
Algoritmos de visión artificial: todo lo que quería saber [2022]
Publicado: 2021-01-01Conozca los algoritmos que permiten a las computadoras percibir
Tabla de contenido
Introducción
La palabra visión por computadora significa la capacidad de una computadora para ver y percibir el entorno. Se pueden aplicar muchas aplicaciones para que la visión por computadora cubra: detección y reconocimiento de objetos, autos sin conductor, reconocimiento facial, seguimiento de pelotas, etiquetado de fotos y muchos más. Antes de sumergirse en la jerga técnica, primero analicemos todo el proceso de visión por computadora.
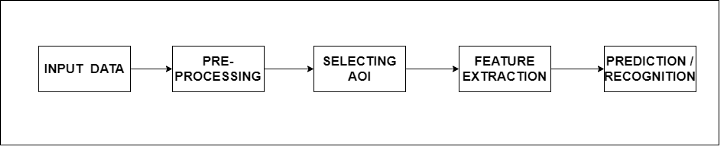
Todo el pipeline se divide en 5 pasos básicos, cada uno con una función específica. En primer lugar, se necesita la entrada para que el algoritmo procese, que puede tener la forma de una imagen o flujo de imágenes (fotogramas de imágenes). El siguiente paso es el preprocesamiento. En este paso, se aplican funciones a las imágenes entrantes para que el algoritmo pueda comprender mejor la imagen.
Algunas de las funciones implican reducción de ruido, escalado de imagen, dilatación y erosión, eliminación de manchas de color, etc. El siguiente paso es seleccionar el área de interés o la región de interés. Debajo de esto se encuentran los algoritmos de detección de objetos y segmentación de imágenes. Además, tenemos la extracción de características que significa recuperar información/características relevantes de las imágenes que son necesarias para lograr el objetivo final.
El paso final es el reconocimiento o la predicción, donde reconocemos objetos en un cuadro de imágenes dado o predecimos la probabilidad del objeto en un cuadro de imagen dado.
Ejemplo
Veamos una aplicación del mundo real de la tubería de visión por computadora. El reconocimiento de expresiones faciales es una aplicación de visión por computadora que utilizan muchos laboratorios de investigación para tener una idea del efecto que tiene un producto en particular en sus usuarios. Nuevamente, tenemos datos de entrada a los que aplicamos los algoritmos de preprocesamiento.

El siguiente paso consiste en detectar caras en un marco particular y recortar esa parte del marco. Una vez que se logra esto, se identifican los puntos de referencia faciales como la boca, los ojos, la nariz, etc., características clave para el reconocimiento de emociones.

Al final, un modelo de predicción (modelo entrenado) clasifica las imágenes en función de las características extraídas en los pasos intermedios.
Algoritmos
Antes de comenzar a mencionar los algoritmos en visión por computadora, quiero enfatizar el término 'Frecuencia'. La frecuencia de una imagen es la tasa de cambio de intensidad. Las imágenes de alta frecuencia tienen grandes cambios de intensidad. Una imagen de baja frecuencia tiene un brillo relativamente uniforme o la intensidad cambia lentamente.
Al aplicar la transformada de Fourier a una imagen obtenemos un espectro de magnitud que nos da la información de la frecuencia de la imagen. El punto concentrado en el centro de la imagen de dominio de frecuencia significa que hay muchos componentes de baja frecuencia presentes en la imagen. Los componentes de alta frecuencia incluyen: bordes, esquinas, rayas, etc. Sabemos que una imagen es una función de x y yf(x,y). Para medir el cambio de intensidad, simplemente tomamos la derivada de la función f(x,y).
Filtro sobrio
El operador de Sobel se utiliza en procesamiento de imágenes y visión por computadora para algoritmos de detección de bordes. El filtro crea una imagen de bordes enfatizados. Calcula una aproximación de la pendiente/gradiente de la función de intensidad de la imagen. En cada píxel de la imagen, la salida del operador de Sobel es tanto el vector de gradiente correspondiente como la norma de este vector.
El Operador de Sobel convoluciona la imagen con un pequeño filtro de valor entero en las direcciones horizontal y vertical. Esto hace que el operador sea económico en términos de complejidad de cálculo. El filtro Sx detecta bordes en dirección horizontal y el filtro Sy detecta bordes en dirección vertical. Es un filtro de paso alto.
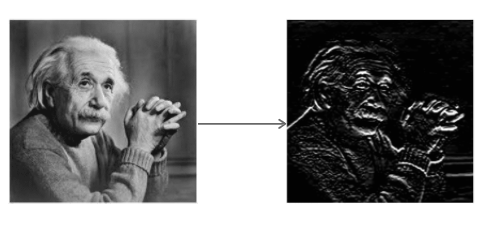
Aplicando Sx a la imagen
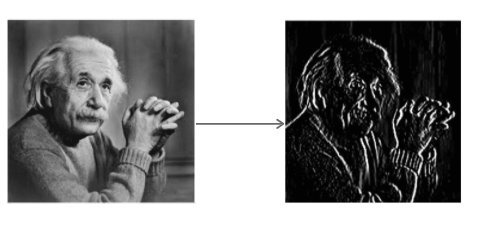
Aplicando Sy a la imagen
Leer: Salario de aprendizaje automático en India
Filtro promedio
El filtro promedio es un filtro normalizado que se utiliza para determinar el brillo o la oscuridad de una imagen. El filtro promedio se mueve a través de la imagen píxel por píxel reemplazando cada valor en el píxel con el valor promedio de los píxeles vecinos, incluido él mismo.
El filtrado Promedio (o promedio) suaviza las imágenes al reducir la cantidad de variación en la intensidad entre los píxeles vecinos.
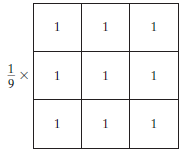
Filtro promedio, fuente de imagen
Filtro de desenfoque gaussiano
El filtro de desenfoque gaussiano es un filtro de paso bajo y tiene las siguientes funciones:
- Suaviza una imagen
- Bloquea partes de alta frecuencia de una imagen
- Conserva los bordes
Matemáticamente, al aplicar un desenfoque gaussiano a una imagen, básicamente estamos convolucionando la imagen con una función gaussiana.

En la fórmula anterior, x es la distancia horizontal desde el punto de origen, y es la distancia vertical desde el punto de origen y σ es la desviación estándar de la distribución gaussiana. En dos dimensiones, la fórmula representa una superficie cuyos perfiles son círculos concéntricos con una distribución gaussiana desde el punto de origen.
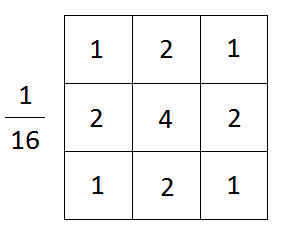

Filtro de desenfoque gaussiano, fuente de imagen
Una cosa a tener en cuenta aquí es la importancia de elegir un tamaño de kernel correcto. Es importante porque si la dimensión del kernel es demasiado grande, las pequeñas características presentes en la imagen pueden desaparecer y la imagen se verá borrosa. Si es demasiado pequeño, no se eliminará el ruido de la imagen.
Lea también: Tipos de algoritmos de IA que debe conocer
Detector de borde astuto
Es un algoritmo que hace uso de cuatro filtros para detectar bordes horizontales, verticales y diagonales en la imagen borrosa. El algoritmo realiza las siguientes funciones.
- Es un algoritmo de detección de bordes preciso ampliamente utilizado.
- Filtra el ruido usando Gaussian Blur
- Encuentra la fuerza y la dirección de los bordes usando el filtro Sobel
- Aplica supresión no máxima para aislar los bordes más fuertes y reducirlos a una línea de un píxel
- Utiliza histéresis (método de doble umbral) para aislar los mejores bordes
Detector Canny Edge en una foto de máquina de vapor, Imagen de Wikipedia
Cascada Haar
Este es un enfoque basado en el aprendizaje automático en el que se entrena una función en cascada para resolver problemas de clasificación binaria. La función se entrena a partir de una plétora de imágenes positivas y negativas y se utiliza además para detectar objetos en otras imágenes. Detecta lo siguiente:
- Bordes
- Líneas
- Patrones rectangulares
Para detectar los patrones anteriores, se utilizan las siguientes funciones:
Capas convolucionales
En este enfoque, la red neuronal aprende las características de un grupo de imágenes que pertenecen a la misma categoría. El aprendizaje se lleva a cabo mediante la actualización de los pesos de las neuronas utilizando la técnica de retropropagación y descenso de gradiente como optimizador.
Es un proceso iterativo que tiene como objetivo disminuir el error entre la salida real y la verdad del terreno. Las capas/bloques de convolución así obtenidos en el proceso actúan como capas de características que se utilizan para distinguir una imagen positiva de una negativa. A continuación se muestra un ejemplo de una capa de convolución.
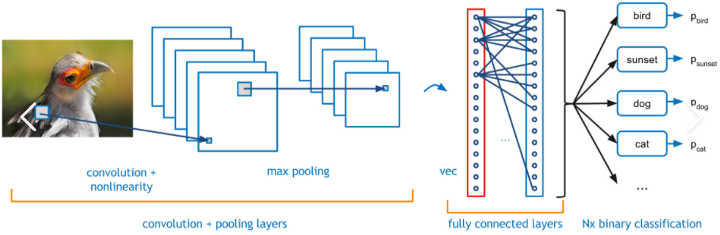
Red neuronal convolucional, fuente de imagen
Las capas totalmente conectadas junto con una función SoftMax al final clasifican la imagen entrante en una de las categorías en las que está entrenada. La puntuación de salida es una puntuación probabilística con un rango de 0 a 1.
Debe leer: Tipos de algoritmo de clasificación en ML
Conclusión
En este blog se ha cubierto una descripción general de los algoritmos más comunes utilizados en Computer Vision junto con una canalización general. Estos algoritmos forman la base de algoritmos más complicados como SIFT, SURF, ORB y muchos más.
Si está interesado en obtener más información sobre el aprendizaje automático, consulte el Diploma PG en aprendizaje automático e IA de IIIT-B y upGrad, que está diseñado para profesionales que trabajan y ofrece más de 450 horas de capacitación rigurosa, más de 30 estudios de casos y asignaciones, IIIT- B Estado de exalumno, más de 5 proyectos prácticos finales prácticos y asistencia laboral con las mejores empresas.
¿Cuál es la diferencia entre procesamiento de imágenes y visión artificial?
El procesamiento de imágenes mejora la forma original de las imágenes para producir una mejor versión. También se utiliza para extraer algunas características de la imagen principal. El procesamiento de imágenes es, por lo tanto, una sección distinta en el propio campo de la visión artificial. Sin embargo, Computer Vision se enfoca en reconocer objetos de estímulo para una clasificación precisa. Ambos también utilizan tecnologías similares en su procedimiento. Por lo tanto, el procesamiento de imágenes puede ser el proceso principal en Computer Vision. Queda por ser un campo destacado en Inteligencia Artificial. El procesamiento de imágenes se enfoca en mejorar las imágenes; La tecnología Computer Vision se centra en análisis detallados y precisos para crear mejores sistemas.
¿Por qué se utiliza Deep Learning para construir algoritmos de visión artificial?
Computer Vision ha hecho que la Inteligencia Artificial (IA) sea más sólida debido a una investigación rigurosa basada en datos y un análisis de datos visuales consistente. Deep Learning es un proceso continuo de entrada de datos a través de redes neuronales. La información se deriva de los procesos del cerebro humano para perfeccionar el algoritmo para un aprendizaje, procesamiento y salida eficientes. El aprendizaje profundo mejora la clasificación precisa de los datos y garantiza un modelo de IA fiable. Computer Vision utiliza este método para alinear la IA con la red neuronal del cerebro humano. Deep Learning ha permitido sistemas confiables para ayudar a los humanos y mejorar su calidad de vida.
¿Qué es un filtro de paso bajo y un filtro de paso alto?
En los algoritmos de visión artificial, varios filtros producen los resultados deseados a partir de una imagen sin procesar. Estos filtros realizan numerosas funciones para suavizar, agudizar y acentuar la apariencia según se desee. Los filtros difieren en su frecuencia y proponen diferentes efectos. Por ejemplo, el filtro de desenfoque gaussiano funciona esencialmente para suavizar la imagen alterando las partes de alta frecuencia de la imagen y conservando los bordes. Se llama filtro de paso bajo porque disminuye las ubicaciones de alta frecuencia y mantiene las ubicaciones de baja frecuencia, lo que le da una imagen más suave. En los filtros de paso alto, las ubicaciones de baja frecuencia se reducen y las primeras se conservan, lo que da como resultado una imagen más nítida.