
Structures de données et algorithme en Python : tout ce que vous devez savoir
Publié: 2020-05-06Les structures de données et les algorithmes en Python sont deux des concepts les plus fondamentaux de l'informatique. Ce sont des outils indispensables pour tout programmeur. Les structures de données en Python traitent de l'organisation et du stockage des données dans la mémoire pendant qu'un programme les traite. D'autre part, les algorithmes Python font référence à l'ensemble détaillé d'instructions qui aident au traitement des données dans un but spécifique.
Alternativement, on peut dire que différentes structures de données sont logiquement utilisées par des algorithmes pour résoudre un problème particulier d'analyse de données. Qu'il s'agisse d'un problème réel ou d'une question typique liée au codage, une compréhension des structures de données et des algorithmes en Python est cruciale si vous souhaitez trouver une solution précise. Dans cet article, vous trouverez une discussion détaillée des différents algorithmes et structures de données Python. Si vous souhaitez en savoir plus sur Python, consultez nos cours de science des données .
En savoir plus : Les six structures de données les plus couramment utilisées dans R
Table des matières
Que sont les structures de données en Python ?
Les structures de données sont un moyen d'organiser et de stocker des données ; ils expliquent la relation entre les données et diverses opérations logiques pouvant être effectuées sur les données. Il existe de nombreuses manières de classer les structures de données. Une façon consiste à les classer en types de données primitifs et non primitifs.
Alors que les types de données primitifs incluent les entiers, les flottants, les chaînes et les booléens, les types de données non primitifs sont les tableaux, les listes, les tuples, les dictionnaires, les ensembles et les fichiers. Certains de ces types de données non primitifs, tels que List, Tuples, Dictionnaires et Ensembles, sont intégrés à Python. Il existe une autre catégorie de structures de données en Python qui est définie par l'utilisateur ; c'est-à-dire que les utilisateurs les définissent. Ceux-ci incluent Stack, Queue, Linked List, Tree, Graph et HashMap.
Structures de données primitives
Ce sont les structures de données de base de Python contenant des valeurs de données pures et simples et servant de blocs de construction pour la manipulation des données. Parlons des quatre types primitifs de variables en Python :
- Entiers – Ce type de données est utilisé pour représenter des données numériques, c'est-à-dire des nombres entiers positifs ou négatifs sans point décimal. Dites, -1, 3 ou 6.
- Float - Float signifie "nombre réel à virgule flottante". Il est utilisé pour représenter des nombres rationnels, contenant généralement un point décimal comme 2,0 ou 5,77. Étant donné que Python est un langage de programmation à typage dynamique, le type de données qu'un objet stocke est modifiable et il n'est pas nécessaire d'indiquer explicitement le type de votre variable.
- Chaîne – Ce type de données désigne une collection d'alphabets, de mots ou de caractères alphanumériques. Il est créé en incluant une série de caractères dans une paire de guillemets doubles ou simples. Pour concaténer deux chaînes ou plus, l'opération '+' peut leur être appliquée. La répétition, l'épissage, la mise en majuscule et la récupération sont quelques-unes des autres opérations String en Python. Exemple : "bleu", "rouge", etc.
- Booléen – Ce type de données est utile dans les expressions de comparaison et conditionnelles et peut prendre les valeurs TRUE ou FALSE.
En savoir plus : Data Frames en Python
Structures de données non primitives intégrées
Contrairement aux structures de données primitives, les types de données non primitifs stockent non seulement des valeurs, mais une collection de valeurs dans différents formats. Examinons les structures de données non primitives en Python :
- Listes - Il s'agit de la structure de données la plus polyvalente de Python et elle est écrite sous la forme d'une liste d'éléments séparés par des virgules entre crochets. Une liste peut être composée d'éléments hétérogènes et homogènes. Certaines des méthodes applicables sur une liste sont index(), append(), extend(), insert(), remove(), pop(), etc. Les listes sont modifiables ; c'est-à-dire que leur contenu peut être modifié, en gardant l'identité intacte.
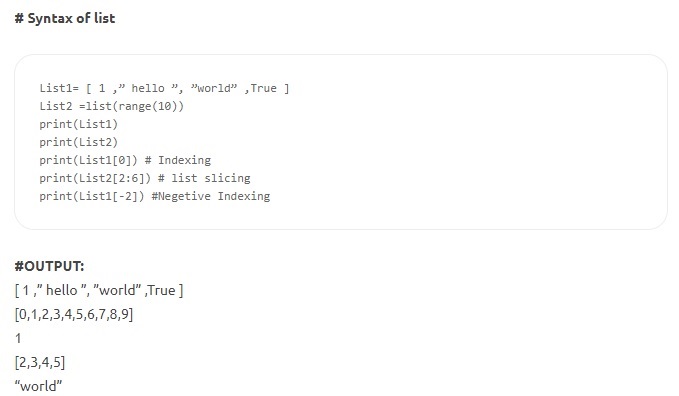
La source
- Tuples - Les tuples sont similaires aux listes mais sont immuables. De plus, contrairement aux listes, les tuples sont déclarés entre parenthèses au lieu de crochets. La caractéristique d'immuabilité indique qu'une fois qu'un élément a été défini dans un tuple, il ne peut pas être supprimé, réaffecté ou modifié. Il garantit que les valeurs déclarées de la structure de données ne sont pas manipulées ou remplacées.
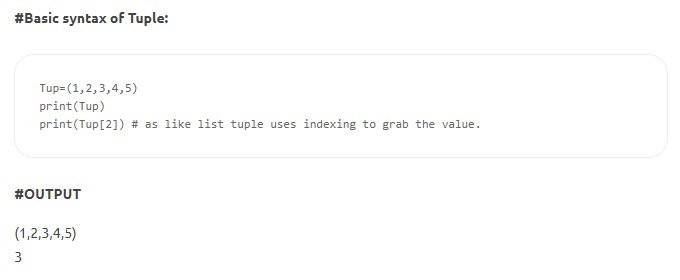
La source
- Dictionnaires – Les dictionnaires sont constitués de paires clé-valeur. La « clé » identifie un élément et la « valeur » stocke la valeur de l'élément. Deux-points séparent la clé de sa valeur. Les éléments sont séparés par des virgules, le tout étant entre accolades. Alors que les clés sont immuables (nombres, chaînes ou tuples), les valeurs peuvent être de n'importe quel type.
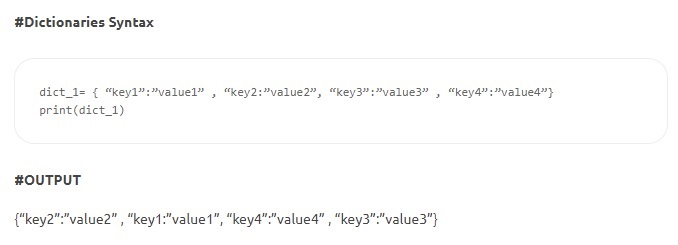
La source
- Ensembles - Les ensembles sont une collection non ordonnée d'éléments uniques. Comme les listes, les ensembles sont modifiables et écrits entre crochets, mais il n'y a pas deux valeurs identiques. Certaines méthodes Set incluent count(), index(), any(), all(), etc.
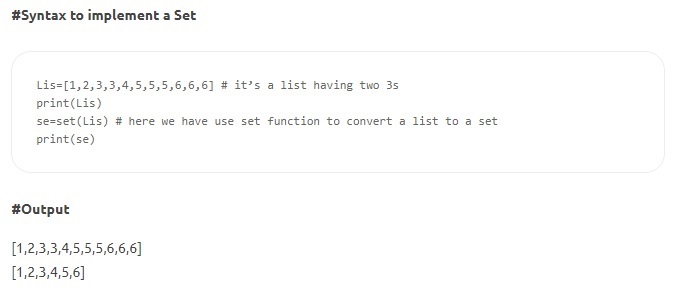
La source
- Listes vs tableaux - Il n'y a pas de concept intégré de tableaux en Python. Les tableaux peuvent être importés à l'aide du package NumPy avant de les initialiser. Pour en savoir plus sur NumPy, vous pouvez consulter notre tutoriel python NumPy . Les listes et les tableaux sont pour la plupart similaires à une différence près - alors que les tableaux sont des collections d'éléments homogènes uniquement, les listes incluent à la fois des éléments homogènes et hétérogènes.
Paiement : Types d'arbre binaire
Structures de données définies par l'utilisateur en Python
La prochaine étape de notre discussion sur les structures de données et les algorithmes en Python est un bref aperçu des différentes structures de données définies par l'utilisateur :
- Piles - Les piles sont des structures de données linéaires en Python. Le stockage des éléments dans Stacks est basé sur les principes First-In/Last-Out (FILO) ou Last-In/First-Out (LIFO). Dans Stacks, l'ajout d'un nouvel élément à une extrémité s'accompagne de la suppression d'un élément à la même extrémité. Les opérations 'push' et 'pop' sont utilisées respectivement pour les insertions et les suppressions. Les autres fonctions liées à Stack sont empty(), size() et top(). Les piles peuvent être implémentées à l'aide de modules et de structures de données de la bibliothèque Python - list, collections.deque et queue.LifoQueue.
- File d' attente - Semblable aux piles, les files d'attente sont des structures de données linéaires. Cependant, les éléments sont stockés selon le principe premier entré/premier sorti (FIFO). Dans une file d'attente, l'élément le moins récemment ajouté est supprimé en premier. Les opérations liées à la file d'attente incluent Enqueue (ajout d'éléments), Dequeue (suppression d'éléments), Avant et Arrière. Comme Stacks, les files d'attente peuvent être implémentées à l'aide de modules et de structures de données de la bibliothèque Python - list, collections.deque et queue.
- Arbre - Les arbres sont des structures de données non linéaires en Python et se composent de nœuds connectés par des arêtes. Les propriétés d'un arbre sont qu'un nœud est désigné comme nœud racine, autre que la racine, tous les autres nœuds ont un nœud parent associé et chaque nœud peut avoir un nombre arbitraire de nœuds enfants. Une structure de données Tree binaire est une structure dont les éléments n'ont pas plus de deux enfants.
- Liste liée - Une série d'éléments de données réunis via des liens est appelée liste liée en Python. C'est aussi une structure de données linéaire. Chaque élément de données d'une liste chaînée est connecté à un autre à l'aide d'un pointeur. Étant donné que la bibliothèque Python ne contient pas de listes liées, elles sont implémentées à l'aide du concept de nœuds. Les listes liées ont l'avantage sur les tableaux d'avoir une taille dynamique, avec une facilité d'insertion/suppression d'éléments.
- Graph - Un graphe en Python représente de manière picturale un ensemble d'objets, avec certaines paires d'objets reliées par des liens. Les sommets représentent les objets qui sont interconnectés et les liens qui joignent les sommets sont appelés arêtes. Le type de données du dictionnaire Python peut être utilisé pour présenter des graphiques. Essentiellement, les « clés » du dictionnaire représentent les sommets, et les « valeurs » indiquent les connexions ou les arêtes entre les sommets.
- HashMaps/Hash Tables – Dans ce type de structure de données, une fonction Hash génère l'adresse ou la valeur d'index de l'élément de données. La valeur d'index sert de clé à la valeur de données permettant un accès plus rapide aux données. Comme dans le type de données du dictionnaire, les tables de hachage ont des paires clé-valeur, mais une fonction de hachage génère la clé.
Que sont les algorithmes en Python ?
Les algorithmes Python sont un ensemble d'instructions qui sont exécutées pour obtenir la solution à un problème donné. Comme les algorithmes ne sont pas spécifiques à un langage, ils peuvent être implémentés dans plusieurs langages de programmation. Aucune règle standard ne guide l'écriture d'algorithmes. Ils dépendent des ressources et des problèmes, mais partagent certaines constructions de code communes, telles que le contrôle de flux (if-else) et les boucles (do, while, for). Dans les sections suivantes, nous aborderons brièvement les algorithmes de parcours d'arbre, de tri, de recherche et de graphe.

Algorithmes de traversée d'arbres
La traversée est un processus de visite de tous les nœuds d'un arbre, à partir du nœud racine. Un arbre peut être parcouru de trois manières différentes :
– Le parcours dans l'ordre consiste à visiter d'abord le sous-arbre de gauche, suivi de la racine, puis du sous-arbre de droite.
– Dans le parcours de pré-ordre, le premier à être visité est le nœud racine, suivi du sous-arbre gauche et enfin du sous-arbre droit.
– Dans l'algorithme de parcours post-ordre, le sous-arbre gauche est visité en premier, puis le sous-arbre droit est visité, le nœud racine étant visité en dernier.
En savoir plus : Comment créer un arbre de décision parfait
Algorithmes de tri
Les algorithmes de tri indiquent les façons d'organiser les données dans un format particulier. Le tri garantit que la recherche de données est optimisée à un niveau élevé et que les données sont présentées dans un format lisible. Examinons les cinq différents types d'algorithmes de tri en Python :
- Tri à bulles - Cet algorithme est basé sur une comparaison dans laquelle il y a un échange répété d'éléments adjacents s'ils sont dans un ordre incorrect.
- Tri par fusion – Basé sur l'algorithme de division pour régner, le tri par fusion divise le tableau en deux moitiés, les trie, puis les combine.
- Tri par insertion – Ce tri commence par la comparaison et le tri des deux premiers éléments. Ensuite, le troisième élément est comparé aux deux éléments précédemment triés et ainsi de suite.
- Shell Sort - C'est une forme de tri par insertion, mais ici, les éléments éloignés sont triés. Une grande sous-liste d'une liste donnée est triée, et la taille de la liste est progressivement réduite jusqu'à ce que tous les éléments soient triés.
- Tri par sélection - Cet algorithme commence par trouver la valeur minimale dans une liste d'éléments et la place dans une liste triée. Le processus est ensuite répété pour chacun des éléments restants dans la liste qui n'est pas triée. Le nouvel élément entrant dans la liste triée est comparé à ses éléments existants et placé à la bonne position. Le processus se poursuit jusqu'à ce que tous les éléments soient triés.
Algorithmes de recherche
Les algorithmes de recherche aident à vérifier et à récupérer un élément à partir de différentes structures de données. Un type d'algorithme de recherche applique la méthode de recherche séquentielle où la liste est parcourue séquentiellement et chaque élément est vérifié (recherche linéaire). Dans un autre type, la recherche par intervalles, les éléments sont recherchés dans des structures de données triées (recherche binaire). Regardons quelques-uns des exemples :
- Recherche linéaire - Dans cet algorithme, chaque élément est recherché séquentiellement un par un.
- Recherche binaire - L'intervalle de recherche est divisé en deux à plusieurs reprises. Si l'élément à rechercher est inférieur à la composante centrale de l'intervalle, l'intervalle est réduit à la moitié inférieure. Sinon, il est rétréci à la moitié supérieure. Le processus est répété jusqu'à ce que la valeur soit trouvée.
Algorithmes de graphe
Il existe deux méthodes pour parcourir les graphes en utilisant leurs arêtes. Ceux-ci sont:
- Traversée en profondeur (DFS) - Dans cet algorithme, un graphique est parcouru dans un mouvement de profondeur. Lorsqu'une itération fait face à une impasse, une pile est utilisée pour aller au sommet suivant et lancer une recherche. DFS est implémenté en Python à l'aide des types de données définis.
- Traversée en largeur d'abord (BFS) - Dans cet algorithme, un graphe est parcouru dans un mouvement en largeur. Lorsqu'une itération fait face à une impasse, une file d'attente est utilisée pour passer au sommet suivant et lancer une recherche. BFS est implémenté en Python en utilisant la structure de données de file d'attente.
Analyse d'algorithme
- A Priori Analysis - Cela représente une analyse théorique de l'algorithme avant sa mise en œuvre. L'efficacité d'un algorithme est mesurée en supposant que des facteurs, tels que la vitesse du processeur, sont constants et n'ont aucune conséquence sur l'algorithme.
- Une analyse postérieure - Cela fait référence à l'analyse empirique de l'algorithme après sa mise en œuvre. Un langage de programmation est utilisé pour implémenter l'algorithme sélectionné, suivi de son exécution sur un ordinateur. Cette analyse collecte des statistiques, telles que le temps et l'espace nécessaires à l'exécution de l'algorithme.
Conclusion
Que vous soyez un vétéran de la programmation ou un nouveau venu, vous ne pouvez pas ignorer les structures de données et les algorithmes de Python . Ces concepts sont cruciaux lorsque vous effectuez des opérations sur des données et que vous devez optimiser le traitement des données. Alors que les structures de données aident à organiser les informations, les algorithmes fournissent les lignes directrices pour résoudre le problème de l'analyse des données. Ensemble, ils fournissent aux informaticiens un moyen de traiter les informations fournies en tant que données d'entrée.
Si vous êtes curieux d'en savoir plus sur la science des données, consultez le programme Executive PG en science des données de IIIT-B & upGrad qui est créé pour les professionnels en activité et propose plus de 10 études de cas et projets, des ateliers pratiques, un mentorat avec des experts de l'industrie, 1 -on-1 avec des mentors de l'industrie, plus de 400 heures d'apprentissage et d'aide à l'emploi avec les meilleures entreprises.
Combien de jours faut-il pour apprendre les structures de données et les algorithmes ?
En informatique, les structures de données et les algorithmes sont considérés comme les sujets les plus difficiles de tous. Mais, ils sont vraiment importants à apprendre pour chaque programmeur. Si vous passez environ 3 à 4 heures par jour, vous aurez besoin d'au moins 6 à 8 semaines pour apprendre les structures de données et les algorithmes.
Il n'y a pas de calendrier rigide ici car cela dépendra entièrement de votre rythme et de vos capacités d'apprentissage. Si vous maîtrisez bien les principes fondamentaux, il vous sera assez facile de vous familiariser avec les concepts approfondis des structures de données et des algorithmes.
Quels sont les différents types d'algorithme ?
Un algorithme est une procédure étape par étape qui doit être suivie pour résoudre tout problème. Différents problèmes nécessitent différents algorithmes pour résoudre le problème. Chaque programmeur sélectionne un algorithme pour résoudre un problème particulier en fonction des exigences et de la vitesse de l'algorithme.
Pourtant, il existe certains algorithmes de pointe que les programmeurs considèrent généralement pour résoudre différents problèmes. Certains des algorithmes bien connus sont l'algorithme Brute-force, l'algorithme Greedy, l'algorithme randomisé, l'algorithme de programmation dynamique, l'algorithme récursif, l'algorithme Divide & Conquer et l'algorithme Backtracking.
Quelle est l'utilisation principale de Python ?
Python est un langage de programmation à usage général qui est utilisé pour effectuer différentes activités. La meilleure chose à propos de Python est qu'il n'est lié à aucune application spécifique et que vous pouvez l'utiliser selon vos besoins. En raison de la disponibilité des bibliothèques, de la polyvalence et de la structure facile à comprendre, il est considéré comme l'un des langages de programmation les plus utilisés par les développeurs.
Python est principalement utilisé pour le développement de sites Web et de logiciels. En dehors de cela, il est également utilisé pour l'automatisation des tâches, la visualisation des données et l'analyse des données. Python est assez facile à apprendre, et c'est pourquoi même les non-programmeurs adoptent ce langage pour organiser les finances et effectuer d'autres tâches quotidiennes.