
Algorithmes de vision par ordinateur : tout ce que vous vouliez savoir [2022]
Publié: 2021-01-01Apprenez à connaître les algorithmes qui permettent aux ordinateurs de percevoir
Table des matières
introduction
Le mot vision par ordinateur signifie la capacité d'un ordinateur à voir et à percevoir l'environnement. La vision par ordinateur couvre de nombreuses applications : détection et reconnaissance d'objets, voitures autonomes, reconnaissance faciale, suivi de balle, marquage de photos, etc. Avant de plonger dans les jargons techniques, parlons d'abord de l'ensemble du pipeline de vision par ordinateur.
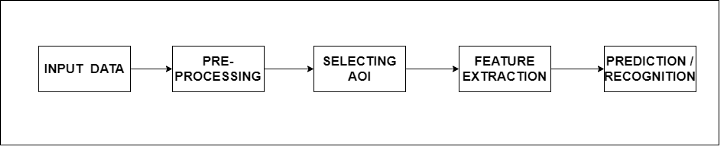
L'ensemble du pipeline est divisé en 5 étapes de base, chacune avec une fonction spécifique. Tout d'abord, l'entrée est nécessaire à l'algorithme à traiter qui peut être sous la forme d'une image ou d'un flux d'images (frames d'image). La prochaine étape est le pré-traitement. Dans cette étape, des fonctions sont appliquées à la ou aux images entrantes afin que l'algorithme puisse mieux comprendre l'image.
Certaines des fonctions impliquent la réduction du bruit, la mise à l'échelle de l'image, la dilatation et l'érosion, la suppression des taches de couleur, etc. L'étape suivante consiste à sélectionner la zone d'intérêt ou la région d'intérêt. En dessous se trouvent les algorithmes de détection d'objets et de segmentation d'images. De plus, nous avons l'extraction de caractéristiques qui signifie récupérer des informations/caractéristiques pertinentes à partir des images qui sont nécessaires pour atteindre l'objectif final.
La dernière étape est la reconnaissance ou la prédiction, où nous reconnaissons des objets dans un cadre d'images donné ou prédisons la probabilité de l'objet dans un cadre d'image donné.
Exemple
Examinons une application réelle du pipeline de vision par ordinateur. La reconnaissance des expressions faciales est une application de la vision par ordinateur utilisée par de nombreux laboratoires de recherche pour se faire une idée de l'effet d'un produit particulier sur ses utilisateurs. Encore une fois, nous avons des données d'entrée auxquelles nous appliquons les algorithmes de prétraitement.

L'étape suivante consiste à détecter les visages dans un cadre particulier et à recadrer cette partie du cadre. Une fois cet objectif atteint, les repères faciaux sont identifiés comme la bouche, les yeux, le nez, etc. - des caractéristiques clés pour la reconnaissance des émotions.

Au final, un modèle de prédiction (modèle entraîné) classe les images en fonction des caractéristiques extraites lors des étapes intermédiaires.
Algorithmes
Avant de commencer à mentionner les algorithmes de vision par ordinateur, je tiens à souligner le terme "Fréquence". La fréquence d'une image est le taux de changement d'intensité. Les images à haute fréquence présentent de grands changements d'intensité. Une image basse fréquence est relativement uniforme en luminosité ou l'intensité change lentement.
En appliquant la transformée de Fourier à une image, nous obtenons un spectre de magnitude qui donne les informations sur la fréquence de l'image. Un point concentré au centre de l'image dans le domaine fréquentiel signifie que de nombreuses composantes basse fréquence sont présentes dans l'image. Les composantes à haute fréquence comprennent — les bords, les coins, les rayures, etc. Nous savons qu'une image est une fonction de x et yf(x,y). Pour mesurer le changement d'intensité, nous prenons simplement la dérivée de la fonction f(x,y).
Filtre sobre
L'opérateur Sobel est utilisé en traitement d'images et en vision par ordinateur pour les algorithmes de détection de contours. Le filtre crée une image d'accentuation des contours. Il calcule une approximation de la pente/gradient de la fonction d'intensité de l'image. A chaque pixel de l'image, la sortie de l'opérateur de Sobel est à la fois le vecteur gradient correspondant et la norme de ce vecteur.
L'opérateur Sobel convolue l'image avec un petit filtre à valeur entière dans les directions horizontale et verticale. Cela rend l'opérateur peu coûteux en termes de complexité de calcul. Le filtre Sx détecte les bords dans la direction horizontale et le filtre Sy détecte les bords dans la direction verticale. C'est un filtre passe haut.
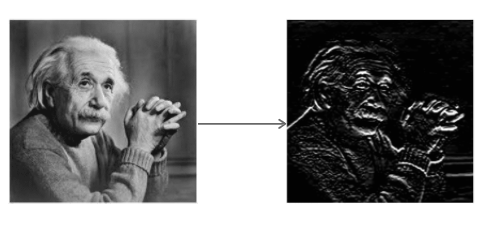
Appliquer Sx à l'image
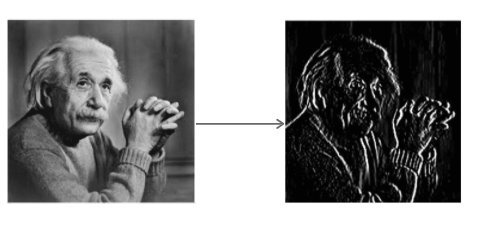
Appliquer Sy à l'image
Lire : Salaire de l'apprentissage automatique en Inde
Filtre de moyenne
Le filtre moyen est un filtre normalisé utilisé pour déterminer la luminosité ou l'obscurité d'une image. Le filtre moyen se déplace dans l'image pixel par pixel en remplaçant chaque valeur du pixel par la valeur moyenne des pixels voisins, y compris lui-même.
Le filtrage Moyenne (ou moyenne) lisse les images en réduisant la quantité de variation d'intensité entre les pixels voisins.
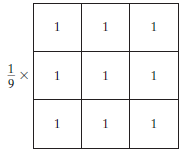
Filtre moyen, source d'image
Filtre de flou gaussien
Le filtre de flou gaussien est un filtre passe-bas et il a les fonctions suivantes :
- Lisse une image
- Bloque les parties à haute fréquence d'une image
- Préserve les bords
Mathématiquement, en appliquant un flou gaussien à une image, nous convoluons essentiellement l'image avec une fonction gaussienne.

Dans la formule ci-dessus, x est la distance horizontale depuis le point d'origine, y est la distance verticale depuis le point d'origine et σ est l'écart type de la distribution gaussienne. En deux dimensions, la formule représente une surface dont les profils sont des cercles concentriques avec une distribution gaussienne à partir du point d'origine.
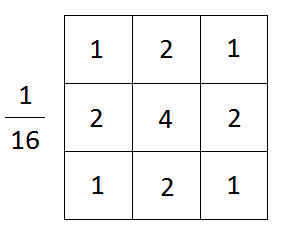

Filtre de flou gaussien, source d'image
Une chose à noter ici est l'importance de choisir une bonne taille de noyau. C'est important car si la dimension du noyau est trop grande, de petites caractéristiques présentes dans l'image peuvent disparaître et l'image semblera floue. S'il est trop petit, le bruit de l'image ne sera pas éliminé.
Lisez aussi : Types d'algorithmes d'IA que vous devez connaître
Canny Edge Détecteur
Il s'agit d'un algorithme qui utilise quatre filtres pour détecter les bords horizontaux, verticaux et diagonaux de l'image floue. L'algorithme exécute les fonctions suivantes.
- Il s'agit d'un algorithme de détection de bord précis largement utilisé
- Filtre le bruit à l'aide du flou gaussien
- Trouve la force et la direction des bords à l'aide du filtre Sobel
- Applique une suppression non maximale pour isoler les bords les plus forts et les réduire à une ligne de pixels
- Utilise l'hystérésis (méthode de seuillage double) pour isoler les meilleurs bords
Détecteur Canny Edge sur une photo de moteur à vapeur, image de Wikipedia
Cascade de Haar
Il s'agit d'une approche basée sur l'apprentissage automatique dans laquelle une fonction en cascade est entraînée pour résoudre des problèmes de classification binaire. La fonction est entraînée à partir d'une pléthore d'images positives et négatives et est ensuite utilisée pour détecter des objets dans d'autres images. Il détecte les éléments suivants :
- Bords
- Lignes
- Motifs rectangulaires
Pour détecter les modèles ci-dessus, les fonctionnalités suivantes sont utilisées :
Couches convolutives
Dans cette approche, le réseau de neurones apprend les caractéristiques d'un groupe d'images appartenant à la même catégorie. L'apprentissage se fait en mettant à jour les poids des neurones en utilisant la technique de rétropropagation et la descente de gradient comme optimiseur.
Il s'agit d'un processus itératif qui vise à réduire l'erreur entre la sortie réelle et la vérité terrain. Les couches/blocs de convolution ainsi obtenus dans le processus agissent comme des couches de caractéristiques qui sont utilisées pour distinguer une image positive d'une image négative. Un exemple de couche de convolution est donné ci-dessous.
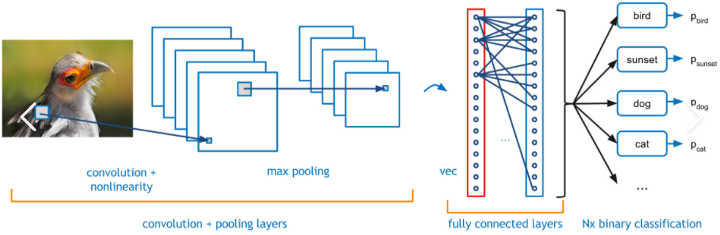
Réseau neuronal convolutif, source d'image
Les couches entièrement connectées avec une fonction SoftMax à la fin classent l'image entrante dans l'une des catégories sur lesquelles elle est formée. Le score de sortie est un score probabiliste compris entre 0 et 1.
Doit lire : Types d'algorithmes de classification en ML
Conclusion
Un aperçu des algorithmes les plus courants utilisés dans la vision par ordinateur a été couvert dans ce blog avec un pipeline général. Ces algorithmes forment la base d'algorithmes plus compliqués comme SIFT, SURF, ORB et bien d'autres.
Si vous souhaitez en savoir plus sur l'apprentissage automatique, consultez le diplôme PG en apprentissage automatique et IA de IIIT-B & upGrad, conçu pour les professionnels en activité et offrant plus de 450 heures de formation rigoureuse, plus de 30 études de cas et missions, IIIT- Statut B Alumni, plus de 5 projets de synthèse pratiques et aide à l'emploi avec les meilleures entreprises.
Quelle est la différence entre le traitement d'images et la vision par ordinateur ?
Le traitement d'image améliore la forme brute des images pour produire une meilleure version. Il est également utilisé pour extraire certaines caractéristiques de l'image principale. Le traitement d'images est donc une section distincte dans le domaine de la vision par ordinateur lui-même. Cependant, la vision par ordinateur se concentre sur la reconnaissance des objets stimuli pour une classification précise. Les deux utilisent également des technologies similaires dans leur procédure. Par conséquent, le traitement d'image peut être le processus principal de la vision par ordinateur. Il reste à être un domaine de premier plan dans l'intelligence artificielle. Le traitement d'image se concentre sur l'amélioration des images ; La technologie Computer Vision se concentre sur des analyses détaillées et précises pour créer de meilleurs systèmes.
Pourquoi le Deep Learning est-il utilisé pour construire des algorithmes de Computer Vision ?
La vision par ordinateur a rendu l'intelligence artificielle (IA) plus robuste grâce à une recherche rigoureuse axée sur les données et à une analyse cohérente des données visuelles. Le Deep Learning est un processus continu d'entrée de données via des réseaux de neurones. Les informations sont dérivées des processus du cerveau humain pour perfectionner l'algorithme pour un apprentissage, un traitement et une sortie efficaces. L'apprentissage en profondeur améliore la classification précise des données et garantit un modèle d'IA fiable. Computer Vision utilise cette méthode pour aligner l'IA sur le réseau neuronal du cerveau humain. L'apprentissage en profondeur a permis à des systèmes fiables d'aider les humains et d'améliorer leur qualité de vie.
Qu'est-ce qu'un filtre passe-bas et un filtre passe-haut ?
Dans les algorithmes de vision par ordinateur, plusieurs filtres produisent les résultats souhaités à partir d'une image brute. Ces filtres remplissent de nombreuses fonctions pour lisser, accentuer et accentuer l'apparence souhaitée. Les filtres diffèrent par leur fréquence et proposent des effets différents. Par exemple, le filtre Gaussian Blur fonctionne essentiellement sur le lissage de l'image en modifiant les parties haute fréquence de l'image et en préservant les bords. C'est ce qu'on appelle un filtre passe-bas car il diminue les emplacements à haute fréquence et maintient les emplacements à basse fréquence, ce qui lui donne un visuel plus fluide. Dans les filtres passe-haut, les emplacements basse fréquence sont diminués et les premiers préservés, ce qui se traduit par un visuel plus net.