
Algoritmi di visione artificiale: tutto ciò che volevi sapere [2022]
Pubblicato: 2021-01-01Scopri gli algoritmi che consentono ai computer di percepire
Sommario
introduzione
La parola computer vision significa la capacità di un computer di vedere e percepire l'ambiente circostante. Molte applicazioni sono valide per la visione artificiale: rilevamento e riconoscimento di oggetti, auto a guida autonoma, riconoscimento facciale, rilevamento della palla, etichettatura di foto e molti altri. Prima di immergerci nei gerghi tecnici, discutiamo prima dell'intera pipeline di visione artificiale.
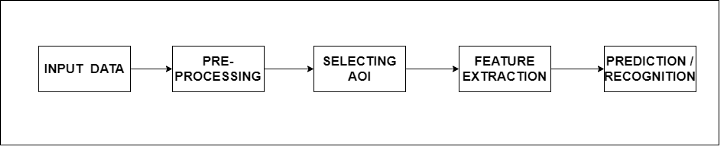
L'intera pipeline è suddivisa in 5 step fondamentali, ognuno con una specifica funzione. In primo luogo, l'input è necessario per l'elaborazione dell'algoritmo che può essere sotto forma di un'immagine o di un flusso di immagini (frame di immagini). Il passaggio successivo è la pre-elaborazione. In questo passaggio, le funzioni vengono applicate alle immagini in arrivo in modo che l'algoritmo possa comprendere meglio l'immagine.
Alcune delle funzioni comprendono la riduzione del rumore, il ridimensionamento dell'immagine, la dilatazione e l'erosione, la rimozione delle macchie di colore, ecc. Il passaggio successivo consiste nella selezione dell'area di interesse o della regione di interesse. Sotto questo si trovano gli algoritmi di rilevamento degli oggetti e segmentazione delle immagini. Inoltre, abbiamo l'estrazione delle caratteristiche che significa recuperare informazioni/caratteristiche rilevanti dalle immagini necessarie per raggiungere l'obiettivo finale.
Il passaggio finale è il riconoscimento o la previsione, in cui riconosciamo gli oggetti in una data cornice di immagini o prevediamo la probabilità dell'oggetto in una data cornice di immagine.
Esempio
Diamo un'occhiata a un'applicazione nel mondo reale della pipeline di visione artificiale. Il riconoscimento delle espressioni facciali è un'applicazione di visione artificiale utilizzata da molti laboratori di ricerca per avere un'idea dell'effetto che un particolare prodotto ha sui suoi utenti. Anche in questo caso, abbiamo dati di input a cui applichiamo gli algoritmi di pre-elaborazione.

Il passaggio successivo prevede il rilevamento dei volti in una cornice particolare e il ritaglio di quella parte della cornice. Una volta ottenuto ciò, i punti di riferimento del viso vengono identificati come bocca, occhi, naso, ecc., caratteristiche chiave per il riconoscimento delle emozioni.

Alla fine, un modello di previsione (modello addestrato) classifica le immagini in base alle caratteristiche estratte nei passaggi intermedi.
Algoritmi
Prima di iniziare a citare gli algoritmi nella visione artificiale, voglio sottolineare il termine "Frequenza". La frequenza di un'immagine è il tasso di variazione dell'intensità. Le immagini ad alta frequenza hanno grandi cambiamenti di intensità. Un'immagine a bassa frequenza ha una luminosità relativamente uniforme o l'intensità cambia lentamente.
Applicando la trasformata di Fourier a un'immagine otteniamo uno spettro di magnitudo che fornisce le informazioni sulla frequenza dell'immagine. Il punto concentrato al centro dell'immagine nel dominio della frequenza significa che nell'immagine sono presenti molte componenti a bassa frequenza. I componenti ad alta frequenza includono — bordi, angoli, strisce, ecc. Sappiamo che un'immagine è una funzione di x e yf(x,y). Per misurare la variazione di intensità, prendiamo semplicemente la derivata della funzione f(x,y).
Filtro sobrio
L'operatore Sobel viene utilizzato nell'elaborazione delle immagini e nella visione artificiale per gli algoritmi di rilevamento dei bordi. Il filtro crea un'immagine di sottolineatura dei bordi. Calcola un'approssimazione della pendenza/gradiente della funzione di intensità dell'immagine. Ad ogni pixel dell'immagine, l'output dell'operatore Sobel è sia il vettore gradiente corrispondente che la norma di questo vettore.
L'operatore Sobel trasforma l'immagine con un piccolo filtro a valori interi nelle direzioni orizzontale e verticale. Ciò rende l'operatore poco costoso in termini di complessità di calcolo. Il filtro Sx rileva i bordi in direzione orizzontale e il filtro Sy rileva i bordi in direzione verticale. È un filtro passa alto.
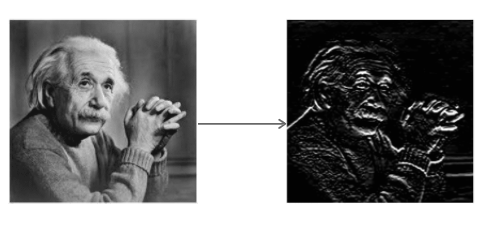
Applicare Sx all'immagine
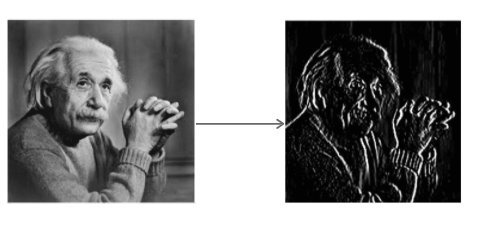
Applicazione di Sy all'immagine
Leggi: Stipendio di apprendimento automatico in India
Filtro di media
Il filtro medio è un filtro normalizzato che viene utilizzato per determinare la luminosità o l'oscurità di un'immagine. Il filtro medio si sposta sull'immagine pixel per pixel sostituendo ogni valore nel pixel con il valore medio dei pixel vicini, incluso se stesso.
Il filtro Media (o media) uniforma le immagini riducendo la quantità di variazione nell'intensità tra i pixel adiacenti.
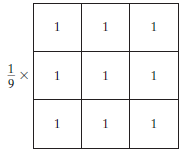
Filtro medio, Sorgente immagine
Filtro sfocatura gaussiana
Il filtro sfocatura gaussiana è un filtro passa basso e ha le seguenti funzioni:
- Leviga un'immagine
- Blocca le parti ad alta frequenza di un'immagine
- Conserva i bordi
Matematicamente, applicando una sfocatura gaussiana a un'immagine stiamo fondamentalmente convogliando l'immagine con una funzione gaussiana.

Nella formula precedente, x è la distanza orizzontale dal punto di origine, y è la distanza verticale dal punto di origine e σ è la deviazione standard della distribuzione gaussiana. In due dimensioni, la formula rappresenta una superficie i cui profili sono cerchi concentrici con distribuzione gaussiana dal punto di origine.
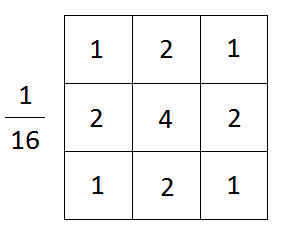

Filtro sfocatura gaussiana, sorgente immagine
Una cosa da notare qui è l'importanza di scegliere la giusta dimensione del kernel. È importante perché se la dimensione del kernel è troppo grande, le piccole caratteristiche presenti nell'immagine potrebbero scomparire e l'immagine apparirà sfocata. Se è troppo piccolo, il rumore nell'immagine non verrà eliminato.
Leggi anche: Tipi di algoritmi di intelligenza artificiale che dovresti conoscere
Rilevatore di bordi canny
È un algoritmo che utilizza quattro filtri per rilevare i bordi orizzontali, verticali e diagonali nell'immagine sfocata. L'algoritmo esegue le seguenti funzioni.
- È un algoritmo di rilevamento dei bordi accurato ampiamente utilizzato
- Filtra il rumore usando la sfocatura gaussiana
- Trova la forza e la direzione dei bordi usando il filtro Sobel
- Applica la soppressione non massima per isolare i bordi più forti e assottigliarli a una linea di pixel
- Utilizza l'isteresi (metodo a doppia soglia) per isolare i bordi migliori
Rilevatore Canny Edge su una foto di una macchina a vapore, Immagine di Wikipedia
Cascata di Haar
Questo è un approccio basato sull'apprendimento automatico in cui una funzione a cascata viene addestrata per risolvere problemi di classificazione binaria. La funzione viene addestrata da una pletora di immagini positive e negative e viene ulteriormente utilizzata per rilevare oggetti in altre immagini. Rileva quanto segue:
- Bordi
- Linee
- Motivi rettangolari
Per rilevare i modelli di cui sopra, vengono utilizzate le seguenti funzioni:
Strati convoluzionali
In questo approccio, la rete neurale apprende le caratteristiche di un gruppo di immagini appartenenti alla stessa categoria. L'apprendimento avviene aggiornando i pesi dei neuroni utilizzando la tecnica di back propagation e la discesa del gradiente come ottimizzatore.
È un processo iterativo che mira a ridurre l'errore tra l'output effettivo e la verità fondamentale. I livelli/blocchi di convoluzione così ottenuti nel processo agiscono come livelli di funzionalità utilizzati per distinguere un'immagine positiva da una negativa. Di seguito è riportato un esempio di uno strato di convoluzione.
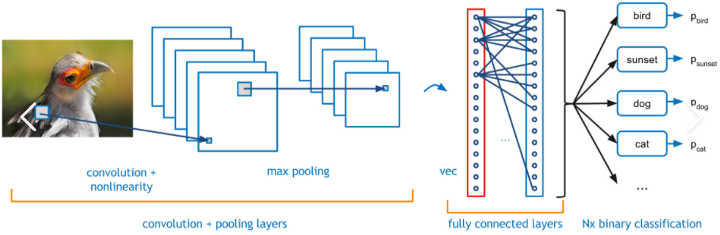
Rete neurale convoluzionale, sorgente di immagine
I livelli completamente connessi insieme a una funzione SoftMax alla fine classificano l'immagine in entrata in una delle categorie su cui è stata addestrata. Il punteggio di output è un punteggio probabilistico con un intervallo compreso tra 0 e 1.
Deve leggere: Tipi di algoritmo di classificazione in ML
Conclusione
Una panoramica degli algoritmi più comuni utilizzati in Computer Vision è stata trattata in questo blog insieme a una pipeline generale. Questi algoritmi costituiscono la base di algoritmi più complicati come SIFT, SURF, ORB e molti altri.
Se sei interessato a saperne di più sull'apprendimento automatico, dai un'occhiata al Diploma PG di IIIT-B e upGrad in Machine Learning e AI, progettato per i professionisti che lavorano e offre oltre 450 ore di formazione rigorosa, oltre 30 casi di studio e incarichi, IIIT- B Status di Alumni, oltre 5 progetti pratici pratici e assistenza sul lavoro con le migliori aziende.
Qual è la differenza tra l'elaborazione delle immagini e la visione artificiale?
L'elaborazione delle immagini migliora la forma grezza delle immagini per produrre una versione migliore. Viene utilizzato anche per estrarre alcune caratteristiche dell'immagine primaria. L'elaborazione delle immagini è quindi una sezione distinta nel campo della Computer Vision. Tuttavia, Computer Vision si concentra sul riconoscimento degli oggetti stimolo per una classificazione accurata. Entrambi utilizzano anche tecnologie simili nella loro procedura. Quindi, l'elaborazione delle immagini può essere il processo principale in Computer Vision. Rimane un campo di spicco nell'intelligenza artificiale. L'elaborazione delle immagini si concentra sul miglioramento delle immagini; La tecnologia di visione artificiale si concentra su analisi dettagliate e accurate per creare sistemi migliori.
Perché il Deep Learning viene utilizzato per creare algoritmi di Computer Vision?
Computer Vision ha reso l'Intelligenza Artificiale (AI) più robusta grazie a una rigorosa ricerca basata sui dati e all'analisi coerente dei dati visivi. Il deep learning è un processo continuo di input di dati attraverso le reti neurali. Le informazioni sono derivate dai processi del cervello umano per perfezionare l'algoritmo per l'apprendimento, l'elaborazione e l'output efficienti. Il Deep Learning migliora la classificazione accurata dei dati, garantisce un modello di intelligenza artificiale affidabile. Computer Vision utilizza questo metodo per allineare l'IA alla rete neurale del cervello umano. Il Deep Learning ha consentito a sistemi affidabili di assistere gli esseri umani e migliorare la loro qualità di vita.
Che cos'è un filtro passa basso e un filtro passa alto?
Negli algoritmi di visione artificiale, più filtri producono i risultati desiderati da un'immagine grezza. Questi filtri svolgono numerose funzioni per levigare, affinare e accentuare l'aspetto come desiderato. I filtri differiscono nella loro frequenza e propongono effetti differenti. Ad esempio, il filtro Sfocatura gaussiana funziona essenzialmente per rendere più uniforme l'immagine alterando le parti ad alta frequenza dell'immagine e preservandone i bordi. Si chiama filtro passa basso perché diminuisce le posizioni ad alta frequenza e mantiene le posizioni a bassa frequenza dandogli una visione più fluida. Nei filtri High Pass, le posizioni delle basse frequenze vengono ridotte e le prime vengono preservate, il che si traduce in una visione più nitida.