
Datenstrukturen und Algorithmen in Python: Alles, was Sie wissen müssen
Veröffentlicht: 2020-05-06Datenstrukturen und Algorithmen in Python sind zwei der grundlegendsten Konzepte in der Informatik. Sie sind unverzichtbare Werkzeuge für jeden Programmierer. Datenstrukturen in Python befassen sich mit der Organisation und Speicherung von Daten im Speicher, während ein Programm sie verarbeitet. Andererseits beziehen sich Python-Algorithmen auf die detaillierten Anweisungen, die bei der Verarbeitung von Daten für einen bestimmten Zweck helfen.
Alternativ kann gesagt werden, dass verschiedene Datenstrukturen von Algorithmen logisch verwendet werden, um ein bestimmtes Problem der Datenanalyse zu lösen. Ob es sich um ein reales Problem oder eine typische codierungsbezogene Frage handelt, ein Verständnis der Datenstrukturen und Algorithmen in Python ist entscheidend, wenn Sie eine genaue Lösung finden möchten. In diesem Artikel finden Sie eine detaillierte Diskussion verschiedener Python-Algorithmen und Datenstrukturen. Wenn Sie mehr über Python erfahren möchten, sehen Sie sich unsere Data-Science-Kurse an .
Erfahren Sie mehr: Die sechs am häufigsten verwendeten Datenstrukturen in R
Inhaltsverzeichnis
Was sind Datenstrukturen in Python?
Datenstrukturen sind eine Möglichkeit, Daten zu organisieren und zu speichern; Sie erklären die Beziehung zwischen Daten und verschiedenen logischen Operationen, die an den Daten durchgeführt werden können. Es gibt viele Möglichkeiten, wie Datenstrukturen klassifiziert werden können. Eine Möglichkeit besteht darin, sie in primitive und nicht-primitive Datentypen zu kategorisieren.
Während die primitiven Datentypen Integers, Float, Strings und Boolean umfassen, sind die nicht-primitiven Datentypen Array, List, Tuples, Dictionary, Sets und Files. Einige dieser nicht primitiven Datentypen, wie Listen, Tupel, Wörterbücher und Mengen, sind in Python integriert. Es gibt eine weitere Kategorie von Datenstrukturen in Python, die benutzerdefiniert ist; das heißt, Benutzer definieren sie. Dazu gehören Stack, Queue, Linked List, Tree, Graph und HashMap.
Primitive Datenstrukturen
Dies sind die grundlegenden Datenstrukturen in Python, die reine und einfache Datenwerte enthalten und als Bausteine für die Bearbeitung von Daten dienen. Lassen Sie uns über die vier primitiven Typen von Variablen in Python sprechen:
- Ganze Zahlen – Dieser Datentyp wird verwendet, um numerische Daten darzustellen, d. h. positive oder negative ganze Zahlen ohne Dezimalpunkt. Sagen Sie -1, 3 oder 6.
- Float – Float bedeutet „Reelle Fließkommazahl“. Es wird verwendet, um rationale Zahlen darzustellen, die normalerweise einen Dezimalpunkt wie 2,0 oder 5,77 enthalten. Da Python eine dynamisch typisierte Programmiersprache ist, ist der Datentyp, den ein Objekt speichert, änderbar, und es besteht keine Notwendigkeit, den Typ Ihrer Variablen explizit anzugeben.
- String – Dieser Datentyp bezeichnet eine Sammlung von Alphabeten, Wörtern oder alphanumerischen Zeichen. Es wird erstellt, indem eine Reihe von Zeichen in ein Paar doppelte oder einfache Anführungszeichen eingeschlossen wird. Um zwei oder mehr Strings zu verketten, kann die '+'-Operation auf sie angewendet werden. Wiederholen, Spleißen, Großschreiben und Abrufen sind einige der anderen String-Operationen in Python. Beispiel: 'blau', 'rot' usw.
- Boolean – Dieser Datentyp ist nützlich in Vergleichs- und Bedingungsausdrücken und kann die Werte TRUE oder FALSE annehmen.
Mehr wissen: Datenrahmen in Python
Eingebaute nicht primitive Datenstrukturen
Im Gegensatz zu primitiven Datenstrukturen speichern nicht primitive Datentypen nicht nur Werte, sondern eine Sammlung von Werten in unterschiedlichen Formaten. Werfen wir einen Blick auf nicht-primitive Datenstrukturen in Python:
- Listen – Dies ist die vielseitigste Datenstruktur in Python und wird als Liste von durch Kommas getrennten Elementen geschrieben, die in eckige Klammern eingeschlossen sind. Eine Liste kann sowohl aus heterogenen als auch aus homogenen Elementen bestehen. Einige der auf eine Liste anwendbaren Methoden sind index(), append(), extend(), insert(), remove(), pop() usw. Listen sind änderbar; Das heißt, ihr Inhalt kann geändert werden, wobei die Identität intakt bleibt.
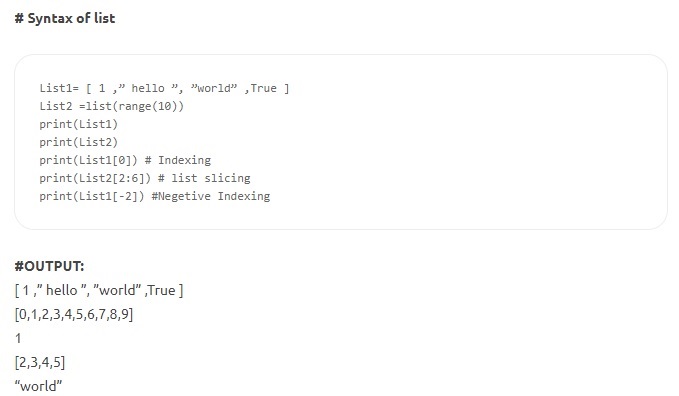
Quelle
- Tupel – Tupel ähneln Listen, sind jedoch unveränderlich. Außerdem werden Tupel im Gegensatz zu Listen in Klammern statt in eckigen Klammern deklariert. Das Merkmal der Unveränderlichkeit bedeutet, dass ein einmal in einem Tupel definiertes Element nicht gelöscht, neu zugewiesen oder bearbeitet werden kann. Es stellt sicher, dass die deklarierten Werte der Datenstruktur nicht manipuliert oder überschrieben werden.
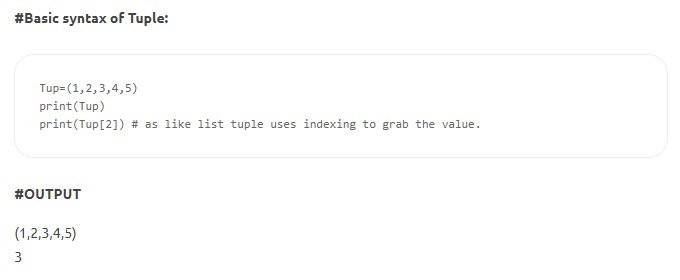
Quelle
- Wörterbücher – Wörterbücher bestehen aus Schlüssel-Wert-Paaren. Der „Schlüssel“ identifiziert ein Element, und der „Wert“ speichert den Wert des Elements. Ein Doppelpunkt trennt den Schlüssel von seinem Wert. Die Elemente werden durch Kommas getrennt, wobei das Ganze in geschweiften Klammern eingeschlossen ist. Während Schlüssel unveränderlich sind (Zahlen, Strings oder Tupel), können die Werte jeden Typs haben.
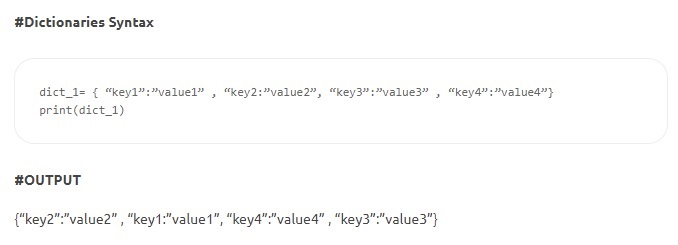
Quelle
- Sets – Sets sind eine ungeordnete Sammlung einzigartiger Elemente. Wie Listen sind Mengen veränderlich und werden in eckige Klammern geschrieben, aber keine zwei Werte können gleich sein. Einige Set-Methoden beinhalten count(), index(), any(), all() usw.
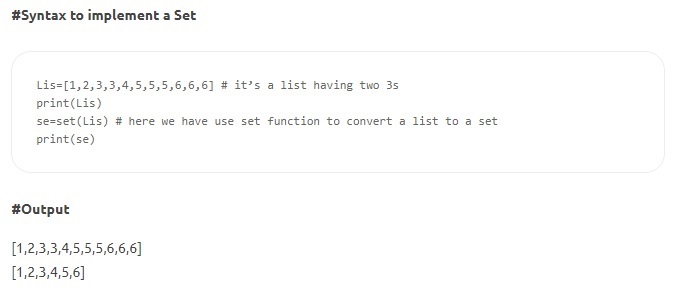
Quelle
- Listen vs. Arrays – Es gibt kein eingebautes Konzept von Arrays in Python. Arrays können mit dem NumPy-Paket importiert werden, bevor sie initialisiert werden. Um mehr über NumPy zu erfahren, können Sie sich unser Python-NumPy-Tutorial ansehen . Listen und Arrays sind bis auf einen Unterschied größtenteils ähnlich – während Arrays Sammlungen von nur homogenen Elementen sind, enthalten Listen sowohl homogene als auch heterogene Elemente.
Checkout: Arten von Binärbäumen
Benutzerdefinierte Datenstrukturen in Python
Als nächstes folgt in unserer Diskussion über Datenstrukturen und Algorithmen in Python ein kurzer Überblick über die verschiedenen benutzerdefinierten Datenstrukturen:
- Stacks – Stacks sind lineare Datenstrukturen in Python. Die Lagerung von Artikeln in Stapeln basiert auf den Prinzipien First-In/Last-Out (FILO) oder Last-In/First-Out (LIFO). In Stapeln wird das Hinzufügen eines neuen Elements an einem Ende von der Entfernung eines Elements am selben Ende begleitet. Die Operationen „push“ und „pop“ werden für Einfügungen bzw. Löschungen verwendet. Andere Stack-bezogene Funktionen sind empty(), size() und top(). Stapel können mithilfe von Modulen und Datenstrukturen aus der Python-Bibliothek implementiert werden – list, collections.deque und queue.LifoQueue.
- Queue – Ähnlich wie Stacks sind Queues lineare Datenstrukturen. Artikel werden jedoch nach dem First-In/First-Out-Prinzip (FIFO) gelagert. In einer Warteschlange wird das zuletzt hinzugefügte Element zuerst entfernt. Operationen im Zusammenhang mit Queue umfassen Enqueue (Hinzufügen von Elementen), Dequeue (Löschen von Elementen), Front und Rear. Wie Stacks können Queues mit Modulen und Datenstrukturen aus der Python-Bibliothek implementiert werden – list, collections.deque und queue.
- Baum – Bäume sind nichtlineare Datenstrukturen in Python und bestehen aus Knoten, die durch Kanten verbunden sind. Die Eigenschaften eines Baums sind, dass ein Knoten als Wurzelknoten bezeichnet wird, außer der Wurzel, jeder andere Knoten hat einen zugeordneten Elternknoten, und jeder Knoten kann eine beliebige Anzahl von Kindknoten haben. Eine binäre Baumdatenstruktur ist eine Struktur, deren Elemente nicht mehr als zwei Kinder haben.
- Verknüpfte Liste – Eine Reihe von Datenelementen, die über Links miteinander verbunden sind, wird in Python als verkettete Liste bezeichnet. Es ist auch eine lineare Datenstruktur. Jedes Datenelement in einer verknüpften Liste ist mit einem anderen unter Verwendung eines Zeigers verbunden. Da die Python-Bibliothek keine verknüpften Listen enthält, werden sie mithilfe des Konzepts von Knoten implementiert. Verkettete Listen haben gegenüber Arrays den Vorteil, dass sie eine dynamische Größe haben und Elemente einfach eingefügt/gelöscht werden können.
- Graph – Ein Graph in Python stellt bildlich eine Menge von Objekten dar, wobei einige Objektpaare durch Links verbunden sind. Scheitelpunkte stellen die miteinander verbundenen Objekte dar, und die Verbindungen, die die Scheitelpunkte verbinden, werden als Kanten bezeichnet. Der Datentyp des Python-Wörterbuchs kann zur Darstellung von Diagrammen verwendet werden. Im Wesentlichen stellen die „Schlüssel“ des Wörterbuchs die Eckpunkte dar, und die „Werte“ geben die Verbindungen oder Kanten zwischen den Eckpunkten an.
- HashMaps/Hash-Tabellen – Bei dieser Art von Datenstruktur generiert eine Hash-Funktion die Adresse oder den Indexwert des Datenelements. Der Indexwert dient als Schlüssel zum Datenwert, der einen schnelleren Zugriff auf Daten ermöglicht. Wie beim Dictionary-Datentyp haben Hash-Tabellen Schlüssel-Wert-Paare, aber eine Hash-Funktion generiert den Schlüssel.
Was sind Algorithmen in Python?
Python-Algorithmen sind eine Reihe von Anweisungen, die ausgeführt werden, um die Lösung für ein bestimmtes Problem zu finden. Da Algorithmen nicht sprachspezifisch sind, können sie in mehreren Programmiersprachen implementiert werden. Beim Schreiben von Algorithmen gibt es keine Standardregeln. Sie sind ressourcen- und problemabhängig, haben aber einige gemeinsame Codekonstrukte gemeinsam, wie z. B. Flusssteuerung (if-else) und Schleifen (do, while, for). In den folgenden Abschnitten werden wir kurz Tree Traversal, Sorting, Searching und Graph Algorithms diskutieren.

Tree-Traversal-Algorithmen
Traversal ist ein Prozess, bei dem alle Knoten eines Baums besucht werden, beginnend mit dem Wurzelknoten. Ein Baum kann auf drei verschiedene Arten durchlaufen werden:
– Beim In-Order-Traversal wird zuerst der Teilbaum auf der linken Seite besucht, gefolgt von der Wurzel und dann dem rechten Teilbaum.
– Bei der Vorbestellungsdurchquerung wird zuerst der Wurzelknoten besucht, gefolgt vom linken Teilbaum und schließlich dem rechten Teilbaum.
– Beim Post-Order-Traversal-Algorithmus wird zuerst der linke Teilbaum besucht, dann wird der rechte Teilbaum besucht, wobei der Wurzelknoten zuletzt besucht wird.
Erfahren Sie mehr: So erstellen Sie einen perfekten Entscheidungsbaum
Sortieralgorithmen
Sortieralgorithmen bezeichnen die Möglichkeiten, Daten in einem bestimmten Format anzuordnen. Das Sortieren stellt sicher, dass die Datensuche auf hohem Niveau optimiert wird und dass die Daten in einem lesbaren Format präsentiert werden. Schauen wir uns die fünf verschiedenen Arten von Sortieralgorithmen in Python an:
- Bubble Sort – Dieser Algorithmus basiert auf einem Vergleich, bei dem benachbarte Elemente wiederholt ausgetauscht werden, wenn sie sich in einer falschen Reihenfolge befinden.
- Merge Sort – Basierend auf dem Divide-and-Conquer-Algorithmus teilt Merge Sort das Array in zwei Hälften, sortiert sie und kombiniert sie dann.
- Insertion Sort – Diese Sortierung beginnt mit dem Vergleichen und Sortieren der ersten beiden Elemente. Dann wird das dritte Element mit den beiden zuvor sortierten Elementen verglichen und so weiter.
- Shell Sort – Es ist eine Form von Insertion Sort, aber hier werden weit entfernte Elemente sortiert. Eine große Unterliste einer gegebenen Liste wird sortiert, und die Größe der Liste wird schrittweise verringert, bis alle Elemente sortiert sind.
- Selection Sort – Dieser Algorithmus beginnt damit, den Mindestwert aus einer Liste von Elementen zu finden und ihn in eine sortierte Liste einzufügen. Der Vorgang wird dann für jedes der verbleibenden Elemente in der unsortierten Liste wiederholt. Das neue Element, das in die sortierte Liste aufgenommen wird, wird mit seinen vorhandenen Elementen verglichen und an der richtigen Position platziert. Der Prozess wird fortgesetzt, bis alle Elemente sortiert sind.
Algorithmen suchen
Suchalgorithmen helfen beim Überprüfen und Abrufen eines Elements aus verschiedenen Datenstrukturen. Ein Typ von Suchalgorithmen wendet das Verfahren der sequentiellen Suche an, bei dem die Liste sequentiell durchlaufen wird und jedes Element geprüft wird (lineare Suche). Bei einer anderen Art, der Intervallsuche, wird nach Elementen in sortierten Datenstrukturen gesucht (binäre Suche). Sehen wir uns einige der Beispiele an:
- Lineare Suche – Bei diesem Algorithmus wird jedes Element der Reihe nach einzeln durchsucht.
- Binäre Suche – Das Suchintervall wird immer wieder halbiert. Wenn das zu suchende Element niedriger als die zentrale Komponente des Intervalls ist, wird das Intervall auf die untere Hälfte eingeengt. Ansonsten ist es auf die obere Hälfte verengt. Der Vorgang wird wiederholt, bis der Wert gefunden ist.
Graphalgorithmen
Es gibt zwei Methoden, Graphen unter Verwendung ihrer Kanten zu durchlaufen. Diese sind:
- Depth-first Traversal (DFS) – Bei diesem Algorithmus wird ein Graph in einer Tiefenbewegung durchquert. Wenn eine Iteration in eine Sackgasse gerät, wird ein Stapel verwendet, um zum nächsten Scheitelpunkt zu gehen und eine Suche zu starten. DFS wird in Python unter Verwendung der festgelegten Datentypen implementiert.
- Breitentraversierung (BFS) – Bei diesem Algorithmus wird ein Graph in einer Breitenbewegung durchlaufen. Wenn eine Iteration in eine Sackgasse gerät, wird eine Warteschlange verwendet, um zum nächsten Scheitelpunkt zu gehen und eine Suche zu starten. BFS wird in Python unter Verwendung der Warteschlangendatenstruktur implementiert.
Algorithmusanalyse
- A-Priori-Analyse – Dies ist eine theoretische Analyse des Algorithmus vor seiner Implementierung. Die Effizienz eines Algorithmus wird gemessen, indem angenommen wird, dass Faktoren wie die Prozessorgeschwindigkeit konstant sind und keine Auswirkung auf den Algorithmus haben.
- A Posterior Analysis – Dies bezieht sich auf die empirische Analyse des Algorithmus nach seiner Implementierung. Eine Programmiersprache wird verwendet, um den ausgewählten Algorithmus zu implementieren, gefolgt von seiner Ausführung auf einem Computer. Diese Analyse sammelt Statistiken, wie z. B. die Zeit und den Speicherplatz, die für die Ausführung des Algorithmus erforderlich sind.
Fazit
Egal, ob Sie ein Veteran in der Programmierung oder neu darin sind, Sie können Datenstrukturen und Algorithmen in Python nicht ignorieren . Diese Konzepte sind entscheidend, wenn Sie Operationen mit Daten durchführen und die Datenverarbeitung optimieren müssen. Während Datenstrukturen bei der Organisation von Informationen helfen, liefern Algorithmen die Richtlinien zur Lösung des Problems der Datenanalyse. Zusammen bieten sie Informatikern eine Möglichkeit, die als Eingabedaten gegebenen Informationen zu verarbeiten.
Wenn Sie neugierig sind, etwas über Data Science zu lernen, schauen Sie sich das Executive PG Program in Data Science von IIIT-B & upGrad an, das für Berufstätige entwickelt wurde und mehr als 10 Fallstudien und Projekte, praktische Workshops, Mentoring mit Branchenexperten, 1 -on-1 mit Branchenmentoren, mehr als 400 Stunden Lern- und Jobunterstützung bei Top-Unternehmen.
Wie viele Tage dauert es, Datenstrukturen und Algorithmen zu lernen?
Datenstrukturen und Algorithmen gelten in der Informatik als die schwierigsten Themen überhaupt. Aber es ist wirklich wichtig, sie für jeden Programmierer zu lernen. Wenn Sie täglich etwa 3-4 Stunden aufwenden, benötigen Sie mindestens 6 bis 8 Wochen zum Erlernen von Datenstrukturen und Algorithmen.
Hier gibt es keinen starren Zeitplan, da dies vollständig von Ihrem Tempo und Ihren Lernfähigkeiten abhängt. Wenn Sie die Grundlagen gut verstehen, werden Sie mit den tiefgreifenden Konzepten von Datenstrukturen und Algorithmen ziemlich leicht zurechtkommen.
Welche Arten von Algorithmen gibt es?
Ein Algorithmus ist ein schrittweises Verfahren, das zur Lösung eines Problems befolgt werden muss. Unterschiedliche Probleme erfordern unterschiedliche Algorithmen zur Lösung des Problems. Jeder Programmierer wählt einen Algorithmus zur Lösung eines bestimmten Problems basierend auf den Anforderungen und der Geschwindigkeit des Algorithmus aus.
Dennoch gibt es bestimmte Top-Algorithmen, die Programmierer normalerweise zur Lösung verschiedener Probleme in Betracht ziehen. Einige der bekannten Algorithmen sind der Brute-Force-Algorithmus, der Greedy-Algorithmus, der randomisierte Algorithmus, der dynamische Programmieralgorithmus, der rekursive Algorithmus, der Divide & Conquer-Algorithmus und der Backtracking-Algorithmus.
Was ist die Hauptanwendung von Python?
Python ist eine universelle Programmiersprache, die zur Durchführung verschiedener Aktivitäten verwendet wird. Das Beste an Python ist, dass es nicht an eine bestimmte Anwendung gebunden ist und Sie es nach Ihren Anforderungen verwenden können. Aufgrund der Verfügbarkeit von Bibliotheken, der Vielseitigkeit und der leicht verständlichen Struktur gilt sie als eine der am häufigsten verwendeten Programmiersprachen unter Entwicklern.
Python wird hauptsächlich für die Entwicklung von Websites und Software verwendet. Darüber hinaus wird es auch für die Aufgabenautomatisierung, Datenvisualisierung und Datenanalyse verwendet. Python ist ziemlich einfach zu lernen, und deshalb übernehmen auch Nicht-Programmierer diese Sprache, um Finanzen zu organisieren und andere alltägliche Aufgaben zu erledigen.