
Computer-Vision-Algorithmen: Alles, was Sie wissen wollten [2022]
Veröffentlicht: 2021-01-01Lernen Sie die Algorithmen kennen, die Computern die Wahrnehmung ermöglichen
Inhaltsverzeichnis
Einführung
Das Wort Computer Vision bedeutet die Fähigkeit eines Computers, die Umgebung zu sehen und wahrzunehmen. Computer Vision bietet viele Anwendungsmöglichkeiten – Objekterkennung und -erkennung, selbstfahrende Autos, Gesichtserkennung, Ballverfolgung, Foto-Tagging und vieles mehr. Bevor wir in die Fachsprache eintauchen, lassen Sie uns zunächst die gesamte Computer-Vision-Pipeline besprechen.
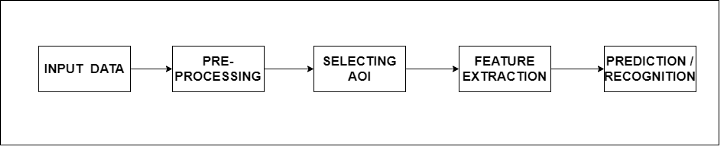
Die gesamte Pipeline ist in 5 grundlegende Schritte unterteilt, von denen jeder eine bestimmte Funktion hat. Erstens wird die Eingabe benötigt, die der Algorithmus verarbeiten kann, die in Form eines Bildes oder Bildstroms (Bildrahmen) vorliegen kann. Der nächste Schritt ist die Vorverarbeitung. In diesem Schritt werden Funktionen auf die eingehenden Bilder angewendet, damit der Algorithmus das Bild besser verstehen kann.
Einige der Funktionen umfassen Rauschunterdrückung, Bildskalierung, Dilatation und Erosion, Entfernen von Farbflecken usw. Der nächste Schritt ist die Auswahl des interessierenden Bereichs oder des interessierenden Bereichs. Darunter liegen die Objekterkennungs- und Bildsegmentierungsalgorithmen. Darüber hinaus verfügen wir über eine Merkmalsextraktion, dh das Abrufen relevanter Informationen/Merkmale aus den Bildern, die zum Erreichen des Endziels erforderlich sind.
Der letzte Schritt ist die Erkennung oder Vorhersage, bei der wir Objekte in einem bestimmten Bildrahmen erkennen oder die Wahrscheinlichkeit des Objekts in einem bestimmten Bildrahmen vorhersagen.
Beispiel
Sehen wir uns eine reale Anwendung der Computer-Vision-Pipeline an. Die Gesichtsausdruckerkennung ist eine Anwendung des Computersehens, die von vielen Forschungslabors verwendet wird, um eine Vorstellung davon zu bekommen, welche Wirkung ein bestimmtes Produkt auf seine Benutzer hat. Auch hier haben wir Eingabedaten, auf die wir die Vorverarbeitungsalgorithmen anwenden.

Der nächste Schritt besteht darin, Gesichter in einem bestimmten Rahmen zu erkennen und diesen Teil des Rahmens zuzuschneiden. Sobald dies erreicht ist, werden Gesichtsmerkmale wie Mund, Augen, Nase usw. identifiziert – Schlüsselmerkmale für die Emotionserkennung.

Am Ende klassifiziert ein Vorhersagemodell (trainiertes Modell) die Bilder anhand der in den Zwischenschritten extrahierten Merkmale.
Algorithmen
Bevor ich anfange, die Algorithmen in Computer Vision zu erwähnen, möchte ich den Begriff „Frequenz“ hervorheben. Die Frequenz eines Bildes ist die Änderungsrate der Intensität. Hochfrequenzbilder weisen große Intensitätsänderungen auf. Ein niederfrequentes Bild weist eine relativ gleichmäßige Helligkeit auf oder die Intensität ändert sich langsam.
Wendet man die Fourier-Transformation auf ein Bild an, erhält man ein Betragsspektrum, das die Information über die Bildfrequenz liefert. Ein konzentrierter Punkt in der Mitte des Bildes im Frequenzbereich bedeutet, dass viele niederfrequente Komponenten im Bild vorhanden sind. Zu den Hochfrequenzkomponenten gehören Kanten, Ecken, Streifen usw. Wir wissen, dass ein Bild eine Funktion von x und yf(x,y) ist. Um die Intensitätsänderung zu messen, nehmen wir einfach die Ableitung der Funktion f(x,y).
Nüchterner Filter
Der Sobel-Operator wird in der Bildverarbeitung und Computer Vision für Kantenerkennungsalgorithmen verwendet. Der Filter erzeugt ein Bild mit hervorgehobenen Kanten. Es berechnet eine Näherung der Steigung/des Gradienten der Bildintensitätsfunktion. Bei jedem Pixel im Bild ist die Ausgabe des Sobel-Operators sowohl der entsprechende Gradientenvektor als auch die Norm dieses Vektors.
Der Sobel-Operator faltet das Bild mit einem kleinen ganzzahligen Filter in horizontaler und vertikaler Richtung. Dies macht den Operator im Hinblick auf die Rechenkomplexität kostengünstig. Der Sx-Filter erkennt Kanten in horizontaler Richtung und der Sy-Filter erkennt Kanten in vertikaler Richtung. Es ist ein Hochpassfilter.
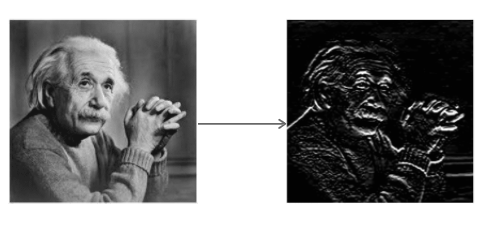
Anwenden von Sx auf das Bild
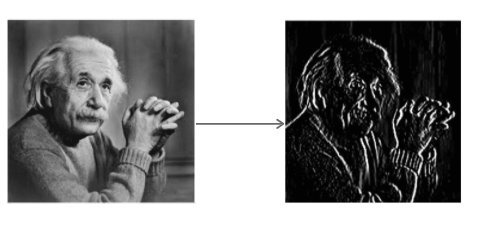
Anwenden von Sy auf das Bild
Lesen Sie: Gehalt für maschinelles Lernen in Indien
Mittelungsfilter
Der Durchschnittsfilter ist ein normalisierter Filter, der verwendet wird, um die Helligkeit oder Dunkelheit eines Bildes zu bestimmen. Der Durchschnittsfilter bewegt sich Pixel für Pixel über das Bild und ersetzt jeden Wert im Pixel durch den Durchschnittswert der benachbarten Pixel, einschließlich sich selbst.
Die Durchschnitts- (oder Mittelwert-) Filterung glättet die Bilder, indem sie die Intensitätsvariation zwischen den benachbarten Pixeln reduziert.
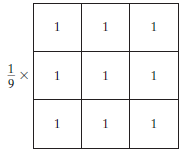
Durchschnittsfilter, Bildquelle
Gaußscher Unschärfefilter
Der Gaußsche Unschärfefilter ist ein Tiefpassfilter und hat die folgenden Funktionen:
- Glättet ein Bild
- Blockiert hochfrequente Teile eines Bildes
- Konserviert Kanten
Mathematisch gesehen falten wir durch Anwenden einer Gaußschen Unschärfe auf ein Bild das Bild im Grunde mit einer Gaußschen Funktion.

In der obigen Formel ist x der horizontale Abstand vom Ursprungspunkt, y der vertikale Abstand vom Ursprungspunkt und σ die Standardabweichung der Gaußschen Verteilung. In zwei Dimensionen stellt die Formel eine Oberfläche dar, deren Profile konzentrische Kreise mit einer Gaußschen Verteilung vom Ursprungspunkt sind.

Gaußscher Weichzeichner, Bildquelle
Eine Sache, die hier zu beachten ist, ist die Wichtigkeit, die richtige Kerngröße zu wählen. Dies ist wichtig, denn wenn die Kernel-Dimension zu groß ist, können kleine im Bild vorhandene Merkmale verschwinden und das Bild wird verschwommen aussehen. Wenn er zu klein ist, wird das Rauschen im Bild nicht beseitigt.
Lesen Sie auch: Arten von KI-Algorithmen, die Sie kennen sollten
Canny Edge-Detektor
Es ist ein Algorithmus, der vier Filter verwendet , um horizontale, vertikale und diagonale Kanten im unscharfen Bild zu erkennen. Der Algorithmus führt die folgenden Funktionen aus.
- Es ist ein weit verbreiteter Algorithmus zur genauen Kantenerkennung
- Filtert Rauschen mit Gaußscher Weichzeichner heraus
- Ermittelt die Stärke und Richtung von Kanten mithilfe des Sobel-Filters
- Wendet eine Non-Max-Unterdrückung an, um die stärksten Kanten zu isolieren und sie auf eine Pixellinie zu verdünnen
- Verwendet Hysterese (doppelte Schwellenwertmethode), um die besten Kanten zu isolieren
Canny Edge-Detektor auf einem Dampfmaschinenfoto, Bild von Wikipedia
Haar Kaskade
Dies ist ein auf maschinellem Lernen basierender Ansatz, bei dem eine Kaskadenfunktion trainiert wird, um binäre Klassifizierungsprobleme zu lösen. Die Funktion wird aus einer Fülle positiver und negativer Bilder trainiert und wird weiter verwendet, um Objekte in anderen Bildern zu erkennen. Es erkennt Folgendes:
- Kanten
- Linien
- Rechteckige Muster
Um die oben genannten Muster zu erkennen, werden die folgenden Merkmale verwendet:
Faltungsschichten
Bei diesem Ansatz lernt das neuronale Netzwerk die Merkmale einer Gruppe von Bildern, die zu derselben Kategorie gehören. Das Lernen erfolgt durch Aktualisieren der Gewichte der Neuronen unter Verwendung der Backpropagation-Technik und des Gradientenabstiegs als Optimierer.
Es ist ein iterativer Prozess, der darauf abzielt, den Fehler zwischen der tatsächlichen Ausgabe und der Grundwahrheit zu verringern. Die dabei erhaltenen Faltungsschichten/Blöcke wirken als Merkmalsschichten, die dazu dienen, ein Positivbild von einem Negativbild zu unterscheiden. Ein Beispiel für eine Faltungsschicht ist unten angegeben.
Convolutional Neural Network, Bildquelle
Die vollständig verbundenen Ebenen zusammen mit einer SoftMax-Funktion am Ende kategorisieren das eingehende Bild in eine der Kategorien, in denen es trainiert wird. Der Ausgabewert ist ein probabilistischer Wert mit einem Bereich zwischen 0 und 1.
Muss gelesen werden: Arten von Klassifizierungsalgorithmen in ML
Fazit
In diesem Blog wurde ein Überblick über die am häufigsten verwendeten Algorithmen in Computer Vision sowie eine allgemeine Pipeline gegeben. Diese Algorithmen bilden die Grundlage für kompliziertere Algorithmen wie SIFT, SURF, ORB und viele mehr.
Wenn Sie mehr über maschinelles Lernen erfahren möchten, sehen Sie sich das PG-Diplom in maschinellem Lernen und KI von IIIT-B & upGrad an, das für Berufstätige konzipiert ist und mehr als 450 Stunden strenge Schulungen, mehr als 30 Fallstudien und Aufgaben bietet, IIIT- B-Alumni-Status, mehr als 5 praktische, praktische Abschlussprojekte und Jobunterstützung bei Top-Unternehmen.
Was ist der Unterschied zwischen Bildverarbeitung und Computer Vision?
Die Bildverarbeitung verbessert die Rohform von Bildern, um eine bessere Version zu erzeugen. Es wird auch zum Extrahieren einiger Merkmale des Primärbildes verwendet. Die Bildverarbeitung ist daher ein eigenständiger Bereich im Bereich Computer Vision. Computer Vision konzentriert sich jedoch auf das Erkennen von Stimuli-Objekten für eine genaue Klassifizierung. Beide verwenden auch ähnliche Technologien in ihrem Verfahren. Daher kann die Bildverarbeitung der primäre Prozess in der Computer Vision sein. Es bleibt ein prominentes Feld in der künstlichen Intelligenz. Die Bildverarbeitung konzentriert sich auf die Verbesserung von Bildern; Die Computer-Vision-Technologie konzentriert sich auf detaillierte, genaue Analysen, um bessere Systeme zu erstellen.
Warum wird Deep Learning zum Erstellen von Computer-Vision-Algorithmen verwendet?
Computer Vision hat die künstliche Intelligenz (KI) durch strenge datengesteuerte Forschung und konsequente visuelle Datenanalyse robuster gemacht. Deep Learning ist ein kontinuierlicher Prozess der Dateneingabe durch neuronale Netze. Die Informationen werden aus Prozessen des menschlichen Gehirns abgeleitet, um den Algorithmus für effizientes Lernen, Verarbeiten und Ausgeben zu perfektionieren. Deep Learning verbessert die genaue Datenklassifizierung und gewährleistet ein zuverlässiges KI-Modell. Computer Vision verwendet diese Methode, um die KI an das neuronale Netzwerk des menschlichen Gehirns anzupassen. Deep Learning hat zuverlässige Systeme ermöglicht, die Menschen unterstützen und ihre Lebensqualität verbessern.
Was ist ein Tiefpassfilter und ein Hochpassfilter?
In Computer-Vision-Algorithmen erzeugen mehrere Filter die gewünschten Ergebnisse aus einem Rohbild. Diese Filter führen zahlreiche Funktionen aus, um das Erscheinungsbild nach Wunsch zu glätten, zu schärfen und zu akzentuieren. Die Filter unterscheiden sich in ihrer Frequenz und schlagen unterschiedliche Effekte vor. Beispielsweise arbeitet der Gaußsche Weichzeichnerfilter im Wesentlichen daran, das Bild zu glätten, indem er die hochfrequenten Teile des Bildes ändert und die Kanten beibehält. Es wird als Tiefpassfilter bezeichnet, weil es die hochfrequenten Stellen verringert und die niederfrequenten Stellen beibehält, wodurch es ein glatteres Bild erhält. In Hochpassfiltern werden die niederfrequenten Stellen verringert und die ersteren erhalten, was zu einem schärferen Bild führt.