
Algorytmy widzenia komputerowego: wszystko, co chciałeś wiedzieć [2022]
Opublikowany: 2021-01-01Poznaj algorytmy, które umożliwiają komputerom postrzeganie
Spis treści
Wstęp
Słowo komputerowe widzenie oznacza zdolność komputera do widzenia i postrzegania otoczenia. Wiele aplikacji obejmuje wizję komputerową — wykrywanie i rozpoznawanie obiektów, samojezdne samochody, rozpoznawanie twarzy, śledzenie piłki, tagowanie zdjęć i wiele innych. Zanim zagłębimy się w technicznych żargonach, najpierw omówmy cały potok wizji komputerowej.
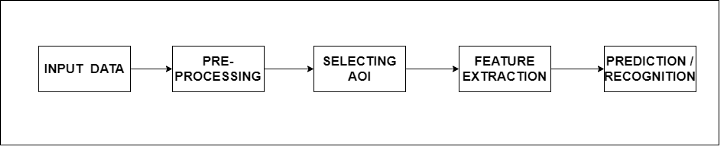
Cały rurociąg podzielony jest na 5 podstawowych etapów, z których każdy ma określoną funkcję. Po pierwsze, dane wejściowe są potrzebne algorytmowi do przetworzenia, które mogą mieć postać obrazu lub strumienia obrazu (ramki obrazu). Następnym krokiem jest wstępne przetwarzanie. Na tym etapie do przychodzącego obrazu (obrazów) są stosowane funkcje, aby algorytm mógł lepiej zrozumieć obraz.
Niektóre funkcje obejmują redukcję szumów, skalowanie obrazu, dylatację i erozję, usuwanie plam barwnych itp. Następnym krokiem jest wybór obszaru zainteresowania lub obszaru zainteresowania. Pod tym kryją się algorytmy wykrywania obiektów i segmentacji obrazu. Co więcej, mamy ekstrakcję funkcji, która oznacza pobieranie odpowiednich informacji/funkcji z obrazów, które są niezbędne do osiągnięcia celu końcowego.
Ostatnim krokiem jest rozpoznawanie lub przewidywanie, gdzie rozpoznajemy obiekty w danej klatce obrazów lub przewidujemy prawdopodobieństwo wystąpienia obiektu w danej klatce obrazu.
Przykład
Przyjrzyjmy się rzeczywistemu zastosowaniu potoku wizji komputerowej. Rozpoznawanie mimiki twarzy to aplikacja wizji komputerowej, która jest wykorzystywana przez wiele laboratoriów badawczych, aby zorientować się, jaki wpływ ma dany produkt na jego użytkowników. Ponownie mamy dane wejściowe, do których stosujemy algorytmy przetwarzania wstępnego.

Następny krok obejmuje wykrywanie twarzy w określonej ramce i przycinanie tej części ramki. Gdy to zostanie osiągnięte, rozpoznawane są punkty orientacyjne twarzy, takie jak usta, oczy, nos itp. — kluczowe funkcje rozpoznawania emocji.

Na koniec model predykcyjny (model wytrenowany) klasyfikuje obrazy na podstawie cech wyodrębnionych w krokach pośrednich.
Algorytmy
Zanim zacznę wspominać o algorytmach w wizji komputerowej, chciałbym podkreślić termin „Częstotliwość”. Częstotliwość obrazu to tempo zmian intensywności. Obrazy o wysokiej częstotliwości mają duże zmiany intensywności. Obraz o niskiej częstotliwości jest stosunkowo jednorodny pod względem jasności lub intensywność zmienia się powoli.
Po zastosowaniu transformacji Fouriera do obrazu otrzymujemy widmo wielkości, które dostarcza informacji o częstotliwości obrazu. Skoncentrowany punkt w środku obrazu w domenie częstotliwości oznacza, że na obrazie występuje wiele składowych o niskiej częstotliwości. Do składowych o wysokiej częstotliwości należą — krawędzie, narożniki, paski itp. Wiemy, że obraz jest funkcją xiyf(x,y). Aby zmierzyć zmianę intensywności, po prostu bierzemy pochodną funkcji f(x,y).
Trzeźwy filtr
Operator Sobela jest używany w przetwarzaniu obrazu i wizji komputerowej do algorytmów wykrywania krawędzi. Filtr tworzy obraz podkreślający krawędzie. Oblicza przybliżenie nachylenia/gradientu funkcji intensywności obrazu. W każdym pikselu obrazu wyjście operatora Sobela jest zarówno odpowiednim wektorem gradientu, jak i normą tego wektora.
Operator Sobela splata obraz za pomocą małego filtru o wartościach całkowitych w kierunku poziomym i pionowym. To sprawia, że operator jest tani pod względem złożoności obliczeń. Filtr Sx wykrywa krawędzie w kierunku poziomym, a filtr Sy wykrywa krawędzie w kierunku pionowym. Jest to filtr górnoprzepustowy.
Stosowanie Sx do obrazu
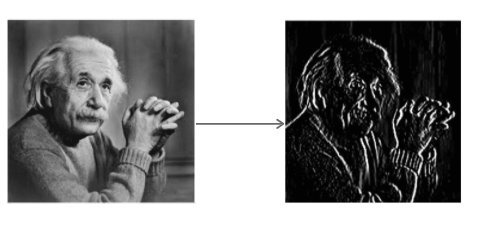
Stosowanie Sy do obrazu
Przeczytaj: Wynagrodzenie za uczenie maszynowe w Indiach
Filtr uśredniający
Filtr średni to znormalizowany filtr, który służy do określania jasności lub ciemności obrazu. Filtr średni przesuwa się po obrazie, piksel po pikselu, zastępując każdą wartość w pikselu średnią wartością sąsiednich pikseli, w tym samego siebie.
Filtrowanie Średnia (lub średnia) wygładza obrazy, zmniejszając stopień zmienności intensywności między sąsiednimi pikselami.
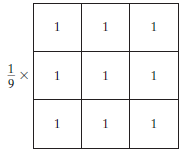
Filtr średni, źródło obrazu
Filtr rozmycia Gaussa
Filtr rozmycia gaussowskiego jest filtrem dolnoprzepustowym i ma następujące funkcje:
- Wygładza obraz
- Blokuje części obrazu o wysokiej częstotliwości
- Zachowuje krawędzie
Matematycznie, stosując rozmycie gaussowskie do obrazu, w zasadzie łączymy obraz z funkcją gaussowską.

W powyższym wzorze x to odległość pozioma od punktu początkowego, y to odległość pionowa od punktu początkowego, a σ to odchylenie standardowe rozkładu Gaussa. W dwóch wymiarach wzór przedstawia powierzchnię, której profile są koncentrycznymi okręgami o rozkładzie Gaussa od punktu początkowego.
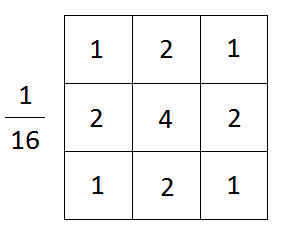

Filtr rozmycia Gaussa, źródło obrazu
Należy zwrócić uwagę na to, jak ważny jest wybór odpowiedniego rozmiaru jądra. Jest to ważne, ponieważ jeśli wymiar jądra jest zbyt duży, małe cechy obecne na obrazie mogą zniknąć, a obraz będzie wyglądał na rozmazany. Jeśli jest za mały, szum w obrazie nie zostanie wyeliminowany.
Przeczytaj także: Rodzaje algorytmów AI, które powinieneś znać
Wykrywacz krawędzi Canny
Jest to algorytm wykorzystujący cztery filtry do wykrywania krawędzi poziomych, pionowych i ukośnych w rozmytym obrazie. Algorytm realizuje następujące funkcje.
- Jest to szeroko stosowany dokładny algorytm wykrywania krawędzi
- Filtruje szum za pomocą rozmycia gaussowskiego
- Znajduje siłę i kierunek krawędzi za pomocą filtra Sobela
- Stosuje tłumienie niemaksymalne, aby wyizolować najsilniejsze krawędzie i rozcieńczyć je do linii jednego piksela
- Wykorzystuje histerezę (metoda podwójnego progowania), aby wyizolować najlepsze krawędzie
Detektor Canny Edge na zdjęciu silnika parowego, Zdjęcie: Wikipedia
Kaskada Haara
Jest to podejście oparte na uczeniu maszynowym, w którym funkcja kaskadowa jest szkolona w celu rozwiązywania problemów z klasyfikacją binarną. Funkcja jest wytrenowana na podstawie wielu pozytywnych i negatywnych obrazów i jest dalej wykorzystywana do wykrywania obiektów na innych obrazach. Wykrywa następujące elementy:
- Krawędzie
- Linie
- Wzory prostokątne
Do wykrywania powyższych wzorców wykorzystywane są następujące funkcje:
Warstwy splotowe
W tym podejściu sieć neuronowa uczy się cech grupy obrazów należących do tej samej kategorii. Uczenie odbywa się poprzez aktualizację wag neuronów przy użyciu techniki wstecznej propagacji i gradientu jako optymalizatora.
Jest to proces iteracyjny, którego celem jest zmniejszenie błędu między rzeczywistą wartością wyjściową a prawdą podstawową. Otrzymane w ten sposób warstwy/bloki splotu pełnią funkcję warstw charakterystycznych, które służą do odróżnienia obrazu pozytywnego od negatywnego. Przykład warstwy splotowej podano poniżej.
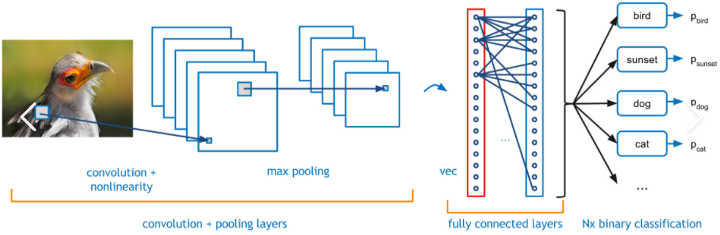
Splotowa sieć neuronowa, źródło obrazu
W pełni połączone warstwy wraz z funkcją SoftMax na końcu kategoryzuje przychodzący obraz do jednej z kategorii, w których jest trenowany. Wynik wyjściowy to wynik probabilistyczny w zakresie od 0 do 1.
Trzeba przeczytać: Rodzaje algorytmów klasyfikacji w ML
Wniosek
Przegląd najpopularniejszych algorytmów używanych w Computer Vision został omówiony w tym blogu wraz z ogólnym rurociągiem. Algorytmy te stanowią podstawę bardziej skomplikowanych algorytmów, takich jak SIFT, SURF, ORB i wielu innych.
Jeśli chcesz dowiedzieć się więcej o uczeniu maszynowym, sprawdź dyplom PG IIIT-B i upGrad w uczeniu maszynowym i sztucznej inteligencji, który jest przeznaczony dla pracujących profesjonalistów i oferuje ponad 450 godzin rygorystycznego szkolenia, ponad 30 studiów przypadków i zadań, IIIT- Status absolwenta B, ponad 5 praktycznych, praktycznych projektów zwieńczenia i pomoc w pracy z najlepszymi firmami.
Jaka jest różnica między przetwarzaniem obrazu a wizją komputerową?
Przetwarzanie obrazu poprawia surową formę obrazów, aby stworzyć lepszą wersję. Służy również do wyodrębniania niektórych cech obrazu pierwotnego. Przetwarzanie obrazu jest zatem odrębną sekcją w samym polu widzenia komputerowego. Jednak Computer Vision skupia się na rozpoznawaniu obiektów bodźców w celu ich dokładnej klasyfikacji. Obaj również stosują podobne technologie w swojej procedurze. Dlatego przetwarzanie obrazu może być podstawowym procesem w wizji komputerowej. Pozostaje wybitną dziedziną sztucznej inteligencji. Przetwarzanie obrazu skupia się na ulepszaniu obrazów; Technologia Computer Vision skupia się na szczegółowej, dokładnej analizie, aby tworzyć lepsze systemy.
Dlaczego Deep Learning jest używany do budowania algorytmów Computer Vision?
Wizja komputerowa sprawiła, że sztuczna inteligencja (AI) jest bardziej niezawodna dzięki rygorystycznym badaniom opartym na danych i spójnej wizualnej analizie danych. Głębokie uczenie to ciągły proces wprowadzania danych przez sieci neuronowe. Informacje pochodzą z procesów ludzkiego mózgu w celu udoskonalenia algorytmu wydajnego uczenia się, przetwarzania i generowania wyników. Głębokie uczenie poprawia dokładną klasyfikację danych, zapewnia niezawodny model AI. Widzenie komputerowe wykorzystuje tę metodę, aby dopasować sztuczną inteligencję do sieci neuronowej ludzkiego mózgu. Głębokie uczenie umożliwiło niezawodne systemy wspomagające ludzi i poprawiające ich jakość życia.
Co to jest filtr dolnoprzepustowy i filtr górnoprzepustowy?
W algorytmach widzenia komputerowego wiele filtrów daje pożądane wyniki z nieprzetworzonego obrazu. Filtry te pełnią wiele funkcji, aby wygładzić, wyostrzyć i zaakcentować wygląd zgodnie z potrzebami. Filtry różnią się częstotliwością i proponują różne efekty. Na przykład filtr Gaussian Blur zasadniczo działa na wygładzanie obrazu poprzez zmianę części obrazu o wysokiej częstotliwości i zachowanie krawędzi. Nazywa się to filtrem dolnoprzepustowym, ponieważ zmniejsza lokalizacje o wysokiej częstotliwości i utrzymuje lokalizacje o niskiej częstotliwości, zapewniając płynniejszy obraz. W filtrach górnoprzepustowych lokalizacje niskich częstotliwości są zmniejszane, a te pierwsze zachowane, co skutkuje ostrzejszym obrazem.