
Kompletny przewodnik po głębokim uczeniu z siecią neuronową w 2022 r.
Opublikowany: 2021-01-03W głębokim uczeniu się z Keras nie musisz dużo kodować, ale jest kilka kroków, po których musisz przejść powoli, aby w niedalekiej przyszłości móc tworzyć swoje modele. Proces modelowania polega na załadowaniu danych, zdefiniowaniu modelu Keras, skompilowaniu modelu Keras, dopasowaniu modelu Keras, ocenie go, powiązaniu wszystkiego razem i przygotowaniu prognoz.
Ale czasami może się to wydawać mylące, ponieważ nie masz dobrej znajomości podstaw głębokiego uczenia się. Przed rozpoczęciem nowego głębokiego uczenia się z projektem Keras , koniecznie zapoznaj się z tym ostatecznym przewodnikiem, który pomoże ci zweryfikować podstawy głębokiego uczenia się z Keras .
W dziedzinie sztucznej inteligencji głębokie uczenie stało się modnym hasłem, które zawsze znajduje zastosowanie w różnych rozmowach. Jeśli chodzi o przekazywanie inteligencji maszynom, od wielu lat korzystamy z uczenia maszynowego (ML).
Ale biorąc pod uwagę obecny okres, ze względu na przewagę w przewidywaniach, głębokie uczenie się z Keras stało się bardziej lubiane i sławne w porównaniu ze starymi i tradycyjnymi technikami uczenia maszynowego.
Spis treści
Głęboka nauka
Uczenie maszynowe ma podzbiór, w którym sztuczne sieci neuronowe (ANN) są szkolone przy użyciu dużej ilości danych. Ten podzbiór to nic innego jak głębokie uczenie się. Ponieważ algorytm głębokiego uczenia się uczy się na podstawie doświadczenia, wykonuje zadanie wielokrotnie; za każdym razem trochę go poprawia, mając na celu poprawę wyniku.
Nazywa się to „głębokim uczeniem”, ponieważ sieci neuronowe mają wiele głębokich warstw, które umożliwiają uczenie się. Głębokie uczenie się może rozwiązać każdy problem, w którym potrzebne jest myślenie, aby go rozwiązać.

Przeczytaj: Najlepsze techniki głębokiego uczenia
Keras
Dostępnych jest wiele interfejsów API, struktur i bibliotek umożliwiających rozpoczęcie pracy z głębokim uczeniem. Ale oto dlaczego głębokie uczenie się z Keras jest korzystne . Keras to wysokopoziomowy interfejs programowania aplikacji sieci neuronowej (API), który działa na szczycie TensorFlow – która jest kompleksową platformą uczenia maszynowego i jest open-source. Nie tylko Tensorflow, ale także CNTK, Theano, PlaidML itp.
Pomaga w utowarowieniu sztucznej inteligencji (AI) i głębokiego uczenia się. Kodowanie w Keras jest przenośne, co oznacza, że przy użyciu Keras można zaimplementować sieć neuronową, używając Theano jako backendu, a następnie uruchomić ją na Tensorflow, określając backend. Co więcej, nie jest to raczej obowiązkowe, wcale nie jest potrzebne do zmiany kodu.
Jeśli zastanawiasz się, dlaczego głębokie uczenie jest ważnym terminem w sztucznej inteligencji lub masz słabą motywację do rozpoczęcia uczenia się głębokiego z Keras , to zdjęcie trendów Google pokazuje, jak zainteresowanie ludzi uczeniem głębokim stale rośnie na całym świecie w ciągu ostatnich kilku lat.
Istnieje wiele obszarów, takich jak przetwarzanie języka naturalnego (NLP), widzenie komputerowe, rozpoznawanie mowy, projektowanie leków, bioinformatyka itp., w których z powodzeniem zastosowano uczenie głębokie.

Głębokie uczenie się z Keras
Jak wspomniano wcześniej, w głębokim uczeniu sztuczne sieci neuronowe są szkolone przy użyciu dużej ilości danych. Po przeszkoleniu prognozy dotyczące niewidocznych danych mogą być łatwo wykorzystywane przez sieć. Poniżej podano kilka ważnych terminów zwykle używanych w szkoleniu sieci neuronowej wymaganej w głębokim uczeniu się z Keras .
Przeczytaj także: 15 ciekawych pomysłów na projekty uczenia maszynowego dla początkujących
Sieci neuronowe
To właśnie sieci neuronowe w naszym mózgu dały początek idei sztucznych sieci neuronowych. Zwykle sieć neuronowa składa się z trzech warstw. Te trzy warstwy to – warstwa wejściowa, warstwa wyjściowa i warstwa ukryta. Przykład sieci neuronowej pokazano na poniższym rysunku.

Ponieważ sieć neuronowa pokazana powyżej składa się tylko z jednej warstwy ukrytej, jest określana jako „płytka sieć neuronowa”. W takich architekturach dodawanych jest więcej ukrytych warstw, aby tworzyć bardziej złożone architektury.
Głębokie sieci
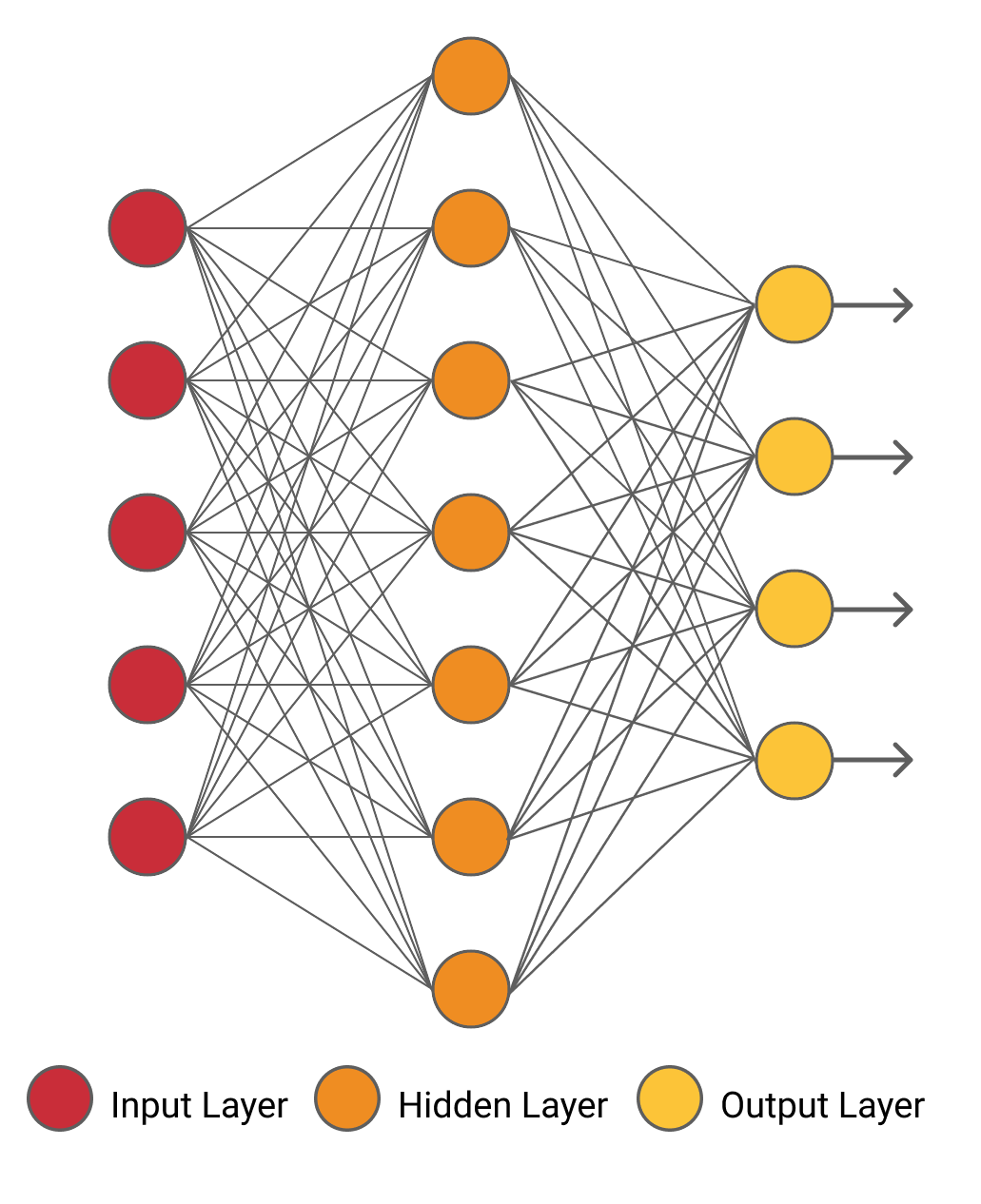
W głębokiej sieci dodano wiele ukrytych warstw. Gdy w sieci wzrasta liczba warstw ukrytych, uczenie takich architektur staje się skomplikowane nie tylko pod względem czasu potrzebnego na pełne przeszkolenie sieci, ale także wymaga większych zasobów. Poniżej podano głęboką sieć, która składa się z wejścia, czterech ukrytych warstw i wyjścia.

Szkolenie sieciowe
Po zdefiniowaniu architektury sieci wymaga ona przeszkolenia w zakresie określonych rodzajów prognoz. W procesie uczenia sieci odpowiednie wagi dla każdego łącza są znajdowane dla sieci.
Podczas szkolenia dane przepływają w standardowym kierunku, czyli od warstwy wejściowej do warstwy wyjściowej i przechodzą przez wiele warstw ukrytych. Sieć ta nazywana jest siecią Feed-Forward Network, ponieważ dane zawsze przepływają w jednym kierunku, czyli od warstwy wejściowej do warstwy wyjściowej. Propagacja danych nazywa się tutaj propagacją do przodu.
Funkcja aktywacji
Na jednej i wszystkich warstwach należy obliczyć ważoną sumę danych wejściowych i przekazać ją do funkcji aktywacji. Ta funkcja aktywacji sprawia, że sieć jest nieliniowa. Jest to po prostu funkcja matematyczna, która pobiera dane wyjściowe i dyskretyzuje je. Niewiele z najczęściej używanych funkcji aktywacji to hiperboliczne, sigmoidalne, styczne (tanh), Softmax i ReLU.
Propagacja wsteczna
W propagacji wstecznej propagacja błędów odbywa się w kierunku wstecznym, czyli od wyjścia do warstwy wejściowej. W uczeniu nadzorowanym propagacja wsteczna jest algorytmem. Dla danej funkcji błędu obliczany jest gradient funkcji błędu w odniesieniu do przypisanej wagi przy każdym połączeniu.
Przez sieć nawet obliczanie gradientu odbywa się w kierunku wstecznym. Gradient masy ostatniej warstwy jest obliczany jako pierwszy, a gradient masy pierwszej warstwy jest obliczany jako ostatni.
W każdej warstwie, określając gradient dla poprzedniej warstwy, ponownie wykorzystuje częściowe obliczenia gradientu. To nic innego jak „Gradient Descent”.
Definiowanie modelu w głębokim uczeniu z Keras
Definiowanie modelu w głębokim uczeniu się można podzielić na kilka cech:
- Liczba warstw.
- Rodzaje warstw.
- Liczba neuronów w każdej warstwie.
- Funkcja aktywacji każdej warstwy.
- Rozmiar wejściowy i rozmiar wyjściowy.
Przeczytaj: Regularyzacja w głębokim uczeniu
Dolna linia
Nauka głębokiego uczenia się z Keras jest niezbędna, ponieważ Keras jest łatwą w użyciu i potężną biblioteką open source i bezpłatną biblioteką Pythona do oceny i opracowywania modeli głębokiego uczenia się. Keras zawiera również szeroko stosowane biblioteki do obliczeń numerycznych, takie jak TensorFlow i Theano, które pozwalają trenować, a także definiować modele sieci neuronowych za pomocą zaledwie kilku linijek kodu programistycznego.
Po zainstalowaniu i skonfigurowaniu Pythona 2 lub 3 wszystko jest gotowe do rozpoczęcia głębokiego uczenia się z projektem Keras. Wystarczy dodać zainstalowany i skonfigurowany SciPy, w tym NumPy i mieć zainstalowany i skonfigurowany Keras z backendem TensorFlow lub Theano.
Jeśli chcesz dowiedzieć się więcej o technikach głębokiego uczenia się, uczeniu maszynowym, sprawdź dyplom PG IIIT-B i upGrad w uczeniu maszynowym i sztucznej inteligencji, który jest przeznaczony dla pracujących profesjonalistów i oferuje ponad 450 godzin rygorystycznego szkolenia, ponad 30 studiów przypadków i zadania, status absolwentów IIIT-B, ponad 5 praktycznych praktycznych projektów zwieńczenia i pomoc w pracy z najlepszymi firmami.