
Estructuras de datos y algoritmos en Python: todo lo que necesita saber
Publicado: 2020-05-06Las estructuras de datos y los algoritmos en Python son dos de los conceptos más fundamentales en informática. Son herramientas indispensables para cualquier programador. Las estructuras de datos en Python se ocupan de la organización y el almacenamiento de datos en la memoria mientras un programa los procesa. Por otro lado, los algoritmos de Python se refieren al conjunto detallado de instrucciones que ayudan en el procesamiento de datos para un propósito específico.
Alternativamente, se puede decir que los algoritmos utilizan lógicamente diferentes estructuras de datos para resolver un problema particular de análisis de datos. Ya sea un problema del mundo real o una pregunta típica relacionada con la codificación, la comprensión de las estructuras de datos y los algoritmos en Python es crucial si desea encontrar una solución precisa. En este artículo, encontrará una discusión detallada de diferentes algoritmos y estructuras de datos de Python. Si está interesado en obtener más información sobre Python, consulte nuestros cursos de ciencia de datos .
Más información: Las seis estructuras de datos más utilizadas en R
Tabla de contenido
¿Qué son las estructuras de datos en Python?
Las estructuras de datos son una forma de organizar y almacenar datos; explican la relación entre los datos y varias operaciones lógicas que se pueden realizar en los datos. Hay muchas formas de clasificar las estructuras de datos. Una forma es categorizarlos en tipos de datos primitivos y no primitivos.
Mientras que los tipos de datos primitivos incluyen Integers, Float, Strings y Boolean, los tipos de datos no primitivos son Array, List, Tuples, Dictionary, Sets y Files. Algunos de estos tipos de datos no primitivos, como listas, tuplas, diccionarios y conjuntos, están integrados en Python. Hay otra categoría de estructuras de datos en Python que está definida por el usuario; es decir, los usuarios los definen. Estos incluyen Stack, Queue, Linked List, Tree, Graph y HashMap.
Estructuras de datos primitivas
Estas son las estructuras de datos básicas en Python que contienen valores de datos puros y simples y sirven como bloques de construcción para manipular datos. Hablemos de los cuatro tipos primitivos de variables en Python:
- Enteros: este tipo de datos se utiliza para representar datos numéricos, es decir, números enteros positivos o negativos sin punto decimal. Diga, -1, 3 o 6.
- Flotante: Flotante significa 'número real de coma flotante'. Se usa para representar números racionales, generalmente con un punto decimal como 2.0 o 5.77. Dado que Python es un lenguaje de programación de tipo dinámico, el tipo de datos que almacena un objeto es mutable y no es necesario indicar el tipo de su variable explícitamente.
- Cadena: este tipo de datos denota una colección de alfabetos, palabras o caracteres alfanuméricos. Se crea incluyendo una serie de caracteres dentro de un par de comillas simples o dobles. Para concatenar dos o más Strings, se les puede aplicar la operación '+'. Repetir, empalmar, usar mayúsculas y recuperar son algunas de las otras operaciones de cadenas en Python. Ejemplo: 'azul', 'rojo', etc.
- Booleano: este tipo de datos es útil en expresiones de comparación y condicionales y puede tomar los valores VERDADERO o FALSO.
Saber más: Marcos de datos en Python
Estructuras de datos no primitivas incorporadas
A diferencia de las estructuras de datos primitivas, los tipos de datos no primitivos no solo almacenan valores, sino también una colección de valores en diferentes formatos. Echemos un vistazo a las estructuras de datos no primitivas en Python:
- Listas: esta es la estructura de datos más versátil de Python y está escrita como una lista de elementos separados por comas encerrados entre corchetes. Una lista puede constar de elementos heterogéneos y homogéneos. Algunos de los métodos aplicables en una lista son index(), append(), extend(), insert(), remove(), pop(), etc. Las listas son mutables; es decir, se puede cambiar su contenido, manteniendo intacta la identidad.
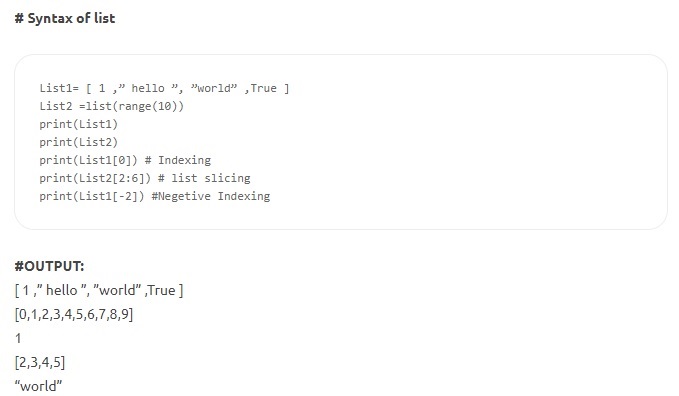
Fuente
- Tuplas: las tuplas son similares a las listas pero son inmutables. Además, a diferencia de las listas, las tuplas se declaran entre paréntesis en lugar de corchetes. La característica de inmutabilidad denota que una vez que se ha definido un elemento en una Tupla, no se puede eliminar, reasignar ni editar. Garantiza que los valores declarados de la estructura de datos no se manipulen ni anulen.
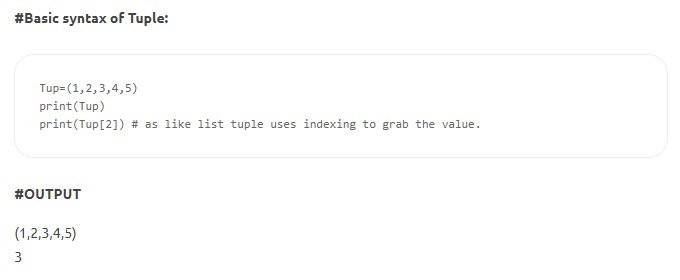
Fuente
- Diccionarios: los diccionarios constan de pares clave-valor. La 'clave' identifica un artículo y el 'valor' almacena el valor del artículo. Dos puntos separan la clave de su valor. Los elementos están separados por comas, con todo encerrado entre corchetes. Si bien las claves son inmutables (números, cadenas o tuplas), los valores pueden ser de cualquier tipo.
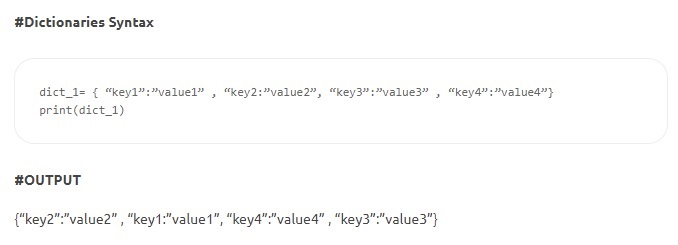
Fuente
- Conjuntos: los conjuntos son una colección desordenada de elementos únicos. Al igual que las listas, los conjuntos son mutables y se escriben entre corchetes, pero dos valores no pueden ser iguales. Algunos métodos Set incluyen count(), index(), any(), all(), etc.
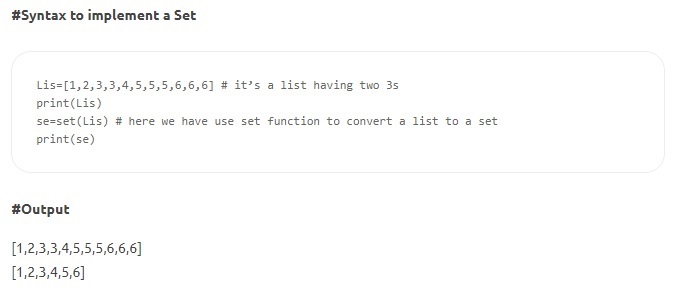
Fuente
- Listas frente a matrices: no hay un concepto integrado de matrices en Python. Los arreglos se pueden importar usando el paquete NumPy antes de inicializarlos. Para saber más sobre NumPy, puede consultar nuestro tutorial de python NumPy . Las listas y los arreglos son en su mayoría similares, excepto por una diferencia: mientras que los arreglos son colecciones de solo elementos homogéneos, las listas incluyen elementos tanto homogéneos como heterogéneos.
Pago: Tipos de árbol binario
Estructuras de datos definidas por el usuario en Python
Lo siguiente en nuestra discusión sobre estructuras de datos y algoritmos en Python es una breve descripción de las diferentes estructuras de datos definidas por el usuario:
- Pilas: las pilas son estructuras de datos lineales en Python. El almacenamiento de elementos en pilas se basa en los principios de primero en entrar/último en salir (FILO) o último en entrar/primero en salir (LIFO). En Stacks, la adición de un nuevo elemento en un extremo va acompañada de la eliminación de un elemento del mismo extremo. Las operaciones 'push' y 'pop' se utilizan para inserciones y eliminaciones, respectivamente. Otras funciones relacionadas con Stack son empty(), size() y top(). Las pilas se pueden implementar utilizando módulos y estructuras de datos de la biblioteca de Python: list, collections.deque y queue.LifoQueue.
- Cola: similar a las pilas, las colas son estructuras de datos lineales. Sin embargo, los artículos se almacenan según el principio de primero en entrar/primero en salir (FIFO). En una cola, el elemento que se agregó menos recientemente se elimina primero. Las operaciones relacionadas con Queue incluyen Enqueue (agregar elementos), Dequeue (eliminar elementos), Frontal y Posterior. Al igual que las pilas, las colas se pueden implementar utilizando módulos y estructuras de datos de la biblioteca de Python: list, collections.deque y queue.
- Árbol: los árboles son estructuras de datos no lineales en Python y consisten en nodos conectados por bordes. Las propiedades de un árbol son que un nodo se designa como nodo raíz, que no sea la raíz, todos los demás nodos tienen un nodo principal asociado y cada nodo puede tener un número arbitrario de nodos secundarios. Una estructura de datos de árbol binario es aquella cuyos elementos no tienen más de dos hijos.
- Lista vinculada: una serie de elementos de datos unidos a través de enlaces se denomina Lista vinculada en Python. También es una estructura de datos lineal. Cada elemento de datos en una Lista Vinculada está conectado a otro utilizando un puntero. Dado que la biblioteca de Python no contiene listas enlazadas, se implementan utilizando el concepto de nodos. Las Listas Enlazadas tienen la ventaja sobre los Arrays de tener un tamaño dinámico, con facilidad para insertar/eliminar elementos.
- Gráfico: un gráfico en Python representa pictóricamente un conjunto de objetos, con algunos pares de objetos conectados por enlaces. Los vértices representan los objetos que están interconectados, y los enlaces que unen los vértices se denominan aristas. El tipo de datos del diccionario de Python se puede utilizar para presentar gráficos. En esencia, las 'claves' del diccionario representan los vértices, y los 'valores' indican las conexiones o los bordes entre los vértices.
- HashMaps/Hash Tables: en este tipo de estructura de datos, una función Hash genera la dirección o el valor de índice del elemento de datos. El valor del índice sirve como clave para el valor de los datos, lo que permite un acceso más rápido a los datos. Al igual que en el tipo de datos del diccionario, las tablas hash tienen pares clave-valor, pero una función hash genera la clave.
¿Qué son los algoritmos en Python?
Los algoritmos de Python son un conjunto de instrucciones que se ejecutan para obtener la solución a un problema dado. Dado que los algoritmos no son específicos del idioma, se pueden implementar en varios lenguajes de programación. No hay reglas estándar que guíen la escritura de algoritmos. Dependen de los recursos y los problemas, pero comparten algunas construcciones de código comunes, como el control de flujo (if-else) y los bucles (do, while, for). En las siguientes secciones, analizaremos brevemente los algoritmos de recorrido de árboles, clasificación, búsqueda y gráficos.

Algoritmos transversales de árboles
Recorrido es un proceso de visitar todos los nodos de un árbol, comenzando desde el nodo raíz. Un árbol se puede recorrer de tres maneras diferentes:
– El recorrido en orden implica visitar primero el subárbol de la izquierda, seguido de la raíz y luego el subárbol de la derecha.
– En el recorrido de preorden, el primer nodo que se visita es el nodo raíz, seguido del subárbol izquierdo y, finalmente, el subárbol derecho.
– En el algoritmo transversal posterior al orden, primero se visita el subárbol izquierdo, luego se visita el subárbol derecho y el nodo raíz se visita en último lugar.
Más información: Cómo crear un árbol de decisión perfecto
Algoritmos de clasificación
Los algoritmos de clasificación denotan las formas de organizar los datos en un formato particular. La clasificación garantiza que la búsqueda de datos se optimice a un alto nivel y que los datos se presenten en un formato legible. Veamos los cinco tipos diferentes de algoritmos de clasificación en Python:
- Bubble Sort: este algoritmo se basa en la comparación en la que hay un intercambio repetido de elementos adyacentes si están en un orden incorrecto.
- Merge Sort: basado en el algoritmo divide y vencerás, Merge sort divide la matriz en dos mitades, las ordena y luego las combina.
- Clasificación por inserción: esta clasificación comienza con la comparación y clasificación de los dos primeros elementos. Luego, el tercer elemento se compara con los dos elementos previamente clasificados y así sucesivamente.
- Shell Sort: es una forma de ordenación por inserción, pero aquí se ordenan los elementos lejanos. Se ordena una gran sublista de una lista dada, y el tamaño de la lista se reduce progresivamente hasta que se ordenan todos los elementos.
- Clasificación de selección: este algoritmo comienza por encontrar el valor mínimo de una lista de elementos y lo coloca en una lista ordenada. A continuación, el proceso se repite para cada uno de los elementos restantes de la lista que no está ordenada. El nuevo elemento que ingresa a la lista ordenada se compara con sus elementos existentes y se coloca en la posición correcta. El proceso continúa hasta que se ordenan todos los elementos.
Algoritmos de búsqueda
Los algoritmos de búsqueda ayudan a verificar y recuperar un elemento de diferentes estructuras de datos. Un tipo de algoritmo de búsqueda aplica el método de búsqueda secuencial donde la lista se recorre secuencialmente y se verifica cada elemento (búsqueda lineal). En otro tipo, la búsqueda por intervalos, los elementos se buscan en estructuras de datos ordenados (búsqueda binaria). Veamos algunos de los ejemplos:
- Búsqueda lineal: en este algoritmo, cada elemento se busca secuencialmente uno por uno.
- Búsqueda binaria: el intervalo de búsqueda se divide repetidamente por la mitad. Si el elemento a buscar es más bajo que el componente central del intervalo, el intervalo se reduce a la mitad inferior. De lo contrario, se reduce a la mitad superior. El proceso se repite hasta que se encuentra el valor.
Algoritmos gráficos
Hay dos métodos para recorrer gráficos usando sus bordes. Estos son:
- Recorrido primero en profundidad (DFS): en este algoritmo, un gráfico se recorre en un movimiento hacia la profundidad. Cuando cualquier iteración se enfrenta a un callejón sin salida, se utiliza una pila para ir al siguiente vértice y comenzar una búsqueda. DFS se implementa en Python utilizando los tipos de datos establecidos.
- Recorrido primero en anchura (BFS): en este algoritmo, un gráfico se recorre en un movimiento hacia la anchura. Cuando cualquier iteración se enfrenta a un callejón sin salida, se utiliza una cola para ir al siguiente vértice y comenzar una búsqueda. BFS se implementa en Python utilizando la estructura de datos de la cola.
Análisis de algoritmos
- Un análisis a priori: representa un análisis teórico del algoritmo antes de su implementación. La eficiencia de un algoritmo se mide suponiendo que los factores, como la velocidad del procesador, son constantes y no tienen consecuencias en el algoritmo.
- Un Análisis Posterior – Se refiere al análisis empírico del algoritmo después de su implementación. Se utiliza un lenguaje de programación para implementar el algoritmo seleccionado, seguido de su ejecución en una computadora. Este análisis recopila estadísticas, como el tiempo y el espacio necesarios para que se ejecute el algoritmo.
Conclusión
Ya sea que sea un veterano en la programación o un principiante, no puede ignorar las estructuras de datos y los algoritmos en Python . Estos conceptos son cruciales cuando realiza operaciones en datos y necesita optimizar el procesamiento de datos. Mientras que las estructuras de datos ayudan a organizar la información, los algoritmos proporcionan las pautas para resolver el problema del análisis de datos. Juntos, proporcionan a los científicos informáticos una forma de procesar la información proporcionada como datos de entrada.
Si tiene curiosidad por aprender sobre ciencia de datos, consulte el Programa ejecutivo PG en ciencia de datos de IIIT-B y upGrad, creado para profesionales que trabajan y ofrece más de 10 estudios de casos y proyectos, talleres prácticos, tutoría con expertos de la industria, 1 -on-1 con mentores de la industria, más de 400 horas de aprendizaje y asistencia laboral con las mejores empresas.
¿Cuántos días se tarda en aprender estructuras de datos y algoritmos?
Cuando se trata de informática, las estructuras de datos y los algoritmos se consideran los temas más difíciles de todos. Pero, son realmente importantes para aprender para cada programador. Si dedica aproximadamente de 3 a 4 horas diarias, necesitará al menos de 6 a 8 semanas para aprender estructuras de datos y algoritmos.
No hay una línea de tiempo rígida aquí porque dependerá completamente de su ritmo y capacidad de aprendizaje. Si es bueno para comprender los fundamentos, le resultará bastante fácil familiarizarse con los conceptos profundos de estructuras de datos y algoritmos.
¿Cuáles son los diferentes tipos de algoritmo?
Un algoritmo es un procedimiento paso a paso que debe seguirse para resolver cualquier problema. Diferentes problemas necesitan diferentes algoritmos para resolver el problema. Cada programador selecciona un algoritmo para resolver un problema particular en función de los requisitos y la velocidad del algoritmo.
Aún así, hay ciertos algoritmos superiores que los programadores suelen considerar para resolver diferentes problemas. Algunos de los algoritmos más conocidos son el algoritmo de fuerza bruta, el algoritmo codicioso, el algoritmo aleatorio, el algoritmo de programación dinámica, el algoritmo recursivo, el algoritmo Divide & Conquer y el algoritmo Backtracking.
¿Cuál es el principal uso de Python?
Python es un lenguaje de programación de propósito general que se utiliza para realizar diferentes actividades. Lo mejor de Python es que no está vinculado a ninguna aplicación específica y puede usarlo según sus requisitos. Debido a la disponibilidad de bibliotecas, versatilidad y estructura fácil de entender, se considera uno de los lenguajes de programación más utilizados entre los desarrolladores.
Python se utiliza principalmente para el desarrollo de sitios web y software. Aparte de eso, también se utiliza para la automatización de tareas, la visualización de datos y el análisis de datos. Python es bastante fácil de aprender, y es por eso que incluso los no programadores están adoptando este lenguaje para organizar las finanzas y realizar otras tareas cotidianas.