
Struktury danych i algorytm w Pythonie: wszystko, co musisz wiedzieć
Opublikowany: 2020-05-06Struktury danych i algorytmy w Pythonie to dwa najbardziej podstawowe pojęcia w informatyce. Są niezbędnymi narzędziami dla każdego programisty. Struktury danych w Pythonie zajmują się organizacją i przechowywaniem danych w pamięci podczas ich przetwarzania przez program. Z drugiej strony algorytmy Pythona odwołują się do szczegółowego zestawu instrukcji, które pomagają w przetwarzaniu danych w określonym celu.
Alternatywnie można powiedzieć, że różne struktury danych są logicznie wykorzystywane przez algorytmy do opracowania konkretnego problemu analizy danych. Niezależnie od tego, czy jest to rzeczywisty problem, czy typowe pytanie związane z kodowaniem, zrozumienie struktur danych i algorytmów w Pythonie jest kluczowe, jeśli chcesz znaleźć dokładne rozwiązanie. W tym artykule znajdziesz szczegółowe omówienie różnych algorytmów i struktur danych Pythona. Jeśli chcesz dowiedzieć się więcej o Pythonie, zapoznaj się z naszymi kursami z analizy danych .
Dowiedz się więcej: Sześć najczęściej używanych struktur danych w R
Spis treści
Czym są struktury danych w Pythonie?
Struktury danych to sposób organizowania i przechowywania danych; wyjaśniają związek między danymi a różnymi operacjami logicznymi, które można wykonać na danych. Istnieje wiele sposobów klasyfikacji struktur danych. Jednym ze sposobów jest kategoryzacja ich na prymitywne i nieprymitywne typy danych.
Podczas gdy prymitywne typy danych obejmują liczby całkowite, zmiennoprzecinkowe, ciągi znaków i wartości logiczne, nieprymitywne typy danych to tablica, lista, krotki, słownik, zbiory i pliki. Niektóre z tych nieprymitywnych typów danych, takie jak List, Tuples, Dictionaries i Sets, są wbudowane w Pythonie. Istnieje inna kategoria struktur danych w Pythonie, która jest zdefiniowana przez użytkownika; to znaczy, że użytkownicy je definiują. Należą do nich Stack, Queue, Linked List, Tree, Graph i HashMap.
Prymitywne struktury danych
Są to podstawowe struktury danych w Pythonie zawierające czyste i proste wartości danych i służą jako bloki konstrukcyjne do manipulowania danymi. Porozmawiajmy o czterech podstawowych typach zmiennych w Pythonie:
- Liczby całkowite — ten typ danych służy do przedstawiania danych liczbowych, czyli dodatnich lub ujemnych liczb całkowitych bez kropki dziesiętnej. Powiedz, -1, 3 lub 6.
- Float — Float oznacza „zmiennoprzecinkową liczbę rzeczywistą”. Służy do reprezentowania liczb wymiernych, zwykle zawierających kropkę dziesiętną, taką jak 2,0 lub 5,77. Ponieważ Python jest dynamicznie typowanym językiem programowania, typ danych przechowywany przez obiekt jest zmienny i nie ma potrzeby jawnego określania typu zmiennej.
- String — ten typ danych oznacza zbiór alfabetów, słów lub znaków alfanumerycznych. Jest tworzony przez uwzględnienie serii znaków w parze podwójnych lub pojedynczych cudzysłowów. Aby połączyć dwa lub więcej ciągów, można do nich zastosować operację „+”. Powtarzanie, łączenie, pisanie wielkimi literami i pobieranie to tylko niektóre z innych operacji na ciągach znaków w Pythonie. Przykład: „niebieski”, „czerwony” itp.
- Boolean — ten typ danych jest przydatny w wyrażeniach porównawczych i warunkowych i może przyjmować wartości TRUE lub FALSE.
Dowiedz się więcej: ramki danych w Pythonie
Wbudowane nieprymitywne struktury danych
W przeciwieństwie do pierwotnych struktur danych, niepierwotne typy danych przechowują nie tylko wartości, ale także zbiór wartości w różnych formatach. Przyjrzyjmy się nieprostym strukturom danych w Pythonie:
- Listy — jest to najbardziej wszechstronna struktura danych w Pythonie i jest napisana jako lista elementów oddzielonych przecinkami, ujęta w nawiasy kwadratowe. Lista może składać się zarówno z elementów heterogenicznych, jak i jednorodnych. Niektóre z metod stosowanych na liście to index(), append(), extend(), insert(), remove(), pop() itd. Listy są zmienne; to znaczy, że ich zawartość można zmienić, zachowując tożsamość nienaruszoną.
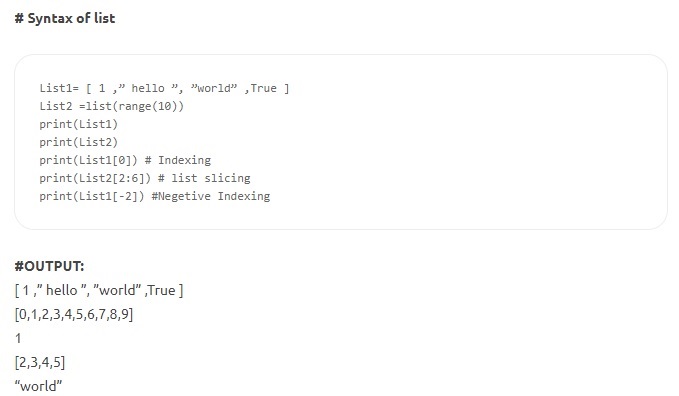
Źródło
- Krotki — krotki są podobne do list, ale są niezmienne. Ponadto, w przeciwieństwie do list, krotki są deklarowane w nawiasach, a nie w nawiasach kwadratowych. Cecha niezmienności oznacza, że gdy element został zdefiniowany w krotce, nie można go usunąć, ponownie przypisać ani edytować. Zapewnia to, że zadeklarowane wartości struktury danych nie są manipulowane ani zastępowane.
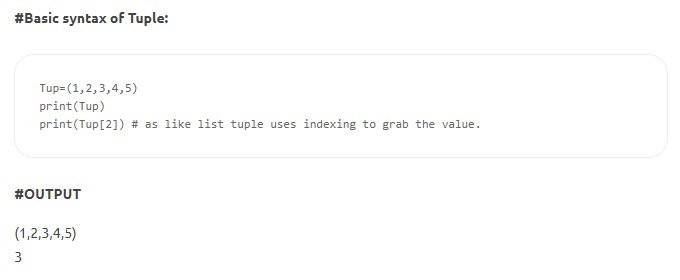
Źródło
- Słowniki — słowniki składają się z par klucz-wartość. „Klucz” identyfikuje element, a „wartość” przechowuje wartość przedmiotu. Dwukropek oddziela klucz od jego wartości. Pozycje są oddzielone przecinkami, a całość jest ujęta w nawiasy klamrowe. Chociaż klucze są niezmienne (liczby, ciągi znaków lub krotki), wartości mogą być dowolnego typu.
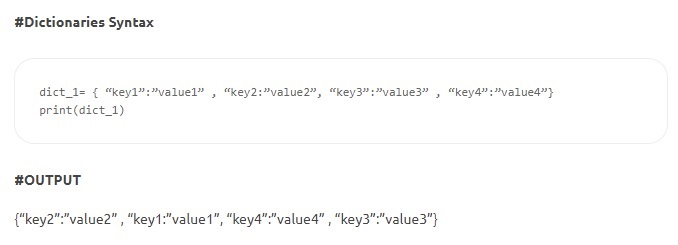
Źródło
- Zestawy – Zestawy to nieuporządkowana kolekcja unikalnych elementów. Podobnie jak Listy, Zestawy są zmienne i zapisywane w nawiasach kwadratowych, ale żadne dwie wartości nie mogą być takie same. Niektóre metody Set obejmują count(), index(), any(), all() itp.
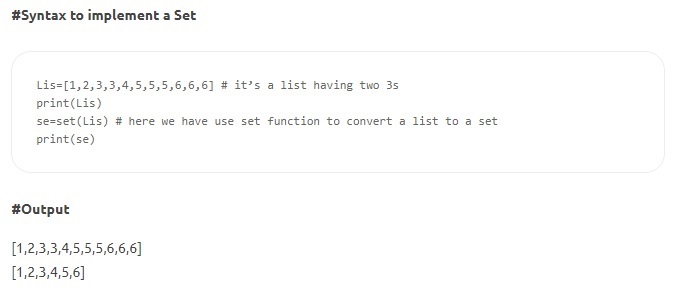
Źródło
- Listy a tablice — w Pythonie nie ma wbudowanej koncepcji tablic. Tablice można importować za pomocą pakietu NumPy przed ich zainicjowaniem. Aby dowiedzieć się więcej o NumPy, możesz zapoznać się z naszym samouczkiem python NumPy . Listy i tablice są w większości podobne, z wyjątkiem jednej różnicy – podczas gdy tablice są zbiorami tylko jednorodnych elementów, listy zawierają zarówno elementy jednorodne, jak i heterogeniczne.
Zamówienie: rodzaje drzewa binarnego
Zdefiniowane przez użytkownika struktury danych w Pythonie
Następnie w naszej dyskusji na temat struktur danych i algorytmów w Pythonie znajduje się krótki przegląd różnych struktur danych zdefiniowanych przez użytkownika:
- Stosy — stosy to liniowe struktury danych w Pythonie. Przechowywanie elementów w stosach opiera się na zasadach FILO lub Last-In/First-Out (LIFO). W Stacks dodaniu nowego elementu na jednym końcu towarzyszy usunięcie elementu z tego samego końca. Operacje „push” i „pop” służą odpowiednio do wstawiania i usuwania. Inne funkcje związane ze stosem to empty(), size() i top(). Stosy można implementować za pomocą modułów i struktur danych z biblioteki Pythona – list, collections.deque i queue.LifoQueue.
- Kolejka — podobnie jak stosy, kolejki są liniowymi strukturami danych. Jednak pozycje są przechowywane w oparciu o zasadę FIFO (pierwsze weszło/pierwsze wyszło). W kolejce najrzadziej dodany element jest usuwany jako pierwszy. Operacje związane z Kolejką obejmują Dodaj do kolejki (dodawanie elementów), Usuń z kolejki (usuwanie elementów), Przód i Tył. Podobnie jak Stacks, Queues mogą być zaimplementowane przy użyciu modułów i struktur danych z biblioteki Pythona – list, collections.deque i queue.
- Drzewo — drzewa są nieliniowymi strukturami danych w Pythonie i składają się z węzłów połączonych krawędziami. Właściwości drzewa są takie, że jeden węzeł jest wyznaczony jako węzeł główny, inny niż korzeń, każdy inny węzeł ma skojarzony węzeł rodzicielski, a każdy węzeł może mieć dowolną liczbę węzłów potomnych. Binarna struktura danych Tree to taka, której elementy mają nie więcej niż dwoje dzieci.
- Lista połączona — seria elementów danych połączonych ze sobą za pomocą łączy jest określana w Pythonie jako lista połączona. Jest to również liniowa struktura danych. Każdy element danych na połączonej liście jest połączony z innym za pomocą wskaźnika. Ponieważ biblioteka Pythona nie zawiera list połączonych, są one implementowane przy użyciu koncepcji węzłów. Połączone listy mają przewagę nad tablicami, ponieważ mają dynamiczny rozmiar i łatwość wstawiania/usuwania elementów.
- Wykres — wykres w Pythonie obrazowo przedstawia zestaw obiektów, z kilkoma parami obiektów połączonymi łączami. Wierzchołki reprezentują obiekty, które są ze sobą połączone, a połączenia łączące wierzchołki nazywane są krawędziami. Typ danych słownika Pythona może służyć do prezentowania wykresów. Zasadniczo „klucze” słownika reprezentują wierzchołki, a „wartości” wskazują połączenia lub krawędzie między wierzchołkami.
- HashMaps/Hash Tables — w tego typu strukturze danych funkcja Hash generuje adres lub wartość indeksu elementu danych. Wartość indeksu służy jako klucz do wartości danych umożliwiający szybszy dostęp do danych. Podobnie jak w typie danych słownika, tablice mieszające mają pary klucz-wartość, ale klucz generuje funkcja mieszająca.
Czym są algorytmy w Pythonie?
Algorytmy Pythona to zestaw instrukcji wykonywanych w celu uzyskania rozwiązania danego problemu. Ponieważ algorytmy nie są specyficzne dla języka, można je zaimplementować w kilku językach programowania. Żadne standardowe zasady nie kierują pisaniem algorytmów. Są one zależne od zasobów i problemów, ale mają wspólne konstrukcje kodu, takie jak kontrola przepływu (jeśli-inaczej) i pętle (do, while, for). W kolejnych sekcjach krótko omówimy algorytmy przechodzenia po drzewie, sortowania, wyszukiwania i wykresów.

Algorytmy przemierzania drzewa
Traversal to proces odwiedzania wszystkich węzłów Drzewa, zaczynając od węzła głównego. Drzewo można przemierzać na trzy różne sposoby:
– Przechodzenie w kolejności polega na odwiedzeniu najpierw poddrzewa po lewej stronie, następnie korzenia, a następnie prawego poddrzewa.
– W przechodzeniu w przedsprzedaży jako pierwszy odwiedzany jest węzeł główny, następnie lewe poddrzewo i na końcu prawe poddrzewo.
– W algorytmie post-order traversal najpierw odwiedzane jest lewe poddrzewo, następnie prawe poddrzewo, przy czym węzeł główny jest odwiedzany jako ostatni.
Dowiedz się więcej: Jak stworzyć idealne drzewo decyzyjne
Algorytmy sortowania
Algorytmy sortowania oznaczają sposoby uporządkowania danych w określonym formacie. Sortowanie zapewnia, że wyszukiwanie danych jest zoptymalizowane na wysokim poziomie i że dane są prezentowane w czytelnym formacie. Przyjrzyjmy się pięciu różnym typom algorytmów sortowania w Pythonie:
- Sortowanie bąbelkowe – ten algorytm opiera się na porównaniu, w którym następuje wielokrotna zamiana sąsiednich elementów, jeśli są one w niewłaściwej kolejności.
- Sortowanie przez scalanie — w oparciu o algorytm dziel i zwyciężaj, sortowanie przez scalanie dzieli tablicę na dwie połowy, sortuje je, a następnie łączy.
- Sortowanie przez wstawianie – To sortowanie rozpoczyna się od porównania i posortowania pierwszych dwóch elementów. Następnie trzeci element jest porównywany z dwoma poprzednio posortowanymi elementami i tak dalej.
- Shell Sort – Jest to forma sortowania przez wstawianie, ale tutaj sortowane są odległe elementy. Duża podlista danej listy jest sortowana, a rozmiar listy jest stopniowo zmniejszany, aż wszystkie elementy zostaną posortowane.
- Sortowanie wyboru — ten algorytm rozpoczyna się od znalezienia minimalnej wartości z listy elementów i umieszcza ją na posortowanej liście. Proces jest następnie powtarzany dla każdego z pozostałych elementów na liście, które nie są sortowane. Nowy element wchodzący na posortowaną listę jest porównywany z istniejącymi elementami i umieszczany na właściwej pozycji. Proces trwa do momentu posortowania wszystkich elementów.
Algorytmy wyszukiwania
Algorytmy wyszukiwania pomagają w sprawdzaniu i pobieraniu elementu z różnych struktur danych. Jeden typ algorytmu przeszukiwania stosuje metodę przeszukiwania sekwencyjnego, w której lista jest przeszukiwana sekwencyjnie, a każdy element jest sprawdzany (przeszukiwanie liniowe). W innym typie, przeszukiwaniu interwałowym, elementy są wyszukiwane w posortowanych strukturach danych (przeszukiwanie binarne). Przyjrzyjmy się niektórym przykładom:
- Wyszukiwanie liniowe — w tym algorytmie każdy element jest kolejno przeszukiwany jeden po drugim.
- Wyszukiwanie binarne — interwał wyszukiwania jest wielokrotnie dzielony na pół. Jeżeli poszukiwany element jest niższy niż środkowa składowa przedziału, przedział ten zostaje zawężony do dolnej połowy. W przeciwnym razie zwęża się do górnej połowy. Proces jest powtarzany aż do znalezienia wartości.
Algorytmy wykresów
Istnieją dwie metody przemierzania grafów przy użyciu ich krawędzi. To są:
- Depth-first Traversal (DFS) — w tym algorytmie graf jest przemierzany ruchem w głąb. Gdy jakakolwiek iteracja kończy się ślepym zaułkiem, stos jest używany do przejścia do następnego wierzchołka i rozpoczęcia wyszukiwania. DFS jest zaimplementowany w Pythonie przy użyciu ustawionych typów danych.
- BFS (Breadth-first Traversal) — w tym algorytmie graf jest przemieszczany wszerz. Gdy jakakolwiek iteracja kończy się ślepym zaułkiem, kolejka jest używana do przejścia do następnego wierzchołka i rozpoczęcia wyszukiwania. BFS jest zaimplementowany w Pythonie przy użyciu struktury danych kolejki.
Analiza algorytmu
- Analiza priorytetowa – reprezentuje teoretyczną analizę algorytmu przed jego wdrożeniem. Wydajność algorytmu mierzy się zakładając, że czynniki, takie jak szybkość procesora, są stałe i nie mają wpływu na algorytm.
- Analiza a posteriori – odnosi się do analizy empirycznej algorytmu po jego wdrożeniu. Do implementacji wybranego algorytmu wykorzystywany jest język programowania, a następnie jego wykonanie na komputerze. Ta analiza zbiera statystyki, takie jak czas i miejsce wymagane do działania algorytmu.
Wniosek
Niezależnie od tego, czy jesteś weteranem w programowaniu, czy jesteś w nim nowy, nie możesz ignorować struktur danych i algorytmów w Pythonie . Te pojęcia mają kluczowe znaczenie, gdy wykonujesz operacje na danych i potrzebujesz zoptymalizować przetwarzanie danych. Podczas gdy struktury danych pomagają w porządkowaniu informacji, algorytmy dostarczają wskazówek do rozwiązania problemu analizy danych. Razem umożliwiają informatykom przetwarzanie informacji podanych jako dane wejściowe.
Jeśli jesteś zainteresowany nauką o danych, sprawdź program IIIT-B i upGrad Executive PG w dziedzinie Data Science, który jest stworzony dla pracujących profesjonalistów i oferuje ponad 10 studiów przypadków i projektów, praktyczne warsztaty praktyczne, mentoring z ekspertami z branży, 1 -on-1 z mentorami branżowymi, ponad 400 godzin nauki i pomocy w pracy z najlepszymi firmami.
Ile dni zajmuje nauka struktur danych i algorytmów?
Jeśli chodzi o informatykę, struktury danych i algorytmy są uważane za najtrudniejsze ze wszystkich tematów. Ale są one naprawdę ważne dla każdego programisty. Jeśli spędzasz około 3-4 godzin dziennie, będziesz potrzebował co najmniej 6 do 8 tygodni na naukę struktur danych i algorytmów.
Nie ma tutaj sztywnej osi czasu, ponieważ będzie to całkowicie zależeć od twojego tempa i możliwości uczenia się. Jeśli jesteś dobry w uchwyceniu podstaw, łatwo będzie ci dogadać się ze szczegółowymi koncepcjami struktur danych i algorytmów.
Jakie są rodzaje algorytmu?
Algorytm to procedura krok po kroku, której należy przestrzegać, aby rozwiązać każdy problem. Różne problemy wymagają różnych algorytmów do rozwiązania problemu. Każdy programista wybiera algorytm do rozwiązania konkretnego problemu na podstawie wymagań i szybkości algorytmu.
Mimo to istnieją pewne najlepsze algorytmy, które programiści zwykle biorą pod uwagę przy rozwiązywaniu różnych problemów. Niektóre z dobrze znanych algorytmów to algorytm Brute-force, algorytm Greedy, algorytm randomizowany, algorytm programowania dynamicznego, algorytm rekurencyjny, algorytm dziel i zwyciężaj oraz algorytm cofania.
Jakie jest główne zastosowanie Pythona?
Python to język programowania ogólnego przeznaczenia, który służy do wykonywania różnych czynności. Najlepszą rzeczą w Pythonie jest to, że nie jest on powiązany z żadną konkretną aplikacją i można go używać zgodnie z własnymi wymaganiami. Ze względu na dostępność bibliotek, wszechstronność i łatwą do zrozumienia strukturę jest uważany za jeden z najczęściej używanych języków programowania wśród programistów.
Python jest głównie używany do tworzenia stron internetowych i oprogramowania. Poza tym służy również do automatyzacji zadań, wizualizacji danych i analizy danych. Python jest dość łatwy do nauczenia i dlatego nawet osoby nie będące programistami przyjmują ten język do organizowania finansów i wykonywania innych codziennych zadań.