
Pythonのデータ構造とアルゴリズム:知っておくべきことすべて
公開: 2020-05-06Pythonのデータ構造とアルゴリズムは、コンピューターサイエンスの最も基本的な概念の2つです。 これらは、あらゆるプログラマーにとって不可欠なツールです。 Pythonのデータ構造は、プログラムがデータを処理している間、メモリ内のデータの編成と保存を処理します。 一方、 Pythonアルゴリズムは、特定の目的のためのデータの処理に役立つ一連の詳細な命令を参照します。
あるいは、データ分析の特定の問題を解決するために、アルゴリズムによってさまざまなデータ構造が論理的に利用されていると言えます。 現実の問題であろうと、典型的なコーディング関連の質問であろうと、正確な解決策を考え出すには、Pythonのデータ構造とアルゴリズムを理解することが重要です。 この記事では、さまざまなPythonアルゴリズムとデータ構造について詳しく説明します。 Pythonについて詳しく知りたい場合は、 データサイエンスコースをご覧ください。
詳細: Rで最も一般的に使用される6つのデータ構造
目次
Pythonのデータ構造とは何ですか?
データ構造は、データを整理および保存する方法です。 データと、データに対して実行できるさまざまな論理演算との関係を説明します。 データ構造を分類する方法はたくさんあります。 1つの方法は、それらをプリミティブデータ型と非プリミティブデータ型に分類することです。
プリミティブデータ型には整数、浮動小数点数、文字列、ブール値が含まれますが、非プリミティブデータ型は配列、リスト、タプル、辞書、セット、ファイルです。 List、Tuples、Dictionaries、Setsなど、これらの非プリミティブデータ型の一部はPythonに組み込まれています。 Pythonには、ユーザー定義のデータ構造の別のカテゴリがあります。 つまり、ユーザーがそれらを定義します。 これらには、スタック、キュー、リンクリスト、ツリー、グラフ、およびハッシュマップが含まれます。
プリミティブデータ構造
これらは、純粋で単純なデータ値を含むPythonの基本的なデータ構造であり、データを操作するための構成要素として機能します。 Pythonの4つのプリミティブ型の変数について話しましょう。
- 整数–このデータ型は、数値データ、つまり小数点なしの正または負の整数を表すために使用されます。 -1、3、または6と言います。
- Float – Floatは、「浮動小数点の実数」を意味します。 有理数を表すために使用され、通常は2.0や5.77などの小数点が含まれます。 Pythonは動的型付けされたプログラミング言語であるため、オブジェクトが格納するデータ型は変更可能であり、変数の型を明示的に指定する必要はありません。
- 文字列–このデータ型は、アルファベット、単語、または英数字のコレクションを示します。 これは、二重引用符または一重引用符のペア内に一連の文字を含めることによって作成されます。 2つ以上の文字列を連結するために、「+」操作をそれらに適用できます。 繰り返し、スプライシング、大文字化、および取得は、Pythonの他の文字列操作の一部です。 例:「青」、「赤」など。
- ブール値–このデータ型は、比較式および条件式で役立ち、TRUEまたはFALSEの値をとることができます。
詳細: Pythonのデータフレーム
組み込みの非プリミティブデータ構造
プリミティブデータ構造とは対照的に、非プリミティブデータ型は値を格納するだけでなく、さまざまな形式の値のコレクションを格納します。 Pythonの非プリミティブデータ構造を見てみましょう。
- リスト–これはPythonで最も用途の広いデータ構造であり、角かっこで囲まれたコンマ区切りの要素のリストとして記述されます。 リストは、異種要素と同種要素の両方で構成できます。 リストに適用できるメソッドには、index()、append()、extend()、insert()、remove()、pop()などがあります。リストは変更可能です。 つまり、IDをそのまま維持して、コンテンツを変更できます。
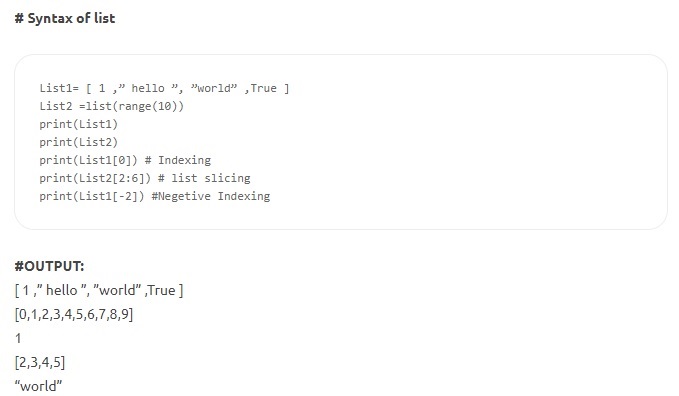
ソース
- タプル–タプルはリストに似ていますが、不変です。 また、リストとは異なり、タプルは角括弧ではなく括弧内で宣言されます。 不変性の機能は、要素がタプルで定義されると、削除、再割り当て、または編集できないことを意味します。 これにより、データ構造の宣言された値が操作またはオーバーライドされないことが保証されます。
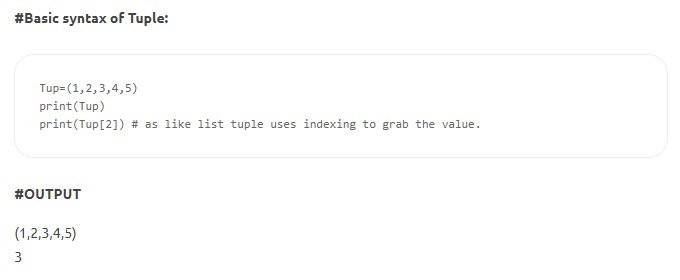
ソース
- ディクショナリ–ディクショナリはキーと値のペアで構成されます。 「キー」はアイテムを識別し、「値」はアイテムの値を格納します。 コロンは、キーとその値を区切ります。 項目はコンマで区切られ、全体が中括弧で囲まれています。 キーは不変(数値、文字列、またはタプル)ですが、値は任意のタイプにすることができます。
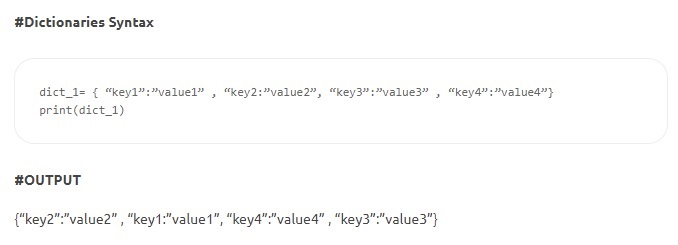
ソース
- セット–セットは、一意の要素の順序付けられていないコレクションです。 リストと同様に、セットは変更可能で角かっこで囲まれていますが、2つの値を同じにすることはできません。 一部のSetメソッドには、count()、index()、any()、all()などが含まれます。
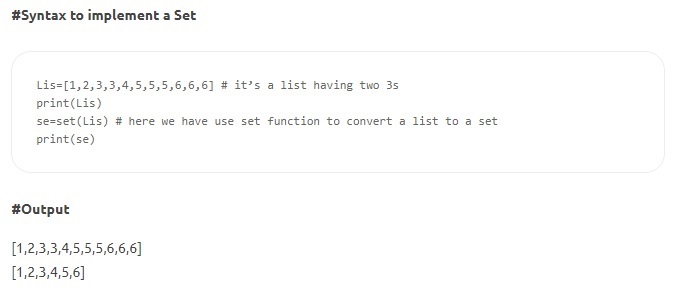
ソース
- リストと配列–Pythonには配列の概念が組み込まれていません。 配列は、初期化する前にNumPyパッケージを使用してインポートできます。 NumPyの詳細については、PythonのNumPyチュートリアルをご覧ください。 リストと配列は、1つの違いを除いてほとんど同じです。配列は同種の要素のみのコレクションですが、リストには同種のアイテムと異種のアイテムの両方が含まれます。
チェックアウト:二分木の種類
Pythonのユーザー定義データ構造
Pythonのデータ構造とアルゴリズムに関する次の説明は、さまざまなユーザー定義のデータ構造の概要です。
- スタック–スタックはPythonの線形データ構造です。 スタックへのアイテムの保存は、後入れ先出し(FILO)または後入れ先出し(LIFO)の原則に基づいています。 スタックでは、一方の端に新しい要素を追加すると、同じ端から要素が削除されます。 操作「push」および「pop」は、それぞれ挿入および削除に使用されます。 Stackに関連する他の関数は、empty()、size()、top()です。 スタックは、Pythonライブラリのモジュールとデータ構造(list、collections.deque、queue.LifoQueue)を使用して実装できます。
- キュー–スタックと同様に、キューは線形データ構造です。 ただし、アイテムは先入れ先出し(FIFO)の原則に基づいて保存されます。 キューでは、最後に追加されたアイテムが最初に削除されます。 キューに関連する操作には、エンキュー(要素の追加)、デキュー(要素の削除)、フロントおよびリアが含まれます。 スタックと同様に、キューはPythonライブラリのモジュールとデータ構造(list、collections.deque、queue)を使用して実装できます。
- ツリー–ツリーはPythonの非線形データ構造であり、エッジで接続されたノードで構成されます。 ツリーのプロパティは、ルート以外の1つのノードがルートノードとして指定され、他のすべてのノードには関連する親ノードがあり、各ノードには任意の数の子ノードを含めることができます。 二分木データ構造は、要素に2つ以下の子を持つ構造です。
- リンクリスト–リンクを介して結合された一連のデータ要素は、Pythonではリンクリストと呼ばれます。 これは線形データ構造でもあります。 リンクリスト内の各データ要素は、ポインタを使用して別のデータ要素に接続されます。 Pythonライブラリにはリンクリストが含まれていないため、ノードの概念を使用して実装されます。 リンクリストには、要素の挿入/削除が容易で、動的なサイズを持つという点で配列よりも優れています。
- グラフ– Pythonのグラフは、いくつかのオブジェクトのペアがリンクで接続されたオブジェクトのセットを絵で表したものです。 頂点は相互接続されたオブジェクトを表し、頂点を結合するリンクはエッジと呼ばれます。 Pythonディクショナリのデータ型を使用して、グラフを表示できます。 本質的に、辞書の「キー」は頂点を表し、「値」は頂点間の接続またはエッジを示します。
- HashMaps / Hash Tables –このタイプのデータ構造では、Hash関数がデータ要素のアドレスまたはインデックス値を生成します。 インデックス値はデータ値のキーとして機能し、データへのより高速なアクセスを可能にします。 ディクショナリデータ型と同様に、ハッシュテーブルにはキーと値のペアがありますが、ハッシュ関数がキーを生成します。
Pythonのアルゴリズムとは何ですか?
Pythonアルゴリズムは、特定の問題の解決策を得るために実行される一連の命令です。 アルゴリズムは言語固有ではないため、いくつかのプログラミング言語で実装できます。 アルゴリズムの作成をガイドする標準ルールはありません。 これらはリソースと問題に依存しますが、フロー制御(if-else)やループ(do、while、for)などのいくつかの一般的なコード構造を共有します。 次のセクションでは、ツリートラバーサル、ソート、検索、およびグラフアルゴリズムについて簡単に説明します。

ツリートラバーサルアルゴリズム
トラバーサルは、ルートノードから開始してツリーのすべてのノードにアクセスするプロセスです。 ツリーは、次の3つの方法でトラバースできます。
–順序どおりのトラバーサルでは、最初に左側のサブツリーにアクセスし、次にルートにアクセスし、次に右側のサブツリーにアクセスします。
–プレオーダートラバーサルでは、最初にアクセスされるのはルートノードで、次に左側のサブツリー、最後に右側のサブツリーが続きます。
–ポストオーダートラバーサルアルゴリズムでは、最初に左側のサブツリーにアクセスし、次に右側のサブツリーにアクセスし、最後にルートノードにアクセスします。
詳細:完璧なディシジョンツリーを作成する方法
並べ替えアルゴリズム
並べ替えアルゴリズムは、特定の形式でデータを配置する方法を示します。 並べ替えにより、データ検索が高レベルに最適化され、データが読み取り可能な形式で表示されるようになります。 Pythonの5種類の並べ替えアルゴリズムを見てみましょう。
- バブルソート–このアルゴリズムは、隣接する要素の順序が正しくない場合に、隣接する要素の交換が繰り返される比較に基づいています。
- マージソート–分割統治アルゴリズムに基づいて、マージソートは配列を2つに分割し、それらをソートしてから結合します。
- 挿入ソート–このソートは、最初の2つの要素を比較してソートすることから始まります。 次に、3番目の要素が以前にソートされた2つの要素と比較されます。
- シェルソート–挿入ソートの一種ですが、ここでは、遠くの要素がソートされています。 特定のリストの大きなサブリストが並べ替えられ、すべての要素が並べ替えられるまで、リストのサイズが徐々に小さくなります。
- 選択ソート–このアルゴリズムは、要素のリストから最小値を見つけて、それをソートされたリストに入れることから始まります。 次に、ソートされていないリスト内の残りの要素ごとに、このプロセスが繰り返されます。 ソートされたリストに入る新しい要素は、既存の要素と比較され、正しい位置に配置されます。 このプロセスは、すべての要素がソートされるまで続きます。
検索アルゴリズム
検索アルゴリズムは、さまざまなデータ構造から要素をチェックおよび取得するのに役立ちます。 1つのタイプの検索アルゴリズムは、リストが順次トラバースされ、すべての要素がチェックされる順次検索の方法を適用します(線形検索)。 別のタイプである区間検索では、要素はソートされたデータ構造で検索されます(二分探索)。 いくつかの例を見てみましょう。
- 線形検索–このアルゴリズムでは、各アイテムが1つずつ順番に検索されます。
- 二分探索–検索間隔は繰り返し半分に分割されます。 検索する要素が間隔の中央成分よりも低い場合、間隔は下半分に狭められます。 それ以外の場合は、上半分に絞り込まれます。 値が見つかるまでこのプロセスが繰り返されます。
グラフアルゴリズム
グラフのエッジを使用してグラフをトラバースする方法は2つあります。 これらは:
- 深さ優先トラバーサル(DFS)–このアルゴリズムでは、グラフは深さ方向にトラバースされます。 反復が行き止まりに直面すると、スタックを使用して次の頂点に移動し、検索を開始します。 DFSは、設定されたデータ型を使用してPythonで実装されます。
- 幅優先探索(BFS)–このアルゴリズムでは、グラフが幅優先で移動します。 反復が行き止まりに直面すると、キューを使用して次の頂点に移動し、検索を開始します。 BFSは、キューデータ構造を使用してPythonで実装されます。
アルゴリズム分析
- 事前分析–これは、実装前のアルゴリズムの理論的分析を表します。 アルゴリズムの効率は、プロセッサ速度などの要因が一定であり、アルゴリズムに影響を与えないと仮定して測定されます。
- 事後分析–これは、実装後のアルゴリズムの経験的分析を指します。 プログラミング言語は、選択されたアルゴリズムを実装するために使用され、その後、コンピューター上で実行されます。 この分析は、アルゴリズムの実行に必要な時間やスペースなどの統計を収集します。
結論
プログラミングのベテランであろうと初心者であろうと、Pythonのデータ構造とアルゴリズムを無視することはできません。 これらの概念は、データに対して操作を実行するときに重要であり、データ処理を最適化する必要があります。 データ構造は情報の整理に役立ちますが、アルゴリズムはデータ分析の問題を解決するためのガイドラインを提供します。 一緒に、それらは入力データとして与えられた情報を処理するためのコンピュータ科学者への方法を提供します。
データサイエンスについて知りたい場合は、IIIT-B&upGradのデータサイエンスのエグゼクティブPGプログラムをチェックしてください。これは、働く専門家向けに作成され、10以上のケーススタディとプロジェクト、実践的なハンズオンワークショップ、業界の専門家とのメンターシップを提供します。1業界のメンターとの1対1、400時間以上の学習、トップ企業との仕事の支援。
データ構造とアルゴリズムを学ぶのに何日かかりますか?
コンピュータサイエンスに関して言えば、データ構造とアルゴリズムはすべての中で最も難しいトピックであると考えられています。 しかし、それらはすべてのプログラマーにとって学ぶことが非常に重要です。 毎日約3〜4時間費やしている場合は、データ構造とアルゴリズムの学習に少なくとも6〜8週間かかります。
それはあなたのペースと学習能力に完全に依存するので、ここに厳格なタイムラインはありません。 基本を理解するのが得意であれば、データ構造とアルゴリズムの詳細な概念を理解するのは非常に簡単です。
アルゴリズムの種類は何ですか?
アルゴリズムは、問題を解決するために従わなければならない段階的な手順です。 問題が異なれば、問題を解決するためにさまざまなアルゴリズムが必要になります。 すべてのプログラマーは、アルゴリズムの要件と速度に基づいて、特定の問題を解決するためのアルゴリズムを選択します。
それでも、プログラマーがさまざまな問題を解決するために通常検討する特定の上位アルゴリズムがあります。 よく知られているアルゴリズムには、ブルートフォースアルゴリズム、欲張りアルゴリズム、ランダム化アルゴリズム、動的プログラミングアルゴリズム、再帰的アルゴリズム、除算と征服アルゴリズム、およびバックトラッキングアルゴリズムがあります。
Pythonの主な用途は何ですか?
Pythonは、さまざまなアクティビティを実行するために使用される汎用プログラミング言語です。 Pythonの最も優れている点は、特定のアプリケーションにバインドされておらず、要件に応じて使用できることです。 ライブラリの可用性、汎用性、および理解しやすい構造により、開発者の間で最も使用されているプログラミング言語の1つと見なされています。
Pythonは、主にWebサイトやソフトウェアの開発に使用されます。 それ以外にも、タスクの自動化、データの視覚化、データ分析にも使用されます。 Pythonは非常に簡単に習得できます。そのため、プログラマーでなくても、財務の整理やその他の日常的なタスクの実行にこの言語を採用しています。