
Python의 데이터 구조 및 알고리즘: 알아야 할 모든 것
게시 됨: 2020-05-06Python의 데이터 구조와 알고리즘 은 컴퓨터 과학에서 가장 기본적인 두 가지 개념입니다. 그들은 모든 프로그래머에게 없어서는 안될 도구입니다. Python의 데이터 구조는 프로그램이 처리하는 동안 메모리에 데이터를 구성하고 저장하는 작업을 처리합니다. 반면에 Python 알고리즘 은 특정 목적을 위한 데이터 처리에 도움이 되는 자세한 지침 집합을 나타냅니다.
또는 데이터 분석의 특정 문제를 해결하기 위해 알고리즘에서 다양한 데이터 구조를 논리적으로 사용한다고 말할 수 있습니다. 실제 문제이든 일반적인 코딩 관련 질문이든 정확한 솔루션을 찾으려면 Python의 데이터 구조와 알고리즘을 이해하는 것이 중요합니다. 이 기사에서는 다양한 Python 알고리즘 과 데이터 구조 에 대한 자세한 설명을 볼 수 있습니다 . Python에 대해 자세히 알아보려면 데이터 과학 과정 을 확인하십시오.
자세히 알아보기: R에서 가장 일반적으로 사용되는 6가지 데이터 구조
목차
Python의 데이터 구조는 무엇입니까?
데이터 구조는 데이터를 구성하고 저장하는 방법입니다. 데이터와 데이터에 대해 수행할 수 있는 다양한 논리적 작업 간의 관계를 설명합니다. 데이터 구조를 분류하는 방법에는 여러 가지가 있습니다. 한 가지 방법은 원시 데이터 유형과 비 원시 데이터 유형으로 분류하는 것입니다.
기본 데이터 유형에는 정수, 부동 소수점, 문자열 및 부울이 포함되지만 기본이 아닌 데이터 유형은 배열, 목록, 튜플, 사전, 집합 및 파일입니다. List, Tuples, Dictionaries 및 Sets와 같은 이러한 기본이 아닌 데이터 유형 중 일부는 Python에 내장되어 있습니다. Python에는 사용자 정의된 또 다른 범주의 데이터 구조가 있습니다. 즉, 사용자가 정의합니다. 여기에는 스택, 큐, 연결 목록, 트리, 그래프 및 HashMap이 포함됩니다.
기본 데이터 구조
이것들은 순수하고 단순한 데이터 값을 포함하는 Python의 기본 데이터 구조이며 데이터 조작을 위한 빌딩 블록 역할을 합니다. Python의 네 가지 기본 유형의 변수에 대해 이야기해 보겠습니다.
- 정수 – 이 데이터 유형은 숫자 데이터, 즉 소수점이 없는 양수 또는 음수 정수를 나타내는 데 사용됩니다. -1, 3 또는 6이라고 말합니다.
- Float – Float은 '부동 소수점 실수'를 의미합니다. 유리수를 나타내는 데 사용되며 일반적으로 2.0 또는 5.77과 같은 소수점을 포함합니다. Python은 동적으로 유형이 지정된 프로그래밍 언어이므로 객체가 저장하는 데이터 유형은 변경 가능하며 변수 유형을 명시적으로 지정할 필요가 없습니다.
- 문자열 – 이 데이터 유형은 알파벳, 단어 또는 영숫자 문자 모음을 나타냅니다. 큰따옴표 또는 작은따옴표 쌍 안에 일련의 문자를 포함하여 생성됩니다. 두 개 이상의 문자열을 연결하려면 '+' 연산을 적용하면 됩니다. 반복, 접합, 대문자 사용 및 검색은 Python의 다른 문자열 작업 중 일부입니다. 예: '파란색', '빨간색' 등
- 부울 – 이 데이터 유형은 비교 및 조건식에 유용하며 TRUE 또는 FALSE 값을 사용할 수 있습니다.
더 알아보기: Python의 데이터 프레임
기본이 아닌 내장 데이터 구조
기본 데이터 구조와 달리 기본이 아닌 데이터 유형은 값을 저장할 뿐만 아니라 다양한 형식의 값 모음을 저장합니다. Python의 기본이 아닌 데이터 구조를 살펴보겠습니다.
- 목록 – 이것은 파이썬에서 가장 다재다능한 데이터 구조이며 대괄호로 묶인 쉼표로 구분된 요소 목록으로 작성됩니다. 목록은 이종 요소와 동종 요소로 구성될 수 있습니다. 목록에 적용할 수 있는 메소드 중 일부는 index(), append(), extend(), insert(), remove(), pop() 등입니다. 목록은 변경 가능합니다. 즉, ID를 그대로 유지하면서 내용을 변경할 수 있습니다.
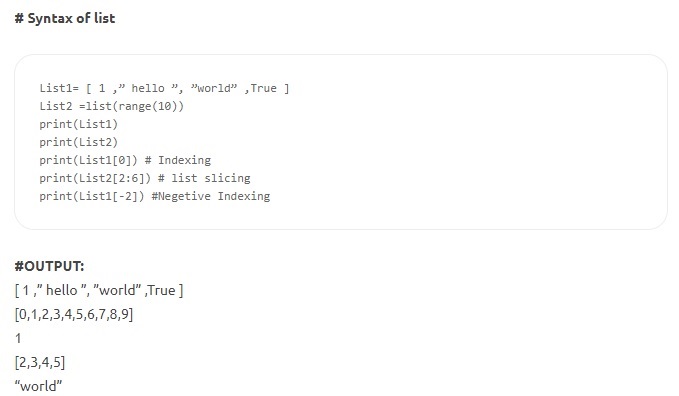
원천
- 튜플 – 튜플은 목록과 유사하지만 변경할 수 없습니다. 또한 List와 달리 Tuple은 대괄호 대신 괄호 안에 선언됩니다. 불변성의 특징은 요소가 튜플에 정의되면 삭제, 재할당 또는 편집할 수 없음을 나타냅니다. 데이터 구조의 선언된 값이 조작되거나 재정의되지 않도록 합니다.
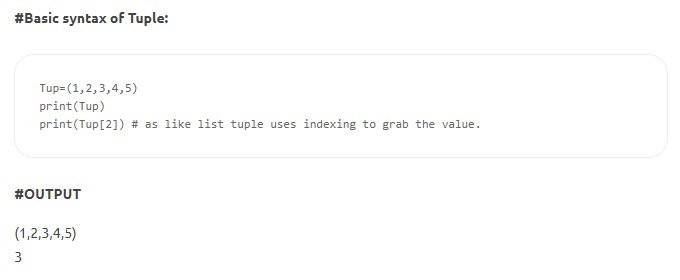
원천
- 사전 – 사전은 키-값 쌍으로 구성됩니다. 'key'는 항목을 식별하고 'value'는 항목의 값을 저장합니다. 콜론은 키와 값을 구분합니다. 항목은 쉼표로 구분되며 전체 내용은 중괄호로 묶입니다. 키는 변경할 수 없지만(숫자, 문자열 또는 튜플) 값은 모든 유형이 될 수 있습니다.
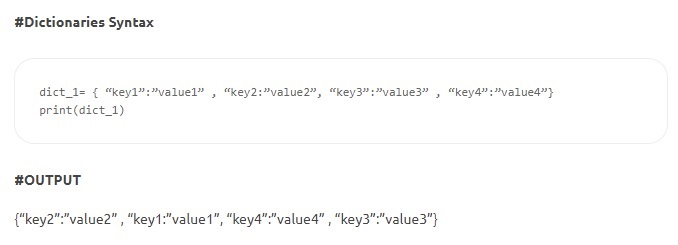
원천
- 집합 – 집합은 고유한 요소의 정렬되지 않은 컬렉션입니다. 목록과 마찬가지로 세트는 변경 가능하고 대괄호 안에 작성되지만 두 값이 같을 수는 없습니다. 일부 Set 메서드에는 count(), index(), any(), all() 등이 포함됩니다.
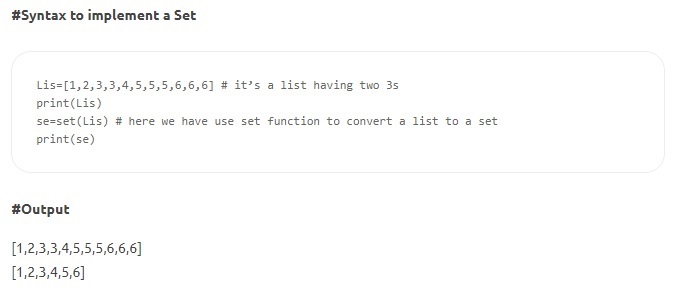
원천
- 목록 대 배열 – Python에는 내장된 배열 개념이 없습니다. 배열을 초기화하기 전에 NumPy 패키지를 사용하여 배열을 가져올 수 있습니다. NumPy에 대해 더 알고 싶다면 파이썬 NumPy 튜토리얼을 확인하세요 . 목록과 배열은 한 가지 차이점을 제외하고 대부분 유사합니다. 배열은 동종 요소의 모음이지만 목록에는 동종 항목과 이종 항목이 모두 포함됩니다.
확인: 이진 트리의 유형
Python의 사용자 정의 데이터 구조
Python의 데이터 구조와 알고리즘에 대한 논의의 다음 단계 는 다양한 사용자 정의 데이터 구조에 대한 간략한 개요입니다.
- 스택 – 스택은 Python의 선형 데이터 구조입니다. 스택에 항목을 저장하는 것은 FILO(선입 선출/후입) 또는 LIFO(후입 선출) 원칙을 기반으로 합니다. 스택에서 한 쪽 끝에 새 요소를 추가하면 같은 쪽에서 요소가 제거됩니다. 'push' 및 'pop' 작업은 각각 삽입 및 삭제에 사용됩니다. 스택과 관련된 다른 함수는 empty(), size() 및 top()입니다. 스택은 Python 라이브러리의 모듈 및 데이터 구조(list, collections.deque 및 queue.LifoQueue)를 사용하여 구현할 수 있습니다.
- 큐 – 스택과 유사하게 큐는 선형 데이터 구조입니다. 그러나 항목은 FIFO(선입 선출) 원칙에 따라 저장됩니다. 대기열에서 가장 최근에 추가된 항목이 먼저 제거됩니다. Queue와 관련된 작업에는 Enqueue(요소 추가), Dequeue(요소 삭제), Front 및 Rear가 있습니다. 스택과 마찬가지로 큐는 Python 라이브러리의 모듈 및 데이터 구조(list, collections.deque 및 큐)를 사용하여 구현할 수 있습니다.
- 트리 – 트리는 Python의 비선형 데이터 구조이며 가장자리로 연결된 노드로 구성됩니다. 트리의 속성은 하나의 노드가 루트 노드로 지정되고 루트가 아닌 다른 모든 노드에는 관련 부모 노드가 있으며 각 노드에는 임의의 수의 자식 노드가 있을 수 있다는 것입니다. 이진 트리 데이터 구조는 요소에 자식이 2개 이하인 데이터 구조입니다.
- 연결 목록 – 연결을 통해 함께 결합된 일련의 데이터 요소를 Python에서는 연결 목록이라고 합니다. 또한 선형 데이터 구조입니다. 연결 목록의 각 데이터 요소는 포인터를 사용하여 다른 요소에 연결됩니다. Python 라이브러리에는 연결 목록이 포함되어 있지 않으므로 노드 개념을 사용하여 구현됩니다. Linked List는 요소의 삽입/삭제가 용이하고 동적인 크기를 갖는다는 점에서 배열에 비해 장점이 있습니다.
- 그래프 – Python의 그래프는 링크로 연결된 일부 개체 쌍과 함께 개체 집합을 그림으로 나타냅니다. 정점은 상호 연결된 객체를 나타내며 정점을 연결하는 링크를 가장자리라고 합니다. Python 사전 데이터 유형을 사용하여 그래프를 표시할 수 있습니다. 본질적으로 사전의 '키'는 꼭짓점을 나타내고 '값'은 꼭짓점 사이의 연결 또는 가장자리를 나타냅니다.
- HashMaps/Hash Tables – 이 유형의 데이터 구조에서 해시 함수는 데이터 요소의 주소 또는 인덱스 값을 생성합니다. 인덱스 값은 데이터 값에 대한 키 역할을 하여 데이터에 더 빠르게 액세스할 수 있습니다. 사전 데이터 유형과 마찬가지로 해시 테이블에는 키-값 쌍이 있지만 해싱 함수는 키를 생성합니다.
Python의 알고리즘은 무엇입니까?
Python 알고리즘 은 주어진 문제에 대한 솔루션을 얻기 위해 실행되는 일련의 명령입니다. 알고리즘은 특정 언어가 아니기 때문에 여러 프로그래밍 언어로 구현할 수 있습니다. 알고리즘 작성을 안내하는 표준 규칙은 없습니다. 리소스 및 문제 종속적이지만 흐름 제어(if-else) 및 루프(do, while, for)와 같은 몇 가지 공통 코드 구성을 공유합니다. 다음 섹션에서는 트리 탐색, 정렬, 검색 및 그래프 알고리즘에 대해 간략하게 설명합니다.

트리 순회 알고리즘
순회는 루트 노드에서 시작하여 트리의 모든 노드를 방문하는 프로세스입니다. 트리는 세 가지 다른 방법으로 탐색할 수 있습니다.
- In-order traversal은 왼쪽에 있는 하위 트리를 먼저 방문한 다음 루트를 방문한 다음 오른쪽 하위 트리를 방문하는 것입니다.
– 선주문 순회에서 가장 먼저 방문하는 노드는 루트 노드이고, 그 다음이 왼쪽 하위 트리, 마지막으로 오른쪽 하위 트리입니다.
– 후위 순회 알고리즘에서 왼쪽 하위 트리를 먼저 방문한 다음 오른쪽 하위 트리를 방문하고 루트 노드를 마지막으로 방문합니다.
더 알아보기: 완벽한 의사결정나무를 만드는 방법
정렬 알고리즘
정렬 알고리즘은 데이터를 특정 형식으로 정렬하는 방법을 나타냅니다. 정렬은 데이터 검색이 높은 수준으로 최적화되고 데이터가 읽을 수 있는 형식으로 표시되도록 합니다. Python의 다섯 가지 정렬 알고리즘 유형을 살펴보겠습니다.
- 버블 정렬 – 이 알고리즘은 인접 요소가 잘못된 순서로 있는 경우 반복적으로 교체되는 비교를 기반으로 합니다.
- 병합 정렬 – 분할 정복 알고리즘을 기반으로 병합 정렬은 배열을 두 개의 반으로 나누고 정렬한 다음 결합합니다.
- 삽입 정렬 – 이 정렬은 처음 두 요소를 비교하고 정렬하는 것으로 시작됩니다. 그런 다음 세 번째 요소가 이전에 정렬된 두 요소와 비교되는 식입니다.
- Shell Sort - Insertion Sort의 한 형태이지만 여기서는 멀리 떨어져 있는 요소를 정렬한다. 주어진 목록의 큰 하위 목록이 정렬되고 모든 요소가 정렬될 때까지 목록의 크기가 점진적으로 줄어듭니다.
- 선택 정렬 – 이 알고리즘은 요소 목록에서 최소값을 찾아 정렬된 목록에 넣는 것으로 시작합니다. 그런 다음 정렬되지 않은 목록의 나머지 요소 각각에 대해 프로세스가 반복됩니다. 정렬된 목록에 들어가는 새 요소는 기존 요소와 비교되어 올바른 위치에 배치됩니다. 모든 요소가 정렬될 때까지 프로세스가 계속됩니다.
알고리즘 검색
검색 알고리즘은 다양한 데이터 구조에서 요소를 확인하고 검색하는 데 도움이 됩니다. 검색 알고리즘의 한 유형은 목록을 순차적으로 탐색하고 모든 요소를 확인하는 순차 검색(선형 검색) 방법을 적용합니다. 다른 유형인 간격 검색에서는 정렬된 데이터 구조에서 요소를 검색합니다(이진 검색). 몇 가지 예를 살펴보겠습니다.
- 선형 검색 – 이 알고리즘에서는 각 항목을 하나씩 순차적으로 검색합니다.
- 이진 검색 – 검색 간격이 반복적으로 반으로 나뉩니다. 검색할 요소가 구간의 중심 성분보다 낮으면 구간이 아래쪽으로 좁아집니다. 그렇지 않으면 위쪽 절반으로 좁혀집니다. 값을 찾을 때까지 프로세스가 반복됩니다.
그래프 알고리즘
모서리를 사용하여 그래프를 탐색하는 두 가지 방법이 있습니다. 이것들은:
- 깊이 우선 탐색(DFS) – 이 알고리즘에서 그래프는 깊이 방향으로 이동합니다. 반복이 막다른 골목에 직면하면 스택을 사용하여 다음 정점으로 이동하여 검색을 시작합니다. DFS는 설정된 데이터 유형을 사용하여 Python에서 구현됩니다.
- BFS(Breadth-First Traversal) – 이 알고리즘에서 그래프는 폭 방향으로 이동합니다. 반복이 막다른 골목에 직면하면 대기열을 사용하여 다음 정점으로 이동하여 검색을 시작합니다. BFS는 큐 데이터 구조를 사용하여 Python에서 구현됩니다.
알고리즘 분석
- A Priori Analysis – 이것은 구현 전 알고리즘에 대한 이론적 분석을 나타냅니다. 알고리즘의 효율성은 프로세서 속도와 같은 요소가 일정하고 알고리즘에 영향을 미치지 않는다고 가정하여 측정됩니다.
- 사후 분석 – 알고리즘 구현 후의 경험적 분석을 의미합니다. 프로그래밍 언어를 사용하여 선택한 알고리즘을 구현한 다음 컴퓨터에서 실행합니다. 이 분석은 알고리즘이 실행되는 데 필요한 시간 및 공간과 같은 통계를 수집합니다.
결론
프로그래밍 분야의 베테랑이든 처음이든 관계없이 Python의 데이터 구조와 알고리즘을 무시할 수 없습니다 . 이러한 개념은 데이터에 대한 작업을 수행할 때 중요하며 데이터 처리를 최적화해야 합니다. 데이터 구조가 정보를 구성하는 데 도움이 되는 반면 알고리즘은 데이터 분석 문제를 해결하기 위한 지침을 제공합니다. 함께 입력 데이터로 제공된 정보를 처리하기 위해 컴퓨터 과학자에게 방법을 제공합니다.
데이터 과학에 대해 자세히 알아보려면 작업 전문가를 위해 만들어졌으며 10개 이상의 사례 연구 및 프로젝트, 실용적인 실습 워크숍, 업계 전문가와의 멘토링, 1 - 업계 멘토와 일대일, 400시간 이상의 학습 및 최고의 기업과의 취업 지원.
데이터 구조 및 알고리즘을 배우는 데 며칠이 걸립니까?
컴퓨터 과학과 관련하여 데이터 구조와 알고리즘은 가장 어려운 주제로 간주됩니다. 그러나 모든 프로그래머에게 배우는 것이 정말 중요합니다. 하루에 약 3~4시간을 소비한다면 데이터 구조와 알고리즘을 배우는 데 최소 6~8주가 필요할 것입니다.
이것은 전적으로 귀하의 속도와 학습 능력에 달려 있기 때문에 여기에는 엄격한 일정이 없습니다. 기본 사항을 잘 이해한다면 데이터 구조와 알고리즘에 대한 심층적인 개념을 익히기가 매우 쉬울 것입니다.
알고리즘의 다른 유형은 무엇입니까?
알고리즘은 문제를 해결하기 위해 따라야 하는 단계별 절차입니다. 다른 문제에는 문제를 해결하기 위한 다른 알고리즘이 필요합니다. 모든 프로그래머는 알고리즘의 요구 사항과 속도에 따라 특정 문제를 해결하기 위한 알고리즘을 선택합니다.
그러나 프로그래머가 일반적으로 다른 문제를 해결하기 위해 고려하는 특정 상위 알고리즘이 있습니다. 잘 알려진 알고리즘 중 일부는 Brute-force 알고리즘, Greedy 알고리즘, Randomized 알고리즘, 동적 프로그래밍 알고리즘, Recursive 알고리즘, Divide & Conquer 알고리즘 및 Backtracking 알고리즘입니다.
파이썬의 주요 용도는 무엇입니까?
Python은 다양한 활동을 수행하는 데 사용되는 범용 프로그래밍 언어입니다. Python의 가장 좋은 점은 특정 응용 프로그램에 구속되지 않고 요구 사항에 따라 사용할 수 있다는 것입니다. 라이브러리의 가용성, 다양성 및 이해하기 쉬운 구조로 인해 개발자들 사이에서 가장 많이 사용되는 프로그래밍 언어 중 하나로 간주됩니다.
Python은 주로 웹 사이트 및 소프트웨어 개발에 사용됩니다. 그 외에도 작업 자동화, 데이터 시각화 및 데이터 분석에도 사용됩니다. Python은 배우기 매우 쉽고, 이것이 프로그래머가 아닌 사람들도 재정을 정리하고 다른 일상적인 작업을 수행하기 위해 이 언어를 채택하는 이유입니다.