
Algoritmos de visão computacional: tudo o que você queria saber [2022]
Publicados: 2021-01-01Conheça os algoritmos que permitem que os computadores percebam
Índice
Introdução
A palavra visão computacional significa a capacidade de um computador de ver e perceber o ambiente. Muitas aplicações são válidas para a visão computacional – detecção e reconhecimento de objetos, carros autônomos, reconhecimento facial, rastreamento de bola, marcação de fotos e muito mais. Antes de mergulhar nos jargões técnicos, primeiro vamos discutir todo o pipeline de visão computacional.
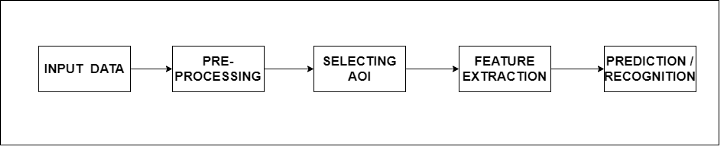
Todo o pipeline é dividido em 5 etapas básicas, cada uma com uma função específica. Primeiramente, a entrada é necessária para o algoritmo processar que pode ser na forma de uma imagem ou fluxo de imagem (quadros de imagem). O próximo passo é o pré-processamento. Nesta etapa, as funções são aplicadas à(s) imagem(ns) recebida(s) para que o algoritmo possa entender melhor a imagem.
Algumas das funções envolvem redução de ruído, dimensionamento de imagem, dilatação e erosão, remoção de manchas de cor, etc. O próximo passo é selecionar a área de interesse ou a região de interesse. Sob isso estão os algoritmos de detecção de objetos e segmentação de imagens. Além disso, temos a extração de recursos que significa recuperar informações/recursos relevantes das imagens que são necessários para atingir o objetivo final.
A etapa final é o reconhecimento ou previsão, onde reconhecemos objetos em um determinado quadro de imagens ou prevemos a probabilidade do objeto em um determinado quadro de imagem.
Exemplo
Vejamos uma aplicação do mundo real do pipeline de visão computacional. O reconhecimento de expressão facial é uma aplicação de visão computacional que é usada por muitos laboratórios de pesquisa para ter uma ideia do efeito que um determinado produto tem em seus usuários. Novamente, temos dados de entrada aos quais aplicamos os algoritmos de pré-processamento.

A próxima etapa envolve detectar rostos em um quadro específico e cortar essa parte do quadro. Uma vez que isso é alcançado, os pontos de referência faciais são identificados como boca, olhos, nariz, etc. — características-chave para o reconhecimento de emoções.

Ao final, um modelo de previsão (modelo treinado) classifica as imagens com base nas características extraídas nas etapas intermediárias.
Algoritmos
Antes de começar a mencionar os algoritmos em visão computacional, quero enfatizar o termo 'Frequência'. A frequência de uma imagem é a taxa de mudança de intensidade. Imagens de alta frequência têm grandes mudanças de intensidade. Uma imagem de baixa frequência é relativamente uniforme em brilho ou a intensidade muda lentamente.
Ao aplicar a transformada de Fourier a uma imagem, obtemos um espectro de magnitude que fornece a informação da frequência da imagem. O ponto concentrado no centro da imagem no domínio da frequência significa que muitos componentes de baixa frequência estão presentes na imagem. Os componentes de alta frequência incluem — bordas, cantos, listras, etc. Sabemos que uma imagem é uma função de x e yf(x,y). Para medir a mudança de intensidade, basta derivar a função f(x,y).
Filtro Sóbrio
O operador Sobel é usado no processamento de imagens e visão computacional para algoritmos de detecção de bordas. O filtro cria uma imagem de bordas enfatizadas. Ele calcula uma aproximação da inclinação/gradiente da função de intensidade da imagem. Em cada pixel da imagem, a saída do operador de Sobel é o vetor gradiente correspondente e a norma desse vetor.
O Operador Sobel envolve a imagem com um pequeno filtro de valor inteiro nas direções horizontal e vertical. Isso torna o operador barato em termos de complexidade computacional. O filtro Sx detecta bordas na direção horizontal e o filtro Sy detecta bordas na direção vertical. É um filtro passa-alta.
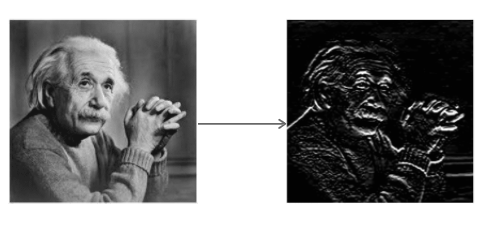
Aplicando Sx à imagem
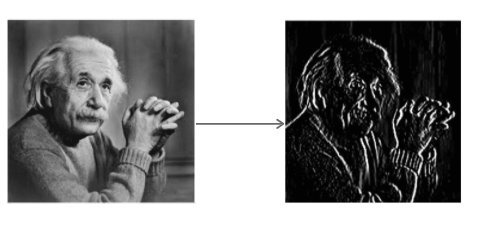
Aplicando Sy à imagem
Leia: Salário de aprendizado de máquina na Índia
Filtro de média
O filtro médio é um filtro normalizado que é usado para determinar o brilho ou a escuridão de uma imagem. O filtro médio se move pela imagem pixel a pixel substituindo cada valor no pixel pelo valor médio dos pixels vizinhos, incluindo ele mesmo.
A filtragem Média (ou média) suaviza as imagens reduzindo a quantidade de variação na intensidade entre os pixels vizinhos.
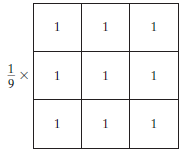
Filtro médio, origem da imagem
Filtro de Desfoque Gaussiano
O filtro de desfoque gaussiano é um filtro passa-baixa e tem as seguintes funções:
- Suaviza uma imagem
- Bloqueia partes de alta frequência de uma imagem
- Preserva as bordas
Matematicamente, aplicando um desfoque gaussiano a uma imagem, estamos basicamente convolvendo a imagem com uma função gaussiana.

Na fórmula acima, x é a distância horizontal do ponto de origem, y é a distância vertical do ponto de origem e σ é o desvio padrão da distribuição gaussiana. Em duas dimensões, a fórmula representa uma superfície cujos perfis são círculos concêntricos com distribuição gaussiana a partir do ponto de origem.
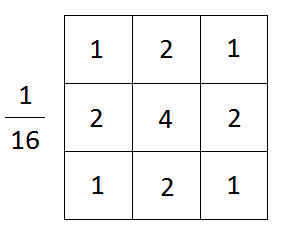

Filtro de desfoque gaussiano, fonte de imagem
Uma coisa a notar aqui é a importância de escolher o tamanho certo do kernel. É importante porque se a dimensão do kernel for muito grande, pequenos recursos presentes na imagem podem desaparecer e a imagem parecerá borrada. Se for muito pequeno, o ruído na imagem não será eliminado.
Leia também: Tipos de algoritmo de IA que você deve conhecer
Detector de Borda Canny
É um algoritmo que utiliza quatro filtros para detectar bordas horizontais, verticais e diagonais na imagem borrada. O algoritmo executa as seguintes funções.
- É um algoritmo de detecção de borda preciso amplamente utilizado
- Filtra o ruído usando Gaussian Blur
- Encontra a força e a direção das arestas usando o filtro Sobel
- Aplica a supressão não máxima para isolar as arestas mais fortes e reduzi-las a uma linha de pixel
- Usa histerese (método de limiar duplo) para isolar as melhores bordas
Detector Canny Edge em uma foto de motor a vapor, Imagem da Wikipedia
Cascata de Haar
Esta é uma abordagem baseada em aprendizado de máquina onde uma função em cascata é treinada para resolver problemas de classificação binária. A função é treinada a partir de uma infinidade de imagens positivas e negativas e ainda é usada para detectar objetos em outras imagens. Ele detecta o seguinte:
- Arestas
- Linhas
- Padrões retangulares
Para detectar os padrões acima, os seguintes recursos são usados:
Camadas convolucionais
Nesta abordagem, a rede neural aprende as características de um grupo de imagens pertencentes à mesma categoria. O aprendizado ocorre atualizando os pesos dos neurônios usando a técnica de retropropagação e gradiente descendente como otimizador.
É um processo iterativo que visa diminuir o erro entre a saída real e a verdade. As camadas/blocos de convolução assim obtidos no processo atuam como camadas de feição que são usadas para distinguir uma imagem positiva de uma negativa. Exemplo de uma camada de convolução é dado abaixo.
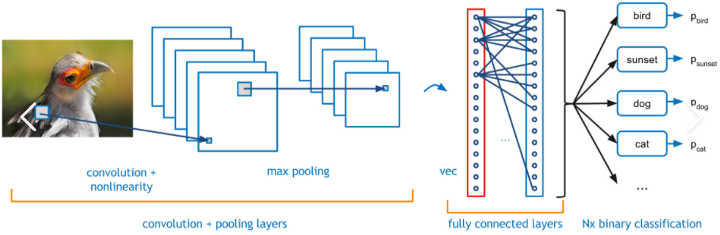
Rede neural convolucional, fonte de imagem
As camadas totalmente conectadas, juntamente com uma função SoftMax no final, categorizam a imagem recebida em uma das categorias nas quais ela é treinada. A pontuação de saída é uma pontuação probabilística com um intervalo entre 0 e 1.
Deve ler: tipos de algoritmo de classificação em ML
Conclusão
Uma visão geral dos algoritmos mais comuns usados em Visão Computacional foi abordada neste blog junto com um pipeline geral. Esses algoritmos formam a base de algoritmos mais complicados como SIFT, SURF, ORB e muitos outros.
Se você estiver interessado em aprender mais sobre aprendizado de máquina, confira o PG Diploma in Machine Learning & AI do IIIT-B e upGrad, projetado para profissionais que trabalham e oferece mais de 450 horas de treinamento rigoroso, mais de 30 estudos de caso e atribuições, IIIT- B Status de ex-aluno, mais de 5 projetos práticos práticos e assistência de trabalho com as principais empresas.
Qual é a diferença entre Processamento de Imagem e Visão Computacional?
O Processamento de Imagem aprimora a forma bruta das imagens para produzir uma versão melhor. Ele também é usado para extrair alguns recursos da imagem primária. Processamento de Imagem é, portanto, uma seção distinta no próprio campo da Visão Computacional. No entanto, a Visão Computacional se concentra no reconhecimento de objetos de estímulo para uma classificação precisa. Ambos também utilizam tecnologias semelhantes em seu procedimento. Assim, o Processamento de Imagem pode ser o processo primário em Visão Computacional. Continua a ser um campo de destaque em Inteligência Artificial. Processamento de imagem concentra-se no aprimoramento de imagens; A tecnologia de Visão Computacional se concentra em análises detalhadas e precisas para criar sistemas melhores.
Por que o Deep Learning é usado para construir algoritmos de Visão Computacional?
A Visão Computacional tornou a Inteligência Artificial (IA) mais robusta devido à rigorosa pesquisa orientada por dados e à análise consistente de dados visuais. Deep Learning é um processo contínuo de entrada de dados por meio de redes neurais. A informação é derivada de processos do cérebro humano para aperfeiçoar o algoritmo para aprendizado, processamento e saída eficientes. O Deep Learning aprimora a classificação de dados precisa, garante um modelo de IA confiável. A Computer Vision usa esse método para alinhar a IA à rede neural do cérebro humano. O Deep Learning permitiu que sistemas confiáveis auxiliassem os humanos e melhorassem sua qualidade de vida.
O que é um filtro Low Pass e um filtro High Pass?
Em algoritmos de visão computacional, vários filtros produzem os resultados desejados de uma imagem bruta. Esses filtros executam inúmeras funções para suavizar, aguçar e acentuar a aparência conforme desejado. Os filtros diferem em sua frequência e propõem diferentes efeitos. Por exemplo, o filtro Gaussian Blur funciona essencialmente na suavização da imagem, alterando as partes de alta frequência da imagem e preservando as bordas. É chamado de filtro Low Pass porque diminui os locais de alta frequência e mantém os locais de baixa frequência, proporcionando um visual mais suave. Nos filtros High Pass, as localizações de baixa frequência são diminuídas e as primeiras preservadas, o que resulta em um visual mais nítido.