайте посмотрим на пять различных типов алгоритмов сортировки в Python:
- Пузырьковая сортировка . Этот алгоритм основан на сравнении, при котором происходит повторная замена соседних элементов, если они расположены в неправильном порядке.
- Сортировка слиянием — основанная на алгоритме «разделяй и властвуй», сортировка слиянием делит массив на две половины, сортирует их, а затем объединяет.
- Сортировка вставками. Эта сортировка начинается со сравнения и сортировки первых двух элементов. Затем третий элемент сравнивается с двумя ранее отсортированными элементами и так далее.
- Сортировка Шелла — это разновидность сортировки вставками, но здесь сортируются удаленные элементы. Большой подсписок данного списка сортируется, и размер списка постепенно уменьшается до тех пор, пока не будут отсортированы все элементы.
- Сортировка выбором . Этот алгоритм начинается с поиска минимального значения из списка элементов и помещения его в отсортированный список. Затем процесс повторяется для каждого из оставшихся элементов в несортированном списке. Новый элемент, входящий в отсортированный список, сравнивается с его существующими элементами и помещается в правильное положение. Процесс продолжается до тех пор, пока все элементы не будут отсортированы.
Алгоритмы поиска
Алгоритмы поиска помогают проверять и извлекать элемент из разных структур данных. Один тип алгоритма поиска применяет метод последовательного поиска, при котором список последовательно просматривается и проверяется каждый элемент (линейный поиск). В другом типе, интервальном поиске, элементы ищутся в отсортированных структурах данных (бинарный поиск). Давайте посмотрим на некоторые из примеров:
- Линейный поиск — в этом алгоритме каждый элемент последовательно ищется один за другим.
- Бинарный поиск — интервал поиска многократно делится пополам. Если искомый элемент находится ниже центрального компонента интервала, интервал сужается до нижней половины. В противном случае он сужается к верхней половине. Процесс повторяется до тех пор, пока значение не будет найдено.
Алгоритмы графов
Существует два метода обхода графов по их ребрам. Эти:
- Обход в глубину (DFS) — в этом алгоритме граф обходится в движении вглубь. Когда какая-либо итерация заходит в тупик, для перехода к следующей вершине и начала поиска используется стек. DFS реализована на Python с использованием заданных типов данных.
- Обход в ширину (BFS) — в этом алгоритме граф проходится в ширину. Когда какая-либо итерация заходит в тупик, используется очередь для перехода к следующей вершине и начала поиска. BFS реализована на Python с использованием структуры данных очереди.
Алгоритм анализа
- Априорный анализ — представляет собой теоретический анализ алгоритма перед его реализацией. Эффективность алгоритма измеряется в предположении, что такие факторы, как скорость процессора, постоянны и не влияют на алгоритм.
- Апостериорный анализ — относится к эмпирическому анализу алгоритма после его реализации. Язык программирования используется для реализации выбранного алгоритма с последующим его выполнением на компьютере. Этот анализ собирает статистику, такую как время и пространство, необходимые для запуска алгоритма.
Заключение
Независимо от того, являетесь ли вы ветераном программирования или новичком, вы не можете игнорировать структуры данных и алгоритмы в Python . Эти концепции имеют решающее значение, когда вы выполняете операции с данными и вам необходимо оптимизировать обработку данных. В то время как структуры данных помогают в организации информации, алгоритмы предоставляют рекомендации для решения проблемы анализа данных. Вместе они предоставляют ученым-компьютерщикам способ обработки информации, предоставленной в качестве входных данных.
Если вам интересно узнать о науке о данных, ознакомьтесь с программой IIIT-B & upGrad Executive PG по науке о данных, которая создана для работающих профессионалов и предлагает более 10 тематических исследований и проектов, практические семинары, наставничество с отраслевыми экспертами, 1 -на-1 с отраслевыми наставниками, более 400 часов обучения и помощи в трудоустройстве в ведущих фирмах.
Сколько дней нужно, чтобы изучить структуры данных и алгоритмы?
Когда дело доходит до информатики, структуры данных и алгоритмы считаются самыми сложными темами. Но они действительно важны для каждого программиста. Если вы тратите примерно 3-4 часа ежедневно, то вам потребуется как минимум 6-8 недель для изучения структур данных и алгоритмов.
Здесь нет жесткой временной шкалы, потому что она будет полностью зависеть от вашего темпа и способностей к обучению. Если вы хорошо разбираетесь в основах, то вам будет довольно легко разобраться в глубоких концепциях структур данных и алгоритмов.
Каковы различные типы алгоритма?
Алгоритм — это пошаговая процедура, которой необходимо следовать для решения любой проблемы. Для разных задач нужны разные алгоритмы решения задачи. Каждый программист выбирает алгоритм решения той или иной задачи исходя из требований и быстродействия алгоритма.
Тем не менее, есть определенные топовые алгоритмы, которые программисты обычно рассматривают для решения разных задач. Некоторые из хорошо известных алгоритмов — это алгоритм грубой силы, жадный алгоритм, рандомизированный алгоритм, алгоритм динамического программирования, рекурсивный алгоритм, алгоритм «разделяй и властвуй» и алгоритм обратного отслеживания.
Каково основное использование Python?
Python — это язык программирования общего назначения, который используется для выполнения различных действий. Лучшее в Python то, что он не привязан к какому-либо конкретному приложению, и вы можете использовать его в соответствии со своими требованиями. Благодаря наличию библиотек, универсальности и простой для понимания структуре он считается одним из наиболее часто используемых языков программирования среди разработчиков.
Python в основном используется для разработки веб-сайтов и программного обеспечения. Помимо этого, он также используется для автоматизации задач, визуализации и анализа данных. Python довольно прост в изучении, поэтому даже непрограммисты используют этот язык для организации финансов и выполнения других повседневных задач.